
Maison >interface Web >js tutoriel >L'analyse du code source de RequireJs révèle comment fonctionne le chargement du script
L'analyse du code source de RequireJs révèle comment fonctionne le chargement du script
- 巴扎黑original
- 2017-07-19 16:28:201637parcourir
Introduction
Comme le dit le proverbe, les programmeurs qui n'aiment pas étudier les principes ne sont pas de bons programmeurs, et les programmeurs qui n'aiment pas lire le code source ne sont pas de bons jser. Au cours des deux derniers jours, j'ai constaté des problèmes liés à la modularisation front-end et j'ai découvert que la communauté JavaScript a travaillé très dur pour l'ingénierie front-end. Aujourd'hui, j'ai étudié la question de la modularisation frontale pendant une journée. Tout d'abord, j'ai brièvement compris les spécifications standard de la modularisation, puis j'ai appris la syntaxe et l'utilisation de RequireJ, et enfin j'ai étudié le modèle de conception et le code source de RequireJ. souhaitez enregistrer l'expérience pertinente, analyser le principe de chargement des modules.
1. Comprendre RequireJs
Avant de commencer, nous devons comprendre la modularisation frontale. Cet article ne traite pas des problèmes liés au front. -end modularisation. Pour des questions à cet égard, vous pouvez vous référer à la série d'articles de Ruan Yifeng Programmation modulaire Javascript.
La première étape pour utiliser RequireJs : Allez sur le site officiel
La deuxième étape : Téléchargez le fichier


Étape 3 : Introduisez requirejs.js dans la page et définissez la fonction principale
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
Ensuite, nous pouvons programmer dans le fichier main.js. requirejs adopte l'idée fonctionnelle principale. Un fichier est un module. Les modules peuvent dépendre les uns des autres, ou ils peuvent le faire. n'a rien à voir avec ça. En utilisant requirejs, nous n'avons pas besoin d'importer tous les modules dans la page lors de la programmation, nous avons plutôt besoin d'un module. L'introduction d'un module équivaut à l'importation en Java.
Définir le module :
1 //直接定义一个对象 2 define({ 3 color: "black", 4 size: "unisize" 5 }); 6 //通过函数返回一个对象,即可以实现 IIFE 7 define(function () { 8 //Do setup work here 9 10 return {11 color: "black",12 size: "unisize"13 }14 });15 //定义有依赖项的模块16 define(["./cart", "./inventory"], function(cart, inventory) {17 //return an object to define the "my/shirt" module.18 return {19 color: "blue",20 size: "large",21 addToCart: function() {22 inventory.decrement(this);23 cart.add(this);24 }25 }26 }27 );Importer le module :
1 //导入一个模块2 require(['foo'], function(foo) {3 //do something4 });5 //导入多个模块6 require(['foo', 'bar'], function(foo, bar) {7 //do something8 });Pour l'utilisation de requirejs, vous pouvez consulter l'API du site officiel, ou vous pouvez vous référer aux spécifications RequireJS et AMD. Cet article n'expliquera pas l'utilisation de requirejs pour le moment. être.
2. Entrée de fonction principaleL'une des idées fondamentales de requirejs est d'utiliser une entrée de fonction spécifiée, tout comme int main() de C++, la fonction public static void main( ) de Java , requirejs est utilisé en mettant en cache la fonction principale dans la balise script. Autrement dit, l'URL du fichier de script est mise en cache dans la balise de script.
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
Quand je suis arrivé devant l'ordinateur pour la première fois, mes camarades de classe l'ont vu, wow ! La balise de script possède-t-elle des attributs inconnus ? J'avais tellement peur que j'ai rapidement ouvert le W3C pour afficher l'API correspondante et j'ai eu honte de mes connaissances de base en HTML. Mais malheureusement, la balise de script n'a pas d'attributs pertinents, et ce n'est même pas un attribut standard. Alors, qu'est-ce que c'est ? Passons directement au code source de requirejs :
1 //Look for a data-main attribute to set main script for the page2 //to load. If it is there, the path to data main becomes the3 //baseUrl, if it is not already set.4 dataMain = script.getAttribute('data-main');En fait, dans requirejs, on récupère juste les données mises en cache sur la balise script, puis on prend Extrayez les données et chargez-les. C'est la même chose que le chargement dynamique de scripts. Comment le faire fonctionner spécifiquement, le code source sera publié dans l'explication ci-dessous.
3. Script de chargement dynamique
Cette partie est le cœur de l'ensemble des requirejs. Nous savons que la façon de charger les modules dans Node. js est synchrone Oui, c'est parce que tous les fichiers côté serveur sont stockés sur le disque dur local et que le taux de transfert est rapide et stable. Si vous passez au navigateur, vous ne pouvez pas le faire, car le script de chargement du navigateur communiquera avec le serveur. Il s'agit d'une requête inconnue. Si vous utilisez une méthode de chargement synchrone, elle peut continuer à être bloquée. Afin d'éviter le blocage du navigateur, nous devons charger le script de manière asynchrone. Comme il est chargé de manière asynchrone, les opérations qui dépendent du module doivent être exécutées après le chargement du script et une fonction de rappel doit être utilisée ici.
On sait que si le fichier script est défini en HTML, l'ordre d'exécution du script est synchrone, comme par exemple :
1 //module1.js2 console.log("module1");1 //module2.js2 console.log("module2");1 //module3.js2 console.log("module3");1 <script type="text/javascript" src="scripts/module/module1.js?1.1.11"></script>2 <script type="text/javascript" src="scripts/module/module2.js?1.1.11"></script>3 <script type="text/javascript" src="scripts/module/module3.js?1.1.11"></script>
那么在浏览器端总是会输出:

但是如果是动态加载脚本的话,脚本的执行顺序是异步的,而且不光是异步的,还是无序的:
1 //main.js 2 console.log("main start"); 3 4 var script1 = document.createElement("script"); 5 script1.src = "scripts/module/module1.js?1.1.11"; 6 document.head.appendChild(script1); 7 8 var script2 = document.createElement("script"); 9 script2.src = "scripts/module/module2.js?1.1.11";10 document.head.appendChild(script2);11 12 var script3 = document.createElement("script");13 script3.src = "scripts/module/module3.js?1.1.11";14 document.head.appendChild(script3);15 16 console.log("main end");使用这种方式加载脚本会造成脚本的无序加载,浏览器按照先来先运行的方法执行脚本,如果 module1.js 文件比较大,那么极其有可能会在 module2.js 和 module3.js 后执行,所以说这也是不可控的。要知道一个程序当中最大的 BUG 就是一个不可控的 BUG ,有时候它可能按顺序执行,有时候它可能乱序,这一定不是我们想要的。
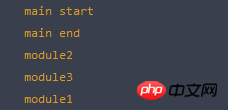
注意这里的还有一个重点是,"module" 的输出永远会在 "main end" 之后。这正是动态加载脚本异步性的特征,因为当前的脚本是一个 task ,而无论其他脚本的加载速度有多快,它都会在 Event Queue 的后面等待调度执行。这里涉及到一个关键的知识 — Event Loop ,如果你还对 JavaScript Event Loop 不了解,那么请先阅读这篇文章 深入理解 JavaScript 事件循环(一)— Event Loop。
四、导入模块原理
在上一小节,我们了解到,使用动态加载脚本的方式会使脚本无序执行,这一定是软件开发的噩梦,想象一下你的模块之间存在上下依赖的关系,而这时候他们的加载顺序是不可控的。动态加载同时也具有异步性,所以在 main.js 脚本文件中根本无法访问到模块文件中的任何变量。那么 requirejs 是如何解决这个问题的呢?我们知道在 requirejs 中,任何文件都是一个模块,一个模块也就是一个文件,包括主模块 main.js,下面我们看一段 requirejs 的源码:
1 /** 2 * Creates the node for the load command. Only used in browser envs. 3 */ 4 req.createNode = function (config, moduleName, url) { 5 var node = config.xhtml ? 6 document.createElementNS('http://www.w3.org/1999/xhtml', 'html:script') : 7 document.createElement('script'); 8 node.type = config.scriptType || 'text/javascript'; 9 node.charset = 'utf-8';10 node.async = true;11 return node;12 };在这段代码中我们可以看出, requirejs 导入模块的方式实际就是创建脚本标签,一切的模块都需要经过这个方法创建。那么 requirejs 又是如何处理异步加载的呢?传说江湖上最高深的医术不是什么灵丹妙药,而是以毒攻毒,requirejs 也深得其精髓,既然动态加载是异步的,那么我也用异步来对付你,使用 onload 事件来处理回调函数:
1 //In the browser so use a script tag 2 node = req.createNode(config, moduleName, url); 3 4 node.setAttribute('data-requirecontext', context.contextName); 5 node.setAttribute('data-requiremodule', moduleName); 6 7 //Set up load listener. Test attachEvent first because IE9 has 8 //a subtle issue in its addEventListener and script onload firings 9 //that do not match the behavior of all other browsers with10 //addEventListener support, which fire the onload event for a11 //script right after the script execution. See:12 //13 //UNFORTUNATELY Opera implements attachEvent but does not follow the script14 //script execution mode.15 if (node.attachEvent &&16 //Check if node.attachEvent is artificially added by custom script or17 //natively supported by browser18 //read 19 //if we can NOT find [native code] then it must NOT natively supported.20 //in IE8, node.attachEvent does not have toString()21 //Note the test for "[native code" with no closing brace, see:22 //23 !(node.attachEvent.toString && node.attachEvent.toString().indexOf('[native code') < 0) &&24 !isOpera) {25 //Probably IE. IE (at least 6-8) do not fire26 //script onload right after executing the script, so27 //we cannot tie the anonymous define call to a name.28 //However, IE reports the script as being in 'interactive'29 //readyState at the time of the define call.30 useInteractive = true;31 32 node.attachEvent('onreadystatechange', context.onScriptLoad);33 //It would be great to add an error handler here to catch34 //404s in IE9+. However, onreadystatechange will fire before35 //the error handler, so that does not help. If addEventListener36 //is used, then IE will fire error before load, but we cannot37 //use that pathway given the connect.microsoft.com issue38 //mentioned above about not doing the 'script execute,39 //then fire the script load event listener before execute40 //next script' that other browsers do.41 //Best hope: IE10 fixes the issues,42 //and then destroys all installs of IE 6-9.43 //node.attachEvent('onerror', context.onScriptError);44 } else {45 node.addEventListener('load', context.onScriptLoad, false);46 node.addEventListener('error', context.onScriptError, false);47 }48 node.src = url;注意在这段源码当中的监听事件,既然动态加载脚本是异步的的,那么干脆使用 onload 事件来处理回调函数,这样就保证了在我们的程序执行前依赖的模块一定会提前加载完成。因为在事件队列里, onload 事件是在脚本加载完成之后触发的,也就是在事件队列里面永远处在依赖模块的后面,例如我们执行:
1 require(["module"], function (module) {2 //do something3 });那么在事件队列里面的相对顺序会是这样:

相信细心的同学可能会注意到了,在源码当中不光光有 onload 事件,同时还添加了一个 onerror 事件,我们在使用 requirejs 的时候也可以定义一个模块加载失败的处理函数,这个函数在底层也就对应了 onerror 事件。同理,其和 onload 事件一样是一个异步的事件,同时也永远发生在模块加载之后。
谈到这里 requirejs 的核心模块思想也就一目了然了,不过其中的过程还远不直这些,博主只是将模块加载的实现思想抛了出来,但 requirejs 的具体实现还要复杂的多,比如我们定义模块的时候可以导入依赖模块,导入模块的时候还可以导入多个依赖,具体的实现方法我就没有深究过了, requirejs 虽然不大,但是源码也是有两千多行的... ...但是只要理解了动态加载脚本的原理过后,其思想也就不难理解了,比如我现在就可以想到一个简单的实现多个模块依赖的方法,使用计数的方式检查模块是否加载完全:
1 function myRequire(deps, callback){ 2 //记录模块加载数量 3 var ready = 0; 4 //创建脚本标签 5 function load (url) { 6 var script = document.createElement("script"); 7 script.type = 'text/javascript'; 8 script.async = true; 9 script.src = url;10 return script;11 }12 var nodes = [];13 for (var i = deps.length - 1; i >= 0; i--) {14 nodes.push(load(deps[i]));15 }16 //加载脚本17 for (var i = nodes.length - 1; i >= 0; i--) {18 nodes[i].addEventListener("load", function(event){19 ready++;20 //如果所有依赖脚本加载完成,则执行回调函数;21 if(ready === nodes.length){22 callback()23 }24 }, false);25 document.head.appendChild(nodes[i]);26 }27 }实验一下是否能够工作:
1 myRequire(["module/module1.js?1.1.11", "module/module2.js?1.1.11", "module/module3.js?1.1.11"], function(){2 console.log("ready!");3 }); 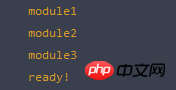
Oui, c'est du travail !
Résumé
L'idée principale du module de chargement requirejs est de profiter de la nature asynchrone des scripts chargés dynamiquement et de l'événement onload pour combattre les virus avec du poison Concernant le chargement des scripts, nous devons faire attention aux points suivants :
L'introduction de la balise
- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript