
Maison >Java >javaDidacticiel >Résumé des classes de collection JAVA
Résumé des classes de collection JAVA
- 巴扎黑original
- 2017-07-20 13:17:111543parcourir
1. Collections et tableaux
Les tableaux (peuvent stocker des types de données de base) sont un conteneur utilisé pour stocker des objets, mais la longueur du tableau est fixe et ne convient pas au nombre d'objets Utilisé lorsqu'il est inconnu.
Les collections (qui ne peuvent stocker que des objets, et les types d'objets peuvent être différents) ont une longueur variable et peuvent être utilisées dans la plupart des situations.
2. Relation hiérarchique
Comme le montre la figure : Dans la figure, la bordure en ligne continue est la classe d'implémentation, la bordure polyligne est la classe abstraite et la bordure en pointillés est C'est l'interface
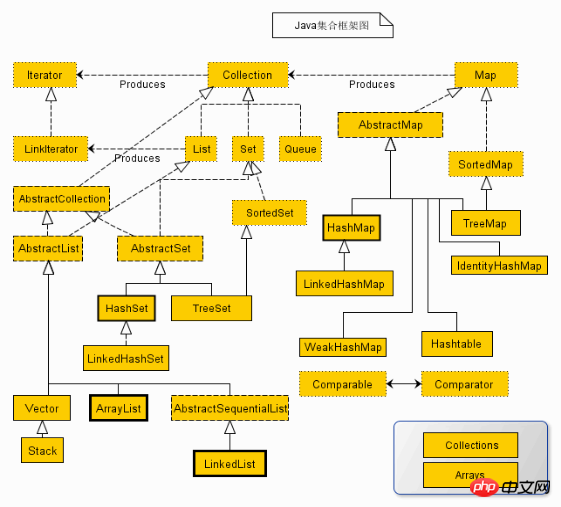
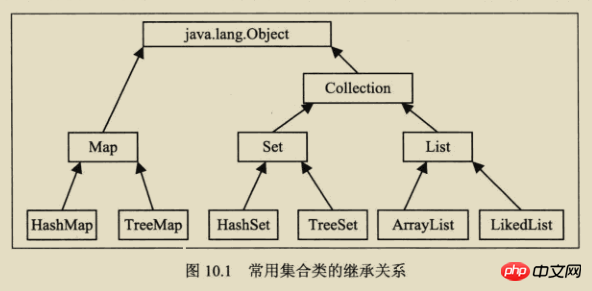
L'interface de collection est l'interface racine de la classe de collection. Il n'y a pas d'interface directe pour cette interface dans la classe d'implémentation Java. Mais il a été hérité pour produire deux interfaces, à savoir Set et List. L'ensemble ne peut pas contenir d'éléments en double. List est une collection ordonnée qui peut contenir des éléments répétés et permet un accès par index.
Map est une autre interface du package Java.util. Elle n'a rien à voir avec l'interface Collection et est indépendante l'une de l'autre, mais elles font toutes deux partie de la classe collection. La carte contient des paires clé-valeur. La carte ne peut pas contenir de clés en double, mais elle peut contenir la même valeur.
Iterator, toutes les classes de collection implémentent l'interface Iterator, qui est une interface utilisée pour parcourir les éléments d'une collection. Elle comprend principalement les trois méthodes suivantes :
1. HasNext() Existe-t-il une autre méthode ? un élément.
2.next() renvoie l'élément suivant.
3.remove() supprime l'élément actuel.
3. Introduction à plusieurs interfaces et classes importantes
1. Liste (ordonnée, répétable)
Les objets stockés dans la liste sont ordonnés, et c'est le cas. également répétable. List se concentre sur les index, dispose d'une série de méthodes liées aux index et a une vitesse de requête rapide. Étant donné que lors de l'insertion ou de la suppression de données dans la collection de listes, cela s'accompagnera du mouvement des données ultérieures, toutes les insertions et suppressions de données sont lentes.
2. Set (non ordonné, ne peut pas être répété)
Les objets stockés dans Set ne sont pas ordonnés et ne peuvent pas être répétés. Les objets de l'ensemble ne sont pas triés d'une manière spécifique, mais les objets sont simplement ajoutés. au milieu.
3. Map (paires clé-valeur, clés uniques, valeurs non uniques)
La collection Map stocke les paires clé-valeur. Les clés ne peuvent pas être répétées, mais les valeurs peuvent être répétées. Obtenez la valeur en fonction de la clé. Lors de la traversée de la collection de cartes, obtenez d'abord la collection définie de la clé, parcourez la collection définie et obtenez la valeur correspondante.
La comparaison est la suivante :
|
Si c'est en ordre | Si les éléments peuvent être répétés | |||||||||||||||||||||||||||||||
| Collection | Non | Oui | |||||||||||||||||||||||||||||||
| Liste | est | est | |||||||||||||||||||||||||||||||
| Ensemble | AbstractSet | Non | Non | ||||||||||||||||||||||||||||||
| HashSet | |||||||||||||||||||||||||||||||||
| TreeSet | Oui (en utilisant un arbre trié binaire) | tr>||||||||||||||||||||||||||||||||
| Carte | AbstractMap | Non | Utiliser une valeur-clé pour mapper et stocker des données, la clé doit être unique et la valeur peut être répétée | ||||||||||||||||||||||||||||||
| HashMap | |||||||||||||||||||||||||||||||||
| TreeMap | est (en utilisant un arbre trié binaire) | ||||||||||||||||||||||||||||||||
4. Traversal
Les quatre méthodes de sortie courantes suivantes sont fournies dans l'ensemble de classes :
1) Itérateur : sortie itérative, Il s’agit de la méthode de sortie la plus couramment utilisée.
2) ListIterator : C'est une sous-interface d'Iterator, spécialement utilisée pour afficher le contenu de List.
3) sortie foreach : une nouvelle fonction fournie après JDK1.5, qui peut générer des tableaux ou des ensembles.
4) boucle for
L'exemple de code est le suivant :
La forme de for : for (int i=0;i Formulaire Foreach : for (int i: arr) {...} Formulaire itérateur : 5. ArrayList et LinkedList Utilisation de ArrayList et LinkedList Il n'y a pas de différence, mais il existe toujours une différence fonctionnelle. LinkedList est souvent utilisé dans des situations où il y a de nombreux ajouts et suppressions mais peu d'opérations de requête, alors qu'ArrayList est le contraire. 6. Collection de cartes Classes d'implémentation : HashMap, Hashtable, LinkedHashMap et TreeMap HashMap HashMap est le plus couramment La carte utilisée, qui stocke les données en fonction de la valeur HashCode de la clé, peut obtenir directement sa valeur en fonction de la clé et a une vitesse d'accès très rapide lors du parcours, l'ordre dans lequel les données sont obtenues est complètement aléatoire. Étant donné que les objets clés ne peuvent pas être répétés, HashMap permet uniquement à la clé d'un enregistrement d'être nulle et à la valeur de plusieurs enregistrements d'être nulle, ce qui est asynchrone Hashtable Hashtable est similaire à HashMap, et est La version thread-safe de HashMap prend en charge la synchronisation des threads, c'est-à-dire qu'un seul thread peut écrire dans Hashtable à tout moment, ce qui rend également Hashtale plus lent lors de l'écriture. Il hérite de la classe Dictionary, mais la différence est. qu'il ne permet pas l'enregistrement. La clé ou la valeur est nulle et l'efficacité est faible. ConcurrentHashMap Thread-safe et séparé par verrou. ConcurrentHashMap utilise des segments en interne pour représenter ces différentes parties. Chaque segment est en fait une petite table de hachage et possède ses propres verrous. Plusieurs opérations de modification peuvent avoir lieu simultanément à condition qu'elles se produisent sur des segments différents. LinkedHashMap LinkedHashMap enregistre l'ordre d'insertion des enregistrements Lorsque vous utilisez Iteraor pour parcourir LinkedHashMap, l'enregistrement obtenu en premier doit être inséré en premier. Il sera plus lent que HashMap pendant la traversée. caractéristiques. TreeMap TreeMap implémente l'interface SortMap et peut trier les enregistrements qu'il enregistre en fonction des clés. La valeur par défaut est de trier par valeurs de clé par ordre croissant (ordre naturel). spécifier un comparateur de tri lors de l'utilisation Lorsque l'itérateur parcourt le TreeMap, les enregistrements obtenus sont triés. La valeur de la clé ne peut pas être vide et non synchronisée ; traversée de la carte Le premier type : KeySet() Deuxième type : EntrySet() 7. Résumé des différences entre les principales classes d'implémentation Vector et ArrayList arraylist et linkedlist HashMap et TreeMap HashTable et HashMap Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Iterator it = arr.iterator();
while (it.hasNext()){ object o =it.next(); ...}
Enregistrer toutes les clés dans le Mapper dans la collection d’ensembles. Parce que set a des itérateurs. Toutes les clés peuvent être récupérées de manière itérative, puis basées sur la méthode get. Obtenez la valeur correspondant à chaque clé. keySet() : Après itération, la clé ne peut être obtenue que via get().
Le résultat obtenu sera dans le désordre car lors de l'obtention de la clé primaire de la ligne de données, la méthode HashMap.keySet() est utilisée et les données du résultat Set renvoyé par cette méthode sont disposées dans le désordre.
L'utilisation typique est la suivante :
Map map = new HashMap();
map.put("key1","lisi1");
map.put("key2","lisi2" );
map.put("key3","lisi3");
map.put("key4","lisi4");
//Obtenez d’abord la collection définie de toutes les clés de la carte collection, keyset ( )
Iterator it = map.keySet().iterator();
//Obtenir l'itérateur
while(it.hasNext()){
Object key = it.next ();
System.out.println(map.get(key));
}
Set
L'utilisation typique est la suivante :
Map map = new HashMap();
map.put("key1","lisi1");
map.put("key2","lisi2" );
map.put("key3","lisi3");
map.put("key4","lisi4");
//Supprimer la relation de mappage de l'ensemble de cartes et la stocker dans l'ensemble Set
Iterator it = map.entrySet().iterator();
while(it.hasNext()){
Entry e =(Entry) it.next();
System.out .println("key" + e.getKey () + "La valeur est " + e.getValue());
>
Il est recommandé d'utiliser la deuxième méthode, la méthode EntrySet() , ce qui est plus efficace.
Le keySet est en fait parcouru deux fois, une fois pour le convertir en itérateur et une fois pour récupérer la valeur de la clé du HashMap. L'ensemble d'entrées ne traverse que la première fois. Il met à la fois la clé et la valeur dans l'entrée, donc c'est plus rapide. La différence de temps de parcours entre les deux parcours est toujours évidente.
1 Vector est synchrone avec les threads, il est donc également thread-safe, alors que arraylist l'est. le thread-asynchrone n’est pas sûr. Si les facteurs de sécurité des threads ne sont pas pris en compte, il est généralement plus efficace d'utiliser arraylist.
2. Si le nombre d'éléments dans la collection est supérieur à la longueur du tableau de collection actuel, le taux de croissance du vecteur est de 100 % de la longueur actuelle du tableau et le taux de croissance de la liste de tableaux est de 50 % de la longueur actuelle du tableau. . Si vous utilisez une quantité relativement importante de données dans une collection, l’utilisation du vecteur présente certains avantages.
3. Si vous recherchez des données à un emplacement spécifié, l'heure utilisée par vector et arraylist est la même. Si vous accédez fréquemment aux données, vous pouvez utiliser à la fois vector et arraylist. Et si le déplacement d'une position spécifiée entraîne le déplacement de tous les éléments suivants, vous devriez envisager d'utiliser linklist à ce stade, car lorsqu'il déplace les données à une position spécifiée, les autres éléments ne bougent pas.
ArrayList et Vector utilisent des tableaux pour stocker des données. Le nombre d'éléments du tableau est supérieur aux données réellement stockées, de sorte que des éléments peuvent être ajoutés et insérés. Les deux permettent une indexation directe des numéros de série des éléments, mais l'insertion de données implique des opérations de mémoire telles que. déplacer les éléments du tableau, donc indexer Les données sont rapides, mais l'insertion des données est lente. Parce que Vector utilise la méthode synchronisée (sécurité des threads), ses performances sont pires que celles d'ArrayList qui utilise une liste doublement chaînée pour implémenter le stockage par série. Le nombre nécessite un parcours vers l'avant ou vers l'arrière, mais uniquement lors de l'insertion de données. Vous devez uniquement enregistrer les éléments avant et après cet élément, donc l'insertion plusieurs fois est plus rapide.
1. ArrayList implémente une structure de données basée sur des tableaux dynamiques, et LinkedList implémente une structure de données basée sur des listes chaînées.
2. Pour obtenir et définir un accès aléatoire, ArrayList est meilleur que LinkedList car LinkedList doit déplacer le pointeur.
3. Pour les opérations de création et de suppression d'ajout et de suppression, LinedList a l'avantage car ArrayList doit déplacer les données. Cela dépend de la situation réelle. Si vous insérez ou supprimez uniquement une seule donnée, ArrayList est plus rapide que LinkedList. Mais si les données sont insérées et supprimées de manière aléatoire par lots, la vitesse de LinkedList est bien meilleure que celle d'ArrayList, car chaque fois qu'une donnée est insérée dans ArrayList, le point d'insertion et toutes les données qui le suivent doivent être déplacés.
1. HashMap utilise le hashcode pour rechercher rapidement son contenu, tandis que tous les éléments de TreeMap conservent un certain ordre fixe. Si vous avez besoin d'obtenir un résultat ordonné, vous pouvez utiliser TreeMap (. l'ordre des éléments dans HashMap n'est pas fixe).
2. Pour insérer, supprimer et localiser des éléments dans Map, HashMap est le meilleur choix. Mais si vous souhaitez parcourir les clés dans un ordre naturel ou personnalisé, TreeMap sera meilleur. L'utilisation de HashMap nécessite que la classe de clé ajoutée définisse clairement l'implémentation de hashCode() et equals().
Les éléments des deux cartes sont les mêmes, mais dans des ordres différents, ce qui donne lieu à un hashCode() différent.
Faites le même test :
Dans HashMap, si la carte de même valeur est dans un ordre différent, égal est faux
Dans treeMap, si la carte de même valeur est dans un ordre différent, égal est ; true Notez que treeMap est trié pendant Equals().
1. Synchronicité : Hashtable est thread-safe, ce qui signifie qu'elle est synchrone, tandis que HashMap est thread-safe et non synchrone.
2. HashMap autorise une clé nulle et plusieurs valeurs nulles.
3. La clé et la valeur de la table de hachage ne peuvent pas être nulles.
Articles Liés
Voir plus- Manipulation de chaînes en Java
- Comment mettre à jour en permanence JLabel avec les résultats d'une tâche de longue durée ?
- Comment accéder aux méthodes de fragmentation ViewPager à partir de l'activité ?
- Comment accéder aux méthodes de fragmentation ViewPager à partir d'une activité ?
- Comment empaqueter des modules spécifiques dans un projet multi-module Maven ?