
Maison >développement back-end >Tutoriel Python >Python : comment Pandas fonctionne efficacement
Python : comment Pandas fonctionne efficacement
- 巴扎黑original
- 2017-07-19 13:38:561390parcourir
Cet article effectue un test comparatif sur l'efficacité opérationnelle des Pandas pour explorer quelles méthodes peuvent améliorer l'efficacité opérationnelle.
L'environnement de test est le suivant :
windows 7, 64 bits
python 3.5
- Obligatoire Il convient de noter que différents systèmes, différentes configurations informatiques et différents environnements logiciels peuvent avoir des résultats de fonctionnement différents. Même s’il s’agit du même ordinateur, les résultats ne seront pas exactement les mêmes à chaque exécution. 1 Contenu du test
- Le contenu du test consiste à utiliser trois méthodes pour calculer un processus d'opération simple, à savoir a*a+b*b. Les trois méthodes sont :
- La boucle for de Python
Ndarray de Numpy
- Construisez d'abord un DataFrame. La taille de la quantité de données, c'est-à-dire le nombre de lignes du DataFrame, est de 10, 100, 1000, ... , jusqu'à 10 000 000 (un million). Ensuite, dans le notebook jupyter, utilisez les codes suivants pour tester respectivement afin de vérifier le temps d'exécution des différentes méthodes et faire une comparaison.
- Effectuer l'opération, a*a + b*b
Méthode 1 : boucle for
import pandas as pdimport numpy as np# 100分别用 10,100,...,10,000,000来替换运行list_a = list(range(100))# 200分别用 20,200,...,20,000,000来替换运行list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({'a':list_a, 'b':list_b})
print('数据维度为:{}'.format(df.shape))
print(len(df))
print(df.head())
100 100 数据维度为:(100, 2) 100 a b 0 0 100 1 1 101 2 2 102 3 3 103 4 4 104
- Méthode 2 : Série
%%timeit# 当DataFrame的行数大于等于1000000时,请用 %%time 命令for i in range(len(df)): df['a'][i]*df['a'][i]+df['b'][i]*df['b'][i]
100 loops, best of 3: 12.8 ms per loop
Méthode 3 : ndarray
type(df['a'])
pandas.core.series.Series
%%timeit df['a']*df['a']+df['b']*df['b']
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached. 1000 loops, best of 3: 669 µs per loop2 Résultats des tests
- Les résultats d'exécution sont les suivants :
type(df['a'].values)La différence entre Series et ndarray n'est pas si grande.
numpy.ndarray
%%timeit df['a'].values*df['a'].values+df['b'].values*df['b'].valuesPS : Lorsqu'il y a 10 millions de lignes, la boucle for met beaucoup de temps à s'exécuter. Si vous souhaitez la tester, vous devez faire attention. Veuillez utiliser le
10000 loops, best of 3: 34.2 µs per loop%%time commande (tester une seule fois). Le tableau suivant compare les performances entre Series et ndarray.
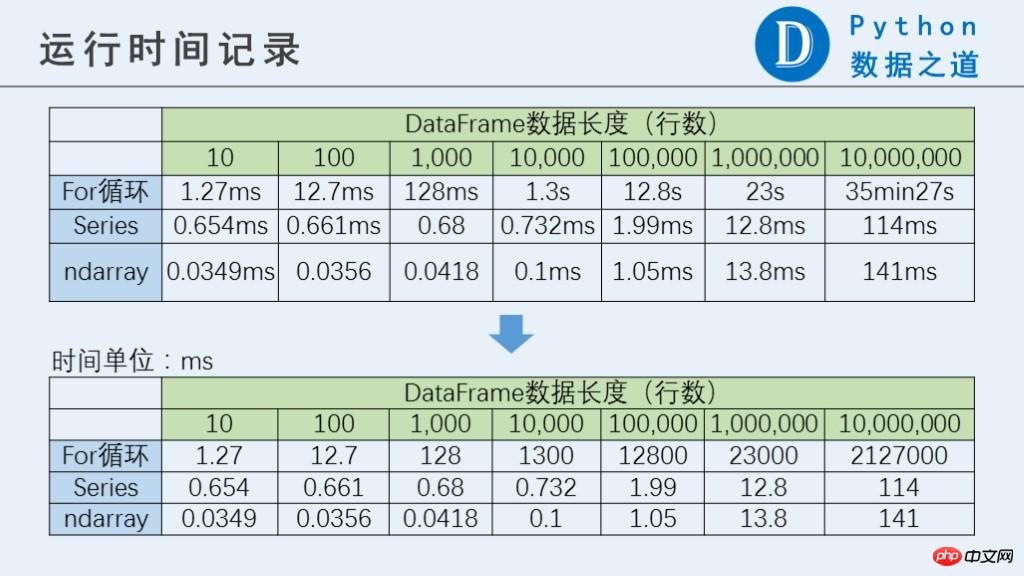
Donc, dans des circonstances normales, je recommande personnellement d'utiliser la boucle for si possible. Lorsque le nombre n'est pas particulièrement grand, il est recommandé d'utiliser ndarray
(c'est-à-dire df['col. '].values) Pour effectuer des calculs, l'efficacité de fonctionnement est relativement meilleure.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Résumé de l'apprentissage de base de Python (8)Article suivant:Résumé de l'apprentissage de base de Python (8)