
Maison >Java >javaDidacticiel >Introduction à l'utilisation du framework Java
Introduction à l'utilisation du framework Java
- 巴扎黑original
- 2017-07-18 15:45:503248parcourir
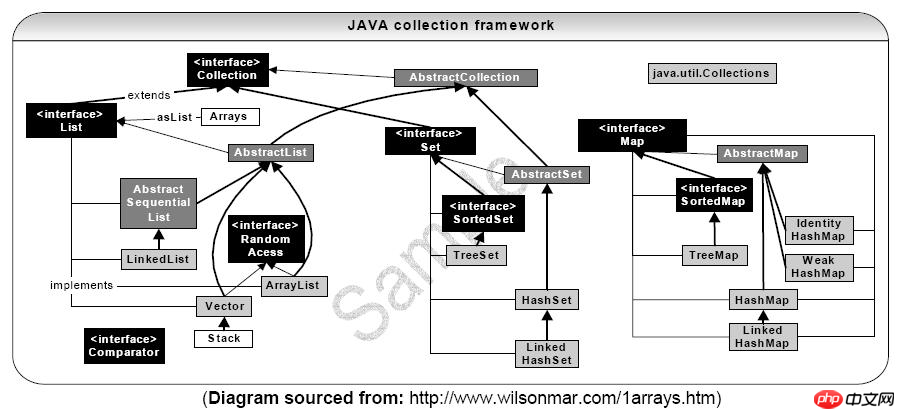
Interface de collection
La collection est l'interface de collection la plus basique. Une collection représente un groupe d'objets, c'est-à-dire. , les éléments de la collection.
Toutes les classes qui implémentent l'interface Collection doivent fournir deux constructeurs standards : un constructeur sans paramètre pour créer une collection vide et un constructeur de paramètres de collection pour créer une nouvelle collection qui a les mêmes éléments que la collection passée. Ce dernier constructeur permet à l'utilisateur de copier une collection.
Comment parcourir chaque élément dans Collection ? Quel que soit le type réel de Collection, il prend en charge une méthode iterator(), qui renvoie un itérateur. Vous pouvez utiliser cet itérateur pour parcourir et accéder à chaque élément de la Collection Le parcours via Iterator est inutile. .
L'utilisation typique est la suivante :
1 Iterator it = collection.iterator(); // 获得一个迭代子2 while(it.hasNext()) {3 Object obj = it.next(); // 得到下一个元素4 }Interface de liste
La liste est une collection ordonnée Utilisez cette interface pour contrôler avec précision la position d'insertion de chaque élément. Les utilisateurs peuvent accéder aux éléments de la liste à l'aide de l'index (la position de l'élément dans la liste, similaire à un indice de tableau), qui est similaire au tableau de Java.
En plus de la méthode iterator() nécessaire à l'interface Collection, List fournit également une méthode listIterator(), qui renvoie une interface ListIterator. Par rapport à l'interface Iterator standard, ListIterator a. plus Certaines méthodes telles que add() permettent d'ajouter, de supprimer, de définir des éléments et de parcourir en avant ou en arrière.
Les classes courantes qui implémentent l'interface List sont LinkedList, ArrayList, Vector et Stack.
Classe LinkedList
LinkedList implémente l'interface List, autorisant les éléments nuls. De plus, LinkedList fournit des méthodes supplémentaires d'obtention, de suppression et d'insertion. Ces opérations permettent à LinkedList d'être utilisée comme pile, file d'attente ou deque.
Notez que LinkedList n'a pas de synchronicité . Si plusieurs threads accèdent à une LinkedList en même temps, vous devez implémenter vous-même la synchronisation des accès. Une autre solution consiste à construire une liste synchronisée lors de la création de la liste : List list = Collections.synchronizedList(new LinkedList(...));
ArrayList class
ArrayList implémente un tableau de taille variable. Il autorise tous les éléments, y compris null. ArrayList n'a pas de synchronicité.
size, isEmpty, get, set le temps d'exécution de la méthode est constant. Cependant, le coût de la méthode add est une constante amortie et l’ajout de n éléments nécessite un temps O(n). D'autres méthodes ont une durée d'exécution linéaire.
Chaque instance d'ArrayList a une capacité (Capacity), qui est la taille du tableau utilisé pour stocker les éléments. Cette capacité augmente automatiquement à mesure que de nouveaux éléments sont ajoutés, mais l'algorithme de croissance n'est pas défini. Lorsqu'un grand nombre d'éléments doivent être insérés, la méthode EnsureCapacity peut être appelée pour augmenter la capacité de l'ArrayList avant l'insertion afin d'améliorer l'efficacité de l'insertion.
Classe Vector
Vector est très similaire à ArrayList, mais Vector est synchronisé. Bien que l'itérateur créé par Vector ait la même interface que l'itérateur créé par ArrayList, étant donné que Vector est synchronisé, lorsqu'un itérateur est créé et utilisé, un autre thread modifie l'état du vecteur (par exemple, en ajoutant ou en supprimant un élément). , ConcurrentModificationException sera levée lors de l'appel de la méthode Iterator, l'exception doit donc être interceptée.
Classe Stack
Stack hérite de Vector et implémente une pile dernier entré, premier sorti. Stack fournit 5 méthodes supplémentaires qui permettent d'utiliser Vector comme pile. Les méthodes de base push et pop, ainsi que la méthode peek, placent l'élément en haut de la pile, la méthode vide teste si la pile est vide et la méthode de recherche détecte la position d'un élément dans la pile. La pile est une pile vide après sa création.
Comparaison de Vector, ArrayList et LinkedList
1 Vector est synchronisé avec les threads, il est donc également thread-safe, tandis qu'ArrayList et LinkedList. ne sont pas thread-safe. Si les facteurs de sécurité des threads ne sont pas pris en compte, il est généralement plus efficace d'utiliser ArrayList et LinkedList.
2. ArrayList et Vector implémentent des structures de données basées sur des tableaux dynamiques, et LinkedList est basé sur des structures de données de liste chaînée.
3. Si le nombre d'éléments dans la collection est supérieur à la longueur du tableau de collection actuel, le taux de croissance du vecteur est de 100 % de la longueur actuelle du tableau et la croissance de l'ArrayList rate est de 50 % de la longueur actuelle du tableau %. Si vous utilisez une quantité relativement importante de données dans la collection, l'utilisation de vector présente certains avantages, sinon l'utilisation de ArrayList présente des avantages.
3. Si trouve des données à un emplacement spécifié, le temps utilisé par Vector et ArrayList est le même et le temps passé est O(1), tandis que LinkedList doit être parcouru. La recherche prend un temps O(i) et n'est pas aussi efficace que les deux premiers.
4. Si déplacer ou supprimer des données à un emplacement spécifié prend 0(n-i) n est la longueur totale, vous devriez envisager d'utiliser LinkedList à ce moment-là, car le temps nécessaire pour déplacer les données à un emplacement spécifié est 0(1).
5. Pour insérer des données à l'emplacement spécifié , LinedList a l'avantage car ArrayList doit déplacer les données.
Interface de l'ensemble
L'ensemble est une collection qui ne contient pas d'éléments en double. Autrement dit, deux éléments e1 et e2 ont e1.equals(e2)=false et Set a au plus un élément nul.
De toute évidence, le constructeur Set a une contrainte selon laquelle le paramètre Collection transmis ne peut pas contenir d'éléments en double.
Veuillez noter : les objets mutables doivent être manipulés avec soin. Si un élément mutable dans un Set change d'état, provoquant Object.equals(Object)=true, cela entraînera des problèmes.
Interface de la carte
Veuillez noter que Map n'hérite pas de l'interface Collection, Map fournit la clé pour cartographie des valeurs. Une Map ne peut pas contenir la même clé et chaque clé ne peut être mappée qu’à une seule valeur.
L'interface Map propose trois types de vues d'ensemble. Le contenu de la carte peut être considéré comme un ensemble d'ensembles de clés, un ensemble d'ensembles de valeurs ou un ensemble de mappages clé-valeur.
Classe Hashtable
Hashtable hérite de l'interface Map et implémente un mappage clé-valeur Table de hachage. Tout objet non nul peut être utilisé comme clé ou valeur.
Pour ajouter des données, utilisez put(key, value), et pour supprimer des données, utilisez get(key). Le coût en temps de ces deux opérations de base est constant.
Hashtable ajuste les performances via deux paramètres : la capacité initiale et le facteur de charge. Habituellement, le facteur de charge par défaut de 0,75 permet d'obtenir un meilleur équilibre entre le temps et l'espace. L'augmentation du facteur de charge peut économiser de l'espace, mais le temps de recherche correspondant augmentera, ce qui affectera les opérations telles que l'extraction et la mise en place.
Étant donné que l'objet utilisé comme clé déterminera la position de la valeur correspondante en calculant sa fonction de hachage, tout objet utilisé comme clé doit implémenter les méthodes hashCode et égal à. Les méthodes hashCode et equals sont héritées de la classe racine Object.
Hashtable est synchrone.
Classe HashMap
HashMap est similaire à Hashtable, sauf que HashMap est asynchrone et Null est autorisé, c'est-à-dire valeur nulle et clé nulle. Cependant, lorsque l'on traite HashMap comme une collection (la méthode values() peut renvoyer une collection), la surcharge temporelle de ses sous-opérations d'itération est proportionnelle à la capacité de HashMap. Par conséquent, si les performances des opérations itératives sont très importantes, ne définissez pas la capacité initiale de HashMap trop élevée ni le facteur de charge trop bas.
Classe TreeMap
HashMap utilise le hashcode pour rechercher rapidement son contenu, de manière non ordonnée et ; tous les éléments de TreeMap maintiennent un certain ordre fixe et sont ordonnés.
HashMap est le meilleur choix pour insérer, supprimer et positionner des éléments dans Map. Mais si vous souhaitez parcourir les clés dans un ordre naturel ou personnalisé, TreeMap sera meilleur. L'utilisation de HashMap nécessite que la classe de clé ajoutée définisse clairement l'implémentation de hashCode() et equals().
TreeMap n'a aucune option de réglage car l'arbre est toujours dans un état équilibré.
Classe WeakHashMap
WeakHashMap est un HashMap amélioré, qui implémente une « référence faible » pour la clé If If a. la clé n'est plus référencée en externe, la clé peut être recyclée par GC.
Résumé
Si des opérations impliquant des piles, des files d'attente, etc. sont impliquées, vous devrait envisager d'utiliser List ; Si vous devez insérer et supprimer rapidement des éléments, vous devez utiliser LinkedList ; si vous devez accéder rapidement à des éléments de manière aléatoire, vous devez utiliser ArrayList ;
Si le programme est dans un environnement à thread unique, ou si l'accès n'est effectué que dans un seul thread, envisagez les classes asynchrones, qui sont plus efficaces si plusieurs threads peuvent faire fonctionner une classe en même temps ; en même temps, des classes synchronisées doivent être utilisées.
Portez une attention particulière au fonctionnement de la table de hachage. Les méthodes equals et hashCode doivent être correctement remplacées en tant qu'objet clé.
Lors de l'utilisation de Map, il est préférable d'utiliser HashMap ou HashTable pour rechercher, mettre à jour, supprimer et ajouter ; lorsque vous parcourez Map dans l'ordre naturel ou dans l'ordre des clés personnalisées, il est préférable d'utiliser ; TreeMap;
Essayez de renvoyer l'interface plutôt que le type réel, par exemple en renvoyant List au lieu de ArrayList, de sorte que si ArrayList doit être remplacé par LinkedList à l'avenir, le code client n'a pas besoin de changer. C'est de la programmation pour l'abstraction.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!