
Maison >développement back-end >Tutoriel Python >Exemple d'affichage du traitement des données Pandas : collecte de données sur les sociétés cotées à l'échelle mondiale
Exemple d'affichage du traitement des données Pandas : collecte de données sur les sociétés cotées à l'échelle mondiale
- 巴扎黑original
- 2017-07-22 11:39:263567parcourir
J'ai actuellement une copie des données Forbes des 2000 meilleures sociétés mondiales cotées en 2016 à portée de main, mais les données originales ne sont pas standardisées et doivent être traitées avant une utilisation ultérieure.
Cet article présente l'utilisation des pandas pour l'organisation des données à travers des exemples pratiques.
Comme d'habitude, permettez-moi d'abord de parler de mon environnement d'exploitation, comme suit :
windows 7, 64 bits
python 3.5
pandas version 0.19.2
Après avoir obtenu les données d'origine, examinons d'abord les données et réfléchissons à ce que nous avons besoin de résultats de données.
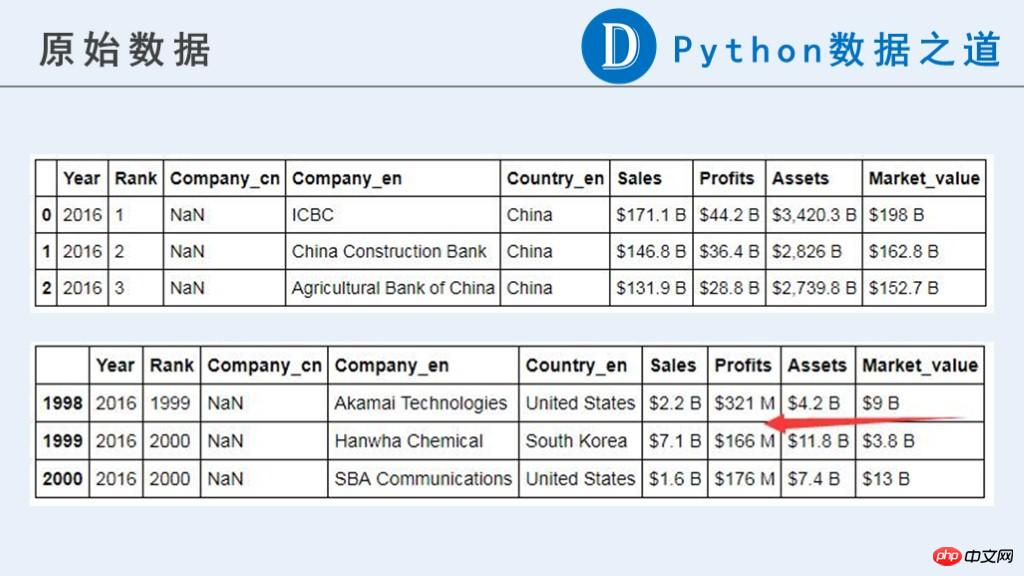
Voici les données brutes :
Dans cet article, nous avons besoin des résultats préliminaires suivants pour une utilisation future.
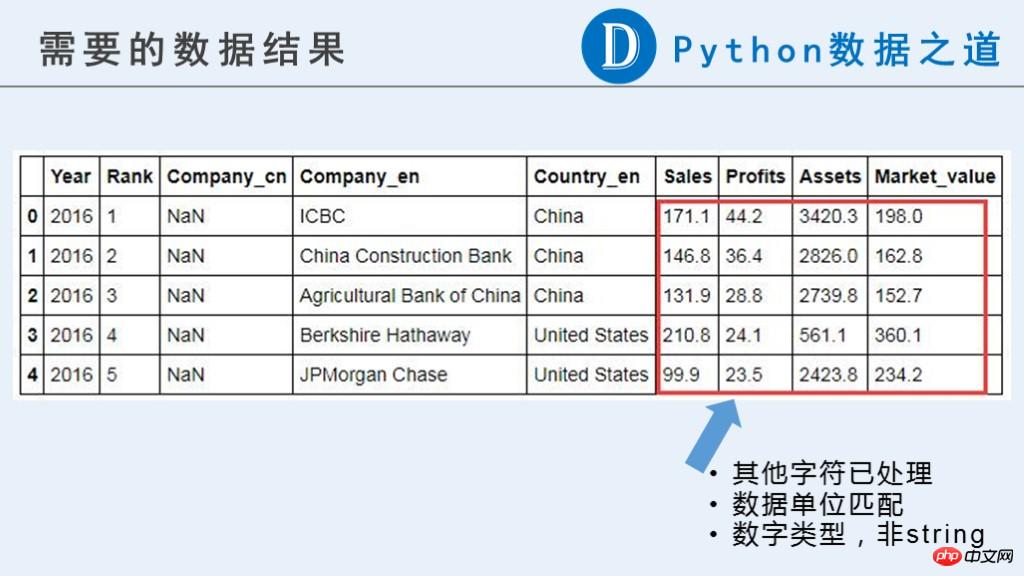
Vous pouvez voir que dans les données d'origine, les données liées à l'entreprise ("Ventes", "Profits", "Actifs", "Market_value") ne sont actuellement pas un type numérique qui peut être utilisé pour les calculs.
Le contenu original contient des symboles monétaires "$", "-", des chaînes composées de lettres pures et d'autres informations que nous considérons comme anormales. De plus, les unités de ces données ne sont pas cohérentes. Ils sont représentés par « B » (Milliard, un milliard) et « M » (Million, un million). L'unification des unités est requise avant les calculs ultérieurs.
1 Méthode de traitement Méthode-1
La première idée de traitement qui me vient à l'esprit est de diviser les informations de données en milliards (« B ») et en millions (« M »), respectivement. et finalement fusionnés. Le processus est le suivant.
Chargez les données et ajoutez le nom de la colonne
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
Obtenez l'unité en milliards (' B' ) données
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_b
Obtenir des données en millions ('M')
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_m
Ceci La méthode est relativement simple à comprendre, mais elle sera lourde à utiliser, surtout s'il y a de nombreuses colonnes de données à traiter, cela prendra beaucoup de temps.
Je ne décrirai pas ici le traitement ultérieur. Bien sûr, vous pouvez essayer cette méthode.
Ce qui suit est une méthode légèrement plus simple.
2 Méthode de traitement Méthode-2
2.1 Chargement des données
La première étape consiste à charger les données, ce qui est la même que la méthode-1.
Ce qui suit consiste à traiter la colonne « Ventes »
2.2 Remplacer les caractères anormaux associés
La première consiste à remplacer les caractères anormaux pertinents, y compris le symbole monétaire du dollar américain « $ », la chaîne alphabétique « non défini » et « B ». Ici, nous voulons organiser uniformément les unités de données en milliards, afin que « B » puisse être remplacé directement. Et « M » nécessite davantage d'étapes de traitement.
2.3 Traitement des données liées aux 'M'
Traitement des données contenant des millions de "M", c'est-à-dire des données se terminant par "M", l'idée est la suivante :
(1) Définissez le masque de condition de recherche
(2) Remplacez la chaîne "M" par une valeur vide
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df
3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
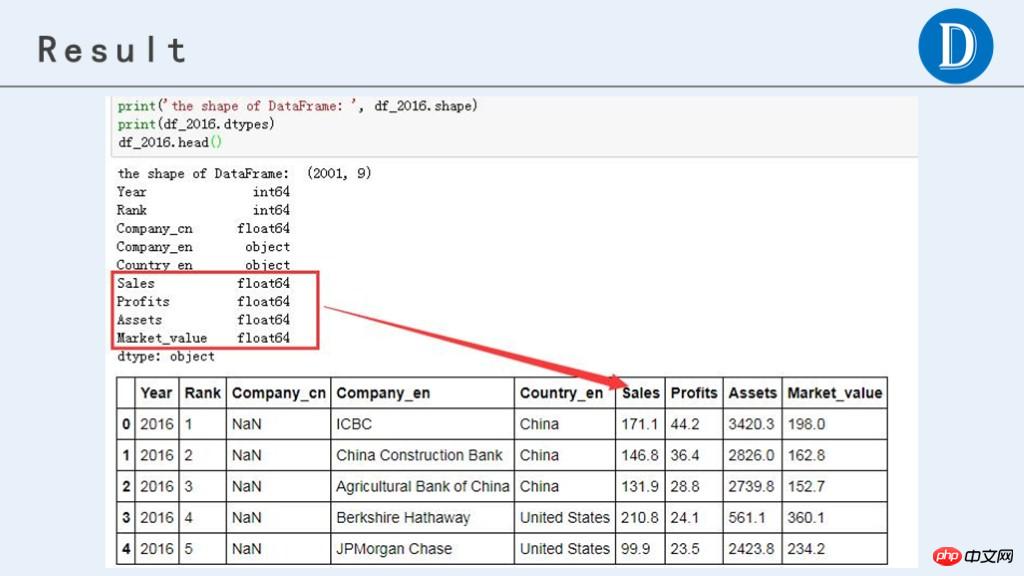
最终处理后,获得的数据结果如下:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!