
Maison >Java >javaDidacticiel >Construire une architecture à haute concurrence et haute disponibilité
Construire une architecture à haute concurrence et haute disponibilité
- 巴扎黑original
- 2017-07-24 14:14:351924parcourir
J'ai résumé la pratique de l'architecture sur la plateforme de commerce électronique sous différents angles. En raison du manque de temps, j'ai finalisé une première ébauche, qui. sera complété et amélioré. Invitez tout le monde à participer à la communication.
Veuillez indiquer la source de la réimpression :
Auteur : Yang Butao
Concentrez-vous sur l'architecture distribuée, le big data, la recherche, la technologie open source
QQ : 306591368
TechnologieBlog:
1.
1.
Espace pour le temps
1)Multi -niveau cache, cache statique de la page client
(l'en-tête http contient Expire/Cache de contrôle, dernière modification (304, le serveur ne renvoie pas le corps, le client peut continuer à utiliser le cache pour réduire le trafic ), ETag)
Cache proxy inverseCache côté application
(memcache)
Base de données mémoireTampon,
mécanisme de cache (base de données, middleware, etc.)
2)Index
Hash,B-tree, inversion, bitmap
L'index de hachage convient aux fonctionnalités complètes d'adressage de tableaux et d'insertion de listes chaînées, et peut permettre un accès rapide aux données.L'index B-tree convient aux scénarios orientés requêtes, évitant plusieurs
IO et améliorant l'efficacité des requêtes.
L'index inversé est le meilleur moyen de mettre en œuvre la relation de mappage mot à document et la structure d'index la plus efficace, et est largement utilisé dans le domaine de la recherche.Bitmap est une structure de données très simple et rapide. Il peut optimiser à la fois l'espace et la vitesse de stockage (sans avoir à échanger de l'espace contre du temps), et convient aux scénarios informatiques avec données massives.
2.
Informatique parallèle et distribuée
1 )
Segmentation des tâches, diviser pour régner(MR)
Dans les données à grande échelle, les données présentent certaines caractéristiques locales, en utilisant le principe de La localité divise et conquiert le problème du calcul massif de données.Le modèle MR est une architecture sans partage et l'ensemble de données est distribué à différents nœuds. Pendant le traitement, chaque nœud lit les données stockées localement pour le traitement
(carte), fusionne les données traitées(combiner), trie(mélange et tri) puis distribue (à réduire le nœud), évitant la transmission de grandes quantités de données et améliorant l'efficacité du traitement.
2)
Multi-processus , Exécution parallèle multithread(MPP)
L'informatique parallèle (Informatique parallèle) fait référence au processus d'utilisation de plusieurs ressources informatiques pour résoudre En même temps, les problèmes informatiques constituent un moyen efficace d'améliorer la vitesse de calcul et la puissance de traitement des systèmes informatiques. Son idée de base est d'utiliser plusieurs processeurs /processus /threads pour résoudre de manière collaborative le même problème, c'est-à-dire décomposer le problème à résoudre en plusieurs parties, et chaque partie est calculée en parallèle par un processeur indépendant. La différence entre et MR est qu'il est basé sur la décomposition des problèmes plutôt que sur la décomposition des données. À mesure que la concurrence sur la plate-forme augmente, il est nécessaire d'étendre la capacité des nœuds pour le clustering et d'utiliser un équipement d'équilibrage de charge pour distribuer les demandes. L'équipement d'équilibrage de charge fournit généralement l'équilibrage de charge ; en même temps, fournit également une fonction de détection des pannes ; en même temps, afin d'améliorer la disponibilité, une sauvegarde de récupération après sinistre est nécessaire pour éviter les problèmes d'indisponibilité causés par une panne de nœud. La sauvegarde est en ligne et hors ligne, et différents choix peuvent être faits en fonction ; à différentes exigences de sauvegarde en cas de panne. La séparation en lecture et en écriture est pour la base de données Avec la concurrence du système Avec. l'augmentation de l'accès aux données, un moyen important d'améliorer la disponibilité de l'accès aux données est de séparer les données d'écriture et de lecture, bien sûr, tout en séparant la lecture et l'écriture, nous devons prêter attention aux problèmes de cohérence des données ; dans les systèmes distribués La quantification CAP se concentre davantage sur la convivialité. La relation entre les différents modules de la plateforme doit être aussi faible- couplés autant que possible, vous pouvez interagir via des composants de message pertinents, asynchrones si possible, et distinguer clairement le processus principal et le processus secondaire du flux de données. Les processus primaires et secondaires sont asynchrones. Par exemple, la journalisation peut être effectuée de manière asynchrone, ce qui augmente la disponibilité. de l’ensemble du système. Bien entendu dans le traitement asynchrone, afin de garantir que les données sont reçues ou traitées, un mécanisme de confirmation (confirmer, ack) est souvent nécessaire. Cependant, dans certains scénarios, bien que la demande ait été traitée, le message de confirmation n'est pas renvoyé pour d'autres raisons (telles qu'un réseau instable ) , alors dans ce cas, la demande doit être retransmise et la conception du traitement de la demande doit prendre en compte l'idempotence due aux facteurs de retransmission. La surveillance est également un moyen important pour améliorer la disponibilité des la plate-forme entière. Les multi-plateformes surveillent plusieurs dimensions ; le module est transparent pendant l'exécution pour réaliser une boxe blanche pendant l'exécution. Le fractionnement inclut le fractionnement de l'entreprise et le fractionnement de la base de données. Les ressources système sont toujours limitées. Si une affaire relativement longue est exécutée en une seule fois, cette méthode de blocage ne peut pas être efficace sous un grand nombre d'opérations simultanées. Les ressources sont libérées à temps pour d'autres. processus à exécuter, le débit du système n’est donc pas élevé. Il est nécessaire de segmenter logiquement l'activité et d'utiliser une méthode asynchrone non bloquante pour améliorer le débit du système. À mesure que la quantité de données et la concurrence augmentent, la séparation de la lecture et de l'écriture ne peut pas répondre aux exigences de performances de concurrence du système. Les données doivent être segmentées, notamment en les divisant en bases de données et en tables. . Cette méthode de division des bases de données et des tables nécessite l'ajout d'une prise en charge de la logique de routage pour les données. Pour l'évolutivité du système, il est préférable que le module soit sans état. En ajoutant des nœuds, le débit global peut être amélioré. La capacité du système est limitée, et le niveau de concurrence qu'il peut supporter est également limité lors de la conception de l'architecture, le contrôle du trafic doit être pris en compte pour empêcher le système de planter en raison d'attaques inattendues ou de l'impact d'une concurrence instantanée. Lors de la conception pour ajouter des mesures de contrôle de flux, vous pouvez envisager de mettre les demandes en file d'attente. Si la demande dépasse la plage attendue, vous pouvez émettre une alarme ou la rejeter. Pour l'accès aux ressources partagées, afin de prévenir les conflits, la concurrence est requis Dans le même temps, certaines transactions doivent être transactionnelles pour garantir la cohérence des transactions, donc lors de la conception du système de transaction, les opérations atomiques et le contrôle de concurrence doivent être pris en compte. Certaines méthodes hautes performances couramment utilisées pour assurer le contrôle de la concurrence incluent le verrouillage optimiste, Latch, mutex, copie sur écriture, CAS, etc. ; le contrôle de concurrence multi-versions MVCC est généralement un moyen important pour garantir la cohérence, qui est souvent utilisé dans la conception de bases de données. Il existe différents types de logique métier dans la plateforme, y compris celles avec des calculs complexes et celles qui consomment des IO. En même temps, pour le même type, différentes logiques métier consomment différentes quantités de ressources. à adopter pour des logiques différentes. Pour le type IO, une méthode non bloquante asynchrone basée sur les événements peut être adoptée. La méthode à thread unique peut réduire la surcharge causée par le changement de thread, ou. dans plusieurs Dans le cas des threads, spin spin est utilisé pour réduire la commutation de thread (comme Conception du loquet Oracle pour les calculs, utiliser pleinement le multi-thread pour les opérations); Le même type de méthode d'appel, différentes entreprises effectuent une allocation de ressources appropriée et définissent différents nombres de nœuds ou de threads informatiques Quantité, détournez l'activité et exécutez en premier les affaires hautement prioritaires. Lorsqu'une erreur se produit dans certains modules métier du système, afin pour réduire la concurrence, le système normal Concernant l'impact du traitement des requêtes, il est parfois nécessaire d'envisager de traiter ces requêtes anormales via des canaux séparés, voire de bannir automatiquement temporairement ces modules métiers anormaux. L'échec de certaines demandes peut être un échec temporaire accidentel (comme une instabilité du réseau ), et une nouvelle tentative de demande doit être envisagée. Les ressources du système sont limitées lors de l'utilisation. ressources Lors d'une demande, les ressources doivent être libérées à la fin, que la demande emprunte un chemin normal ou un chemin anormal, afin que les ressources puissent être récupérées à temps pour d'autres demandes. Lors de la conception de l'architecture de communication, il est souvent nécessaire de prendre en compte le contrôle des délais d'attente. L'architecture entière est une architecture en couches et distribuée, y compris verticalementCDN, équilibrage de charge/proxy inverse, application web, couche métier, couche service de base, couche de stockage de données. L'orientation horizontale comprend la gestion de la configuration, le déploiement et la surveillance de l'ensemble de la plateforme. CDNLe système peut analyser en temps réel le trafic réseau et la connexion de chaque nœud, l'état de charge, la distance par rapport à l'utilisateur. et temps de réponse, etc. Les informations complètes redirigent la demande de l'utilisateur vers le nœud de service le plus proche de l'utilisateur. Son objectif est de permettre aux utilisateurs d'obtenir le contenu dont ils ont besoin à proximité, de résoudre la congestion du réseau Internet et d'améliorer la vitesse de réponse des utilisateurs accédant aux sites Web. Pour les plateformes de commerce électronique à grande échelle, il est généralement nécessaire de créer un CDN pour l'accélération du réseau que les grandes plateformes telles que Taobao et JD.com utilisent toutes. Les petites et moyennes entreprises CDN auto-construites peuvent coopérer avec des fabricants CDN tiers, tels que Lanxun, Wangsu, Kuaiwang, etc. Bien sûr, lorsque vous choisissez un fournisseur CDN, vous devez tenir compte de la durée de l'activité et s'il a ressources de bande passante évolutives, sélection flexible du trafic et de la bande passante, nœuds stables et rentabilité. Une grande plate-forme comprend de nombreux domaines professionnels, et différents domaines professionnels ont des clusters différents, vous pouvez utiliser DNS fait la distribution ou le sondage de résolution de nom de domaine. La méthode DNS est simple à mettre en œuvre, mais manque de flexibilité du fait de la présence de cache généralement basé sur du matériel commercialF5, NetScaler ; Ou le softload open source lvs est distribué sur la couche 4 Bien entendu, la redondance ( telle que lvs+keepalived) sera prise en compte, et l'actif. et des méthodes de sauvegarde seront adoptées. 4 couches Après avoir été distribué au cluster d'affaires, il sera distribué via des serveurs web tels que nginx ou HAProxy au niveau de la couche 7 pour le chargement équilibrage ou distribution de proxy inverse aux nœuds d'application du cluster. Quelle charge choisir nécessite une prise en compte approfondie de divers facteurs (qu'elle réponde à une concurrence élevée et hautes performances, comment résoudre la rétention de session, quel est l'algorithme d'équilibrage de charge, prise en charge de la compression, consommation de mémoire cache) ; ce qui suit est une introduction basée sur plusieurs logiciels d'équilibrage de charge couramment utilisés. LVS, fonctionnant sur la couche 4, est un équilibreur de charge hautes performances, à haute concurrence, évolutif et fiable implémenté par Linux, prenant en charge un variété de modes de transfert (NAT, DR, IP Tunneling), parmi lesquels le mode DR prend en charge l'équilibrage de charge via le WAN. Prend en charge la veille chaude sur deux machines (Keepalived ou Heartbeat) . La dépendance à l'égard de l'environnement réseau est relativement élevée. Nginx fonctionne sur la couche 7, une architecture événementielle, asynchrone et non bloquante, prenant en charge l'équilibreur de charge multi-processus à haute concurrence / logiciel de proxy inverse. Vous pouvez faire un détournement pour http en fonction des noms de domaine, des structures de répertoires et des règles habituelles. Détectez les pannes internes du serveur via le port, telles que les codes d'état, les délais d'attente, etc. renvoyés par le serveur traitant les pages Web, et soumettez à nouveau les requêtes qui renvoient des erreurs à un autre nœud. Cependant, l'inconvénient est que url ne l'est pas. pris en charge. Pour session sticky, il peut être implémenté sur la base de l'algorithme de ip hash, et session sticky est pris en charge via l'extension basée sur les cookies nginx-sticky-module . HAProxy prend en charge 4 couches et 7 couches pour l'équilibrage de charge, prend en charge la rétention de session session et les conseils cookie pris en charge ; Détection de la méthode url ; les algorithmes d'équilibrage de charge sont relativement riches, y compris RR, poids, etc. Pour les photos, il vous faut Un nom de domaine distinct, un serveur d'images indépendant ou distribué, ou mogileFS peut être utilisé pour ajouter varnish au serveur d'images pour la mise en cache des images. La couche application s'exécute sur jboss ou Le conteneur Tomcatreprésente des systèmes indépendants, tels que les achats front-end, les services indépendants des utilisateurs, les systèmes back-end, etc. Interface de protocole, HTTP, JSON peuvent utiliser servlet3.0, servlet asynchrone, pour améliorer la le débit de l'ensemble du système http la requête passe par Nginx et est affectée à un nœud de App grâce à l'algorithme d'équilibrage de charge , il est relativement simple d'étendre la capacité couche par couche. En plus d'utiliser un cookie pour enregistrer une petite quantité d'informations sur l'utilisateur(le cookie ne peut généralement pas dépasser la taille 4K), pour la couche d'accès Application, les données de session liées à l'utilisateur sont enregistrées, mais certains proxys inverses ou équilibrage de charge ne prennent pas en charge session collanteLe support n'est pas très bon ou les exigences de disponibilité d'accès sont relativement élevées(applicationLe nœud d'accès est en panne et sessionest perdue) , cela nécessite d'envisager le stockage centralisé de la session pour rendre la couche d'accès App apatride. Dans le même temps, lorsque le nombre d'utilisateurs du système augmente, davantage de nœuds d'application peuvent être. ajouté. Le stockage centralisé de la session doit répondre aux exigences suivantes : a, protocole de communication efficace b, cache distribué de session, prend en charge la mise à l'échelle des nœuds, la sauvegarde redondante des données et la migration des données c, sessionGestion des expirations représentent les services fournis par les entreprises dans un certain domaine. Pour le commerce électronique, les champs incluent les utilisateurs, les marchandises, les commandes, les enveloppes rouges, les services de paiement, etc. Différents champs fournissent différents services, RPC de NIO, et le plus mature NIO peut être utilisé dans des cadres de communication tels que netty, mina ; VIP+heartbeat méthode, le système actuel a un composant distinctHA,utilisezookeeper pour mettre en œuvre( Avantages par rapport à la solution originale) fonctionnement, les connexions longues dans le pool de connexions nécessitent une maintenance du rythme cardiaque et définissent le délai d'expiration de la demande. Le processus de maintenance des connexions longues peut être divisé en deux étapes, l'une est le processus d'envoi de la demande et l'autre est le processus de réception de la réponse. Pendant le processus d'envoi de la demande, si se produit, la connexion sera marquée comme invalide. Lors de la réception d'une réponse, le serveur renvoie SocketTimeoutException Si un délai d'attente est défini, il renverra directement une exception et effacera les requêtes expirées dans la connexion actuelle. Sinon, continuez à envoyer des paquets de battements de cœur (Parce qu'il peut y avoir une perte de paquets, si l'intervalle dépasse pingInterval, envoyez pingopération), if Si le ping échoue ( envoie IOException) , cela signifie qu'il y a un problème avec la connexion actuelle, alors marquez la connexion actuelle comme invalide ; ping réussit, indiquant que la connexion actuelle est fiable et que l'opération de lecture continue. Les connexions invalides seront supprimées du pool de connexions. Chaque connexion s'exécute dans un thread séparé pour recevoir des réponses. Le client peut le faire de manière synchrone (attendre, notifier) rpc appeler, <. la s> adopte la méthode de sérialisation hession plus efficace. Le serveur utilise le framework MINA piloté par les événements de NIO pour prendre en charge les requêtes à haute concurrence et à haut débit. dans Dans la plupart des solutions de partitionnement de base de données, afin d'améliorer le débit de la base de données, différentes tables sont d'abord segmentées verticalement en différentes bases de données Ensuite, lorsqu'une table de la base de données dépasse une certaine taille, la table doit être divisée. horizontalement, et la même chose est vraie ici. Ici, nous prenons la table des utilisateurs comme exemple Pour les clients accédant à la base de données, il est nécessaire de localiser l'emplacement auquel il faut accéder en fonction du de l'utilisateur ; ID données ; algorithme de segmentation des données, effectue une opération de hachage en fonction de l'ID de l'utilisateur. Hash, cette méthode a le problème de migrer des données invalides, et le service n'est pas disponible pendant la période de migration Maintenir la table de routage, La relation de mappage entre les utilisateurs et le sharding est stockée dans la table de routage est divisée en leader et réplique, qui sont chargés respectivement de l'écriture et de la lecture biz le client doit conserver tout le sharding pool de connexions, cela présente l'inconvénient de provoquer le problème de la connexion complète sharding Accédez à la couche de services métier. Chaque nœud métier ne maintient qu'une seule connexion shard. routeur) idMongoDB La relation entre 🎜> et shard est de construire un cluster replicatset pour garantir la disponibilité. de biz et le shardingIl s'agit d'une correspondance individuelle et n'accède qu'à une seule base de donnéessharding.biz business nœud d'enregistrement à up/bizs/shard/down. routeurSurveillance état du nœud sur /bizs/, cache en lignebiz est dans le routeur. Lorsque le client demande au routeur d'obtenir biz, le routeur obtient d'abord le fragment correspondant de l'utilisateur auprès de mongodb ,router obtient le nœud biz via l'algorithme RR basé sur le contenu mis en cache. Afin de résoudre les problèmes de disponibilité et de débit simultané du routeur, effectuez une redondance sur le routeur, et en même temps, les client surveillent zookeeper /routers de 🎜> et mettent en cache la liste des nœuds routeurs en ligne. HA consiste généralement à utiliser la dérive IP virtuelle, combinée avec Heartbeat, keepalived , etc.HA, Utiliser le modevrrp transmet les paquets de données, fournissant un équilibrage de charge de 4 couches, commutant en détectant les paquets de données vrrp, rendant la veille chaude redondante plus adaptée à Match LVS. linux Heartbeat est un service à haute disponibilité basé sur le réseau ou l'hôte HAProxy ou Nginx peut transférer des paquets de données en fonction de la couche 7. . Par conséquent, Heatbeat est plus adapté à HAProxy et Nginx, y compris la haute disponibilité professionnelle. zookeeper pour la coordination distribuée et réaliser le cluster pour la maintenance de la liste et notification d'échec, le client peut choisir l'algorithme hash ou roudrobin pour réaliser l'équilibrage de charge pour le mode maître-maître, maître-esclave mode, qui peut être pris en charge via le mécanisme de verrouillage distribué zookeeper. 4) Message . Lors de la conception des composants du service de messagerie, la cohérence, la persistance, la disponibilité et un système de surveillance complet des messages doivent être pris en compte. Il existe deux principaux middlewares de messages open source dans l'industrie : et kafka, RabbitMQ, suit le protocole AMQP et est développé par le langage erlanng intrinsèquement à haute concurrence est Linkedin en 2010 AnnéeDécembreUn système de publication et d'abonnement de messages open source,Il est principalement utilisé pour traiter les données de streaming actives,Traitement des données de grandes quantités de données. RabbitMQ adopte cette méthode. Il existe également un mécanisme par lequel le consommateur apporte le numéro LSN lorsqu'il extrait le message du courtier et le regroupe par lots à partir d'un certain LSN dans le courtier Extrayez les messages, il n'y a donc pas besoin d'un mécanisme de réponse kafka le middleware de messages distribués est de cette façon. courtier , selon les exigences de fiabilité du message et la mesure complète des performances, peut être en mémoire ou conservé dans le stockage. Pour des exigences de disponibilité et de débit élevé, les modes cluster et veille active peuvent être appliqués dans des scénarios réels. La solution inclut des méthodes de cluster ordinaire et de file d'attente miroir à plus haute disponibilité. kafka utilise zookeeper pour gérer le courtier et le consommateur dans le cluster. Vous pouvez enregistrer le sujet sur zookeeper<.>Up ; grâce au mécanisme de coordination de zookeeper, le producteur enregistre les informations du courtier correspondant au sujet, qui peuvent être envoyées à courtier ; et producteur peuvent spécifier des fragments en fonction de la sémantique, et les messages sont envoyés à un certain fragment de courtier. En général, RabbitMQ est utilisé dans Messagerie en temps réel qui nécessite une fiabilité relativement élevée. kafka est principalement utilisé pour traiter les données de streaming actives le traitement de données volumineuses. 5) Cache et tampon Dans certains scénarios à haute concurrence et hautes performances, l'utilisation du cache peut réduire la charge sur le système back-end et supporter l'essentiel de la pression de lecture, ce qui peut considérablement améliorer le débit du système. Par exemple, généralement dans une base de données, ajoutez un cache avant de stocker. Cependant, l'introduction de l'architecture cache entraînera inévitablement certains problèmes, notamment des cache problèmes de taux de réussite, la gigue causée par l'échec du cache, cache et cohérence du stockage. Les données en cache sont limitées par rapport au stockage, c'est donc la situation idéale. Ce sont les données chaudes du système de stockage. Ici, vous pouvez utiliser certains algorithmes courants LRU et ainsi de suite pour éliminer les anciennes données ; à mesure que l'échelle du système augmente, un seul nœud cache ne peut pas être utilisé. répondre aux exigences. Il est nécessaire de construire un Cache distribué afin de résoudre la gigue causée par la défaillance d'un seul nœud, le cache distribué adopte généralement la solution de cohérence hash, qui réduit considérablement le risque de défaillance d'un seul nœud. La plage de gigue causée par la défaillance d'un nœud ; pour les scénarios avec des exigences de disponibilité relativement élevées, chaque nœud doit être sauvegardé. Les données ont la même sauvegarde à la fois dans le cache et dans le stockage. Si la cohérence est relativement forte, mettez à jour le cache de la base de données en même temps. Pour ceux qui ont de faibles exigences de cohérence, vous pouvez définir une politique de délai d'expiration du cache. est un serveur de cache distribué à haut débit avec un protocole relativement simple et est basé sur le mécanisme de traitement d'événements de libevent. Le système est utilisé dans le client du système routeur de la plateforme. Les données du hotspot seront mises en cache sur le client. Lors de l'accès aux données En cas d'échec, accédez au système routeur. cache, comme Redis , mongodb; redis a des opérations de données plus riches que memcacheAPI redis et mongodb toutes les données persistent, mais memcache n'a pas cette fonction, donc memcache est plus adapté à la mise en cache des données sur des bases de données relationnelles. Système utilisé dans les opérations d'écriture à grande vitesse Dans la plate-forme, certaines données doivent être écrites dans la base de données, et les données sont divisées en bases de données et en tables, mais la fiabilité des données n'est pas si élevée. Afin de réduire la pression d'écriture sur la base de données, des opérations d'écriture par lots peuvent être effectuées. adopté. Ouvrir une zone mémoire. Lorsque les données atteignent un certain seuil de la zone, tel que 80%, la sous-bibliothèque est triée dans la mémoire (la vitesse de la mémoire est encore relativement rapide), puis la la sous-bibliothèque est vidée par lots. 6) Recherche Les moteurs de recherche open source au niveau de l'entreprise incluent principalement a. Le moteur de recherche prend-il en charge l'indexation et la recherche distribuées pour gérer des données massives, prend-il en charge la séparation en lecture-écriture et améliorer la disponibilité ? b. Indexation en temps réel Sexe c, Performance Solr est un serveur de recherche en texte intégral hautes performances basé sur lucene Il fournit un langage de requête plus riche que lucene. Il est configurable et évolutif et fournit des fonctionnalités externes. services basés sur l'interface au format XML/JSON du protocole lucene. SolrCloudSolr4 version 🎜> pour prendre en charge l'indexation distribuée, effectue automatiquement la segmentation des données de sharding via le maître-esclave de chaque sharding (leader, réplique) ; Le mode améliore les performances de recherche ; utilisez zookeeper pour gérer le cluster, y compris l'élection du leader, etc., pour garantir la disponibilité du cluster. Reader indexé est basé sur un instantané indexé, donc un nouveau doit être rouvert après l'indexation commit 🎜>instantané peut être utilisé pour rechercher du contenu nouvellement ajouté ; l'indexation commit est très gourmande en performances, de sorte que l'efficacité de la recherche d'index en temps réel est relativement faible. Pour la recherche d'index en temps réel, consistait à combiner l'index de fichier complet et la fusion d'index incrémentiel de mémoire, voir la figure ci-dessous. Solr4 NRT softcommit, softcommitVous pouvez rechercher les dernières modifications apportées à l'index sans valider l'opération d'index. Cependant, les modifications apportées à l'index ne sont pas validation de synchronisation sur le stockage du disque dur. Si un accident se produit et que le programme se termine anormalement, ce ne sera pascommit seront perdues, donc l'opération commit doit être effectuée régulièrement. Les opérations d'indexation et de stockage des données dans la plateforme sont asynchrone , ce qui peut considérablement améliorer la disponibilité et le débit ; effectuer des opérations d'indexation uniquement sur certains champs d'attributs, stocker la clé d'identification des données Hbase ; , hbase ne prend pas bien en charge la recherche d'index secondaire, mais elle peut être combinée avec la fonction de recherche Solr pour effectuer des statistiques de récupération multidimensionnelles. La cohérence des données d'index et du stockage des données HBase HBase ont été indexées. Vous pouvez utiliser le mécanisme de confirmation confirm pour créer une file d'attente de données à indexer avant l'indexation. la file d'attente de données à indexer est extraite de la file d'attente de données à indexer Supprimer les données dans . Le système de journalisation doit avoir trois composants de base, à savoir agent (encapsule la source de données et envoie les données de la source de données au collecteur), collecteur (Recevoir des données de plusieurs agents, les résumer et les importer dans le magasin du backend), magasin (système de stockage central, doit être évolutif et fiable, il devrait prendre en charge le HDFS actuellement très populaire). Open source Les systèmes de collecte de journaux les plus couramment utilisés dans l'industrie sont Flume de cloudera et Scribe de facebook, parmi lesquels Flume La version actuelle FlumeNG a apporté des modifications architecturales majeures à Flume. en design Ou lors de la sélection technique d'un système de collecte de journaux, il doit généralement avoir les caractéristiques suivantes : a. Un pont entre le système d'application et le système d'analyse, découplant la relation entre eux b , distribué et évolutif, avec une grande évolutivité. Lorsque la quantité de données augmente, elle peut être étendue horizontalement en ajoutant des nœuds Le système de collecte de journaux est évolutif et peut être évolutif à tous les niveaux du système. ne nécessite pas d’état et l’évolutivité est relativement facile à mettre en œuvre. c. En temps quasi réel Dans certains scénarios nécessitant des délais élevés, les journaux doivent être collectés en temps opportun pour l'analyse des données Les fichiers journaux généraux seront exécutés ; rolling régulièrement ou quantitativement, de sorte que la génération de fichiers journaux puisse être détectée en temps réel, des opérations tail similaires peuvent être effectuées sur les fichiers journaux en temps opportun et l'envoi par lots est pris en charge pour améliorer l'efficacité de la transmission ; le calendrier d'envoi par lots est requis. Répondre aux exigences de quantité de messages et d'intervalle de temps. d. Tolérance aux pannes ScribeLa tolérance aux pannes est prise en compte lorsque le système de stockage back-end plante, scribe écrira les données sur le disque local Lorsque le système de stockage reviendra à la normale, scribe rechargera le journal dans le système de stockage. FlumeNG réalise l'équilibrage de charge et le basculement via le Sink Processor. Plusieurs Sink peuvent former un Sink Group. Un Sink Processor est responsable de l'activation d'un Sink à partir d'un Sink Group spécifié. Le Sink Processor peut réaliser un équilibrage de charge sur tous les Sink du groupe ; il peut également être transféré vers un autre Sink en cas de panne. e. La prise en charge des transactions Scribe ne prend pas en compte la prise en charge des transactions. Flume prend en charge les transactions via le mécanisme de confirmation de réponse, voir la figure ci-dessous, Habituellement, l'extraction et l'envoi de messages sont Pour les opérations par lots, la confirmation du message est une confirmation d'un lot de données, ce qui peut grandement améliorer l'efficacité de l'envoi des données. f. Récupérabilité canal de FlumeNG peut être basé sur des mécanismes de mémoire et de persistance de fichiers basés sur différentes exigences de fiabilité. Le volume des ventes de transmission de données basées sur la mémoire est relativement élevé, mais après la panne du nœud. , les données perdues et irrécupérables ; le temps d'arrêt de persistance des fichiers peut être récupéré. g. Archivage régulier et quantitatif des données Une fois les données collectées par le système de collecte de journaux, elles sont généralement stockées dans un système de fichiers distribué tel que comme Hadoop, afin de faciliter le traitement et l'analyse ultérieurs des données, il est nécessaire de programmer des (TimeTrigger) ou quantitatifs (SizeTrigger's fichier roulant du système distribué Dans un système commercial, des sources de données hétérogènes sont généralement nécessaires. La synchronisation implique généralement des fichiers de données vers des bases de données relationnelles, des fichiers de données vers des bases de données distribuées, des bases de données relationnelles vers des bases de données distribuées, etc. La synchronisation des données entre des sources hétérogènes est généralement basée sur les performances et les besoins de l'entreprise. Le stockage des données dans des fichiers locaux est généralement basé sur des considérations de performances. Les fichiers sont stockés de manière séquentielle, de sorte que l'efficacité de la synchronisation des données avec les données relationnelles est généralement basée sur. les exigences en matière de requêtes ; alors que les bases de données distribuées stockent des données de plus en plus volumineuses, les bases de données relationnelles ne peuvent pas répondre aux demandes de stockage et de requêtes volumineuses. Dans la conception de la synchronisation des données, des problèmes tels que le débit, la tolérance aux pannes, la fiabilité et la cohérence doivent être pris en compte de manière globale. La synchronisation peut être divisée en synchronisation incrémentielle des données en temps réel et synchronisation complète hors ligne. synchronisation des données. Ce qui suit est tiré de ceci. Présentons-le sous deux dimensions Les incréments en temps réel sont généralement des fichiers Tail pour suivre les modifications des fichiers en temps réel et exporter , <.> à la base de données par lots ou multi-threads. L'architecture est similaire au framework de collecte de journaux. Cette méthode nécessite un mécanisme de confirmation, comprenant deux aspects. doit confirmer à agent qu'il a reçu des enregistrements de données par lots et envoyer LSN numéro à agent, de sorte que lorsque agent échoue et récupère, il puisse démarrer la queue à partir de ce LSN point ; Bien sûr, une petite quantité de duplication est autorisée. Problème enregistré ( s'est produit lorsque le canal a été confirmé à l'agent, l'agent est tombé en panne et n'a pas reçu le message de confirmation), doit être jugé dans le scénario commercial. synchroniser confirmer à canal que l'écriture a été effectué par lots Opération vers la base de données, afin que canal puisse supprimer cette partie du message qui a été confirmé. canal peut utiliser la persistance des fichiers. Il est nécessaire de segmenter les données sources telles que MySQL, de lire les données sources simultanément avec plusieurs threads et d'écrire simultanément par lots dans une base de données distribuée telle que HBase, en utilisant canalEn tant que tampon entre la lecture et l'écriture pour obtenir un meilleur découplage, le canal peut être basé sur le stockage de fichiers ou la mémoire. Voir l'image ci-dessous : Pour la segmentation des données sources , S'il s'agit d'un fichier, vous pouvez définir la taille du bloc en fonction du nom du fichier pour le diviser. Pour les bases de données relationnelles, puisque l'exigence générale est de synchroniser les données hors ligne uniquement pendant une période de temps (Par exemple, synchroniser les données de commande du jour avec HBase au début matin), il est donc nécessaire Lorsque les données sont divisées ( est divisée en fonction du nombre de lignes ) , les multi-threads scanneront toute la table ( créer des index dans le temps et renvoyer la table ) , pour les tables contenant une grande quantité de données, IO est très élevée et l'efficacité est très faible ici ; la base de données en fonction du champ horaire ( selon l'heure)Créer des partitions et exporter en fonction des partitions à chaque fois. Du cluster de traitement parallèle traditionnel basé sur une base de données relationnelle, utilisé pour le calcul en mémoire en temps quasi réel, à celui actuel basé sur hadoop Analyse de données massives, l'analyse des données est largement utilisée dans les grands sites de commerce électronique, notamment les statistiques de trafic, les moteurs de recommandation, l'analyse des tendances, l'analyse du comportement des utilisateurs, les classificateurs d'exploration de données, les index distribués, etc. Le cluster de traitement parallèle dispose d'un commercial, et l'architecture de Greenplum adopte MPP( Traitement parallèle à grande échelle), une base de données distribuée basée sur postgresql pour le stockage de données volumineuses. En termes d'informatique en mémoire, il existe HANA, la base de données open source nosql en mémoire mongodb prend également en charge mapreduce pour l'analyse des données. L'analyse hors ligne de données massives est actuellement largement utilisée par les sociétés Internet , Hadoop présente des avantages irremplaçables en termes d'évolutivité, de robustesse, de performances informatiques et de coût. En fait, il est devenu la plateforme d'analyse Big Data grand public pour les sociétés Internet actuellesHadoop est utilisé pour traiter des données à grande échelle via le cadre de traitement distribué de , et son évolutivité est également très bonne, mais le plus gros défaut de MapReduce ; Il s'agit d'un scénario qui ne peut pas répondre aux exigences en temps réel et est principalement utilisé pour l'analyse hors ligne. Basé sur la programmation du modèle MapRduce pour l'analyse des données, l'efficacité du développement n'est pas élevée. L'émergence de Hive située au-dessus de hadoop permet d'analyser les données. similaire à l'écriture, sql est effectué. sql subit une analyse syntaxique et génère des plans d'exécution pour finalement générer des tâches MapReduce pour l'exécution. Cela améliore considérablement l'efficacité du développement et. atteint l'objectif de ad-hoc(Calcule l'analyse effectuée de manière ) lorsque la requête se produit. L'analyse des données distribuées basée sur le modèle MapReduce est entièrement une analyse hors ligne, et l'exécution est entièrement une analyse violente, et il est impossible d'utiliser un mécanisme de type index ; open source Cloudera Impala est basé sur le modèle de programmation parallèle de MPP La couche sous-jacente est une plateforme d'analyse en temps réel haute performance stockée dans Hadoop, ce qui peut réduire considérablement le délai d’analyse des données. La version actuelle de Hadoop est Hadoop1.0, d'une part, le framework MapReduce original a un problème unique de JobTracker D'autre part, JobTracker gère les ressources et la planification des tâches. en même temps, avec l'augmentation de la quantité de données et l'augmentation des tâches Job, il existe des goulots d'étranglement évidents en termes d'évolutivité, de consommation de mémoire, de modèle de thread, de fiabilité et de performances Hadoop2.0 ; L'ensemble du cadre a été restructuré, la gestion des ressources et la planification des tâches ont été séparées, et ce problème a été résolu dès la conception architecturale. Fil de référence Architecture Dans le domaine Internet, l'informatique en temps réel est largement utilisée dans la surveillance et l'analyse en temps réel, le contrôle des flux, le contrôle des risques et d'autres domaines. Les systèmes ou applications de plate-forme de commerce électronique doivent filtrer et analyser les grandes quantités de journaux quotidiens et d'informations anormales générées quotidiennement pour déterminer si une alerte précoce est nécessaire ; Contrôler pour éviter la paralysie du système causée par une pression excessive inattendue sur le système. de grande envergure, des mécanismes tels que le rejet ou le détournement peuvent être adoptés ; certaines entreprises nécessitent un contrôle des risques, comme certaines entreprises de loterie qui doivent se baser sur les ventes en temps réel du système. Limiter et attribuer des numéros en fonction de la situation. Basé à l'origine sur le calcul d'un seul nœud, avec la génération explosive d'informations système et l'augmentation de la complexité des calculs, le calcul d'un seul nœud ne peut plus répondre aux exigences du calcul en temps réel et du calcul distribué multi-nœuds. Le calcul est nécessaire, une plate-forme informatique distribuée en temps réel a émergé. L'informatique en temps réel mentionnée ici est en fait l'informatique en streaming. Le prédécesseur du concept est en fait le le traitement d'événements complexes tels que Esper. distribués dans l'industrie. Parmi les produits de streaming computing Yahoo S4, Twitter storm, etc., les produits open source de storm sont les plus largement utilisés. Pour une plateforme informatique en temps réel, les facteurs suivants doivent être pris en compte en termes de conception architecturale : 1, Évolutivité À mesure que le volume d'activité augmente et que la quantité de calcul augmente, il peut être traité en ajoutant un traitement de nœud. 2. Hautes performances et faible latence Du flux de données vers la plate-forme informatique au calcul des résultats de sortie, des performances élevées et une faible latence sont nécessaires pour garantir que les messages sont traités rapidement et en temps réel. les calculs sont réalisés. 3. Fiabilité Assurez-vous que chaque message de données est traité complètement une fois. 4. Tolérance aux pannes Le système peut gérer automatiquement les temps d'arrêt et les pannes des nœuds, ce qui est transparent pour l'application. Twitter Storm fait mieux dans les aspects ci-dessus. Présentons brièvement l'architecture de Storm. L'ensemble du cluster est géré via zookeeper. Le client soumet la topologie à nimbus. Nimbus Établir un répertoire local pour cette topologie Calculer la tâche en fonction de la configuration de la topologie. , et allouez la tâche, établissez les affectations stockage du nœudtâche sur zookeeper et woker dans le nœud de la machine >correspondance . taskbeats sur zookeeper pour surveiller le rythme cardiaque du tâche ; > topologie. Superviseur gardien de zoo pour obtenez-le tâches assignées, démarrez plusieurs woker pour continuer, chaque woker génère une tâche, un tâche fil Initialiser la connexion entre la tâche en fonction des informations de topologie ; La connexion entre la tâche et la tâche se fait via zeroMQ géré ; puis alors toute la topologie est en cours d'exécution. Tuple Tuple, circule dans la tâche. Le processus d'envoi et de réception de Tuple est le suivant : <.> envoie un Tuple Worker fournit une fonction de transfert pour la tâche actuelle envoie un tuple à une autre tâche. Avec les paramètres goal taskid et tuple, sérialisez les données tuple et placez-les dans la file d'attente de transfert. Avant la version 0.8, cette file d'attente était LinkedBlockingQueue, et après 0.8 c'était DisruptorQueue . à 0,8 Après la version, chaque woker est lié à une file d'attente de transfert entrant et à une file d'attente sortante, et la file d'attente entrante est utilisée pour recevoir message, file d'attente sortante est utilisée pour envoyer des messages. Lors de l'envoi d'un message, un seul thread extrait les données de la file d'attente de transfert et envoie ce tuple à un autre wokerzeroMQ 🎜> Moyen. Reçoit Tuple, chacun woker écoutera le port tcp de zeroMQ pour recevoir des messages. Une fois le message placé dans DisruptorQueue, il sera ensuite envoyé depuis. queueObtenez message(taskid,tuple) et acheminez-le vers task pour une exécution en fonction de la valeur de la destination taskid, tuple. Chaque tuple peut être émis vers direct steam, ou peut être envoyé vers un flux régulier en Reglular Dans ce De cette manière, la fonction Stream Group (stream id-->component id -->outbond tâches) est utilisée pour compléter le à envoyer par le tuple La destination du Tuple. Grâce à l'analyse ci-dessus, nous pouvons voir que est très efficace en termes d'évolutivité, de tolérance aux pannes et de hautes performances de la perspective de la conception architecturale peut être prise en charge ; en même temps, en termes de fiabilité, le composant ack de Storm utilise l'algorithme XOR xor pour garantir. que chaque message est entièrement traité sans perte de performances en même temps. 11) Push en temps réel , etc. Il existe de nombreuses technologies pour réaliser un push en temps réel, notamment la méthode , la méthode websocket, etc. Comet Technologie "Server Push" basée sur une connexion serveur longue, comprenant deux types : Long Polling : Le serveur se bloque après réception de la requête et lorsqu'il y a une mise à jour La connexion est déconnectée après le retour, puis le client initie une nouvelle connexion Méthode Stream : La connexion ne sera pas fermée à chaque transmission des données du serveur, la connexion ne sera communiquée que lorsqu'une erreur se produit ou que la connexion est rétablie, elle est fermée (certains pare-feu sont souvent configurés pour rejeter les connexions trop longues. Le serveur peut définir un délai d'attente et demander au client de rétablir la connexion après le délai d'attente et fermez la connexion d'origine). Websocket : connexion longue, communication full-duplex est un nouveau protocole de HTML5 . Il implémente une communication bidirectionnelle entre le navigateur et le serveur. API webSocket , le navigateur et le serveur n'ont besoin que de passer une action de prise de contact pour former un canal bidirectionnel rapide entre le navigateur et le client, afin que les données puissent être rapidement transmises dans les deux sens. Socket.io est une bibliothèque Websocket NodeJS, comprenant js côté client et serveur- côté nodejs, utilisé pour créer rapidement des applications web en temps réel. À ajouter Le stockage des bases de données est généralement divisé dans les catégories suivantes, y compris les bases de données relationnelles (transactionnelles), telles que oracle, mysql<.> est représenté par la base de données keyvalue, représentée par redis et memcached db, et il existe des bases de données de documents telles que mongodb, qui ont colonnes Les bases de données distribuées sont représentées par HBase, cassandra, dynamo, ainsi que d'autres bases de données graphiques, bases de données d'objets, bases de données xml, etc. Les domaines d'activité de chaque type d'application de base de données sont différents. Ce qui suit est une analyse des performances, de la disponibilité et d'autres aspects des produits associés à partir des trois dimensions de la mémoire, relationnelle et distribuée. nosqlBase de donnéesmongodb, redis par exemple Méthode de communication IO commutation). Structure des données -->collection-->record est divisé en espaces de noms dans le stockage de données. Une collection est un espace de noms, tout comme un index. Un espace de noms. Étendue, et Étendue sont connectées à l'aide d'une liste doublement chaînée. étendue, des données spécifiques de chaque ligne sont enregistrées, et ces données sont également connectées via des liens bidirectionnels. Chaque rangée d'espace de stockage de données comprend non seulement l'espace occupé par les données, mais peut également inclure une partie de l'espace supplémentaire, ce qui permet à la position de ne pas être déplacée une fois que la mise à jour des données devient plus grande. L'index est implémenté dans la structure BTree. Si vous activez le journal jorunaling, certains fichiers stockeront également tous vos enregistrements d'opération. Stockage persistant MMap mappe les adresses de fichiers à la mémoire Espace d'adressage , vous pouvez utiliser directement l'espace d'adressage de la mémoire pour faire fonctionner des fichiers, sans appeler d'opérations écriture, lecture, les performances sont relativement élevées. mongodb appelle mmap pour mapper les données du disque vers la mémoire, il doit donc y avoir un mécanisme pour vider les données vers le disque dur à tout moment. Pour garantir la fiabilité, la fréquence de brossage est liée au paramètre syncdelay. Le journal (pour la récupération) est le redo log dans Mongodb, et Oplog se charge de copier binlog. Si le journal est allumé, même si l'alimentation est coupée, seulement 100 ms de données seront perdues, ce qui est tolérable pour la plupart des applications. À partir de 1.9.2+, mongodb activera la fonction journal par défaut pour assurer la sécurité des données. Et le temps de rafraîchissement du journal peut être modifié, dans la plage de 2 à 300 ms, utilisez la commande --journalCommitInterval . Le temps nécessaire à l'actualisation de Oplog et des données sur le disque est de 60 s Pour la réplication, il n'est pas nécessaire d'attendre que oplog actualise le disque, et il peut le faire. être copié directement dans le nœud Secondary. Prise en charge des transactions Prend uniquement en charge les opérations atomiques sur les enregistrements à une seule ligne HACluster Replica Sets, qui utilise un algorithme d'élection pour automatiquement effectuer l'élection du leader permet de répondre à de fortes exigences de cohérence tout en garantissant la disponibilité. mongodb fournit également Architecture de partage de donnéesPartage. Méthode de communication CPU, il s'agit donc d'un mode monothread (thread de traitement logique et le le fil principal est le même). Mode réacteur, implémentez votre propre mécanisme de multiplexage NIO (epoll, select, kqueue, etc.) Traitement multi-tâches à thread unique Structure de données structure hash+bucket, lorsque la longueur de la liste chaînée est trop longue, des mesures de migration seront prises (en agrandissant l'original deux fois du hash table, Migrez les données là-bas, développez+rehash) persistant stockage a, persistance complète RDB (traverse redisDB, lire clé, valeurbucket 🎜>), la commande save bloque le thread principal, et la commande bgsave démarre le sous-processus pour effectuer l'opération de persistance instantané et générer le rdb fichier. Lors de l'arrêt, l'opération sauvegarder sera appelée Lorsque les données changent, combien de secondes cela va-t-il déclencher ? La commande émise b, persistance incrémentielle (aof est similaire à redolog ), écrivez d'abord dans le journal buffer, puis flush dans le fichier journal (la stratégie de peut être configuré, soit individuellement, soit par lots), uniquement flush dans le fichier avant qu'il ne soit effectivement renvoyé au client. Assurez-vous de vérifier régulièrement Les fichiers aof et rdb sont fusionnés (pendant le processus d'instantané, les données modifiées sont d'abord écrites dans aof buf, puis le processus enfant termine l'instantané<Mémoireinstantané> aofbuf et les données complètes de l'image). En mode d'accès simultané élevé, RDB provoque une instabilité évidente dans les indicateurs de performance du service aof est meilleur que RDB en termes de surcharge de performances, mais le rechargement prend du temps et du volume de données. mémoire pendant la récupération. Directement proportionnelle. ClusterHA La solution courante est la commutation de sauvegarde maître-esclave, à l'aide du logiciel HA afin que le maître redis défaillant puisse être rapidement basculé vers l'esclave redis. La synchronisation des données maître-esclave adopte le mécanisme de réplication, et ce scénario peut séparer la lecture et l'écriture. Actuellement, un problème avec la réplication est que lorsque le réseau est instable, EsclaveDéconnexion (y compris la déconnexion flash ) de Maître amènera Maître à régénérer toutes les données de la mémoire dans un fichier rdb (fichier instantané), puis à le transférer vers Esclave . Après que Esclave ait reçu le fichier rdb transmis par Maître, il effacera sa propre mémoire et rechargera le fichier rdb dans la mémoire. Cette méthode est relativement inefficace. Dans la future version Redis2.8, l'auteur a implémenté une fonction de copie partielle. Tout en satisfaisant les performances de concurrence, la base de données relationnelle doit également répondre à la transactionnalité de mysqlLa base de données est prise à titre d'exemple pour décrire les principes de la conception architecturale, les considérations en matière de performances et la manière de répondre aux exigences de disponibilité. Ø Les principes architecturaux de mysql(innodb) En termes d'architecture, mysql points Pour la couche serveur et la couche moteur de stockage. L'architecture de la couche Serveur est la même pour les différents moteurs de stockage, y compris les connexions/ Traitement des threads, traitement des requêtes (analyseur , optimiseur) et autres tâches système. Il existe de nombreuses couches de moteur de stockage. mysql fournit une structure de plug-in pour les moteurs de stockage et prend en charge plusieurs moteurs de stockage. Les plus largement utilisés sont innodb et myisamin. ;inodb est principalement destiné aux applications OLTP et prend en charge le traitement des transactions myisam ne prend pas en charge les transactions et les verrous de table. Il fonctionne rapidement sur OLAP. . Ce qui suit présente principalement le moteur de stockage innodb. En termes de traitement des threads, Mysql est une architecture multithread, composée d'un thread maître, d'un thread de surveillance des verrous, d'un thread de surveillance des erreurs et de plusieurs IOComposition du fil. Et un fil de discussion sera ouvert pour qu'une connexion soit établie. Le fil io est divisé en insert buffer pour enregistrer des IO aléatoires et un redo log similaire à oracle pour le contrôle des transactions , ainsi que plusieurs threads écriture, plusieurs lecture IO pour l'échange de disque dur et de mémoire. En termes d'allocation de mémoire, y compris le pool de tampons innodb et le tampon de journal. Parmi eux, le pool de tampons Innodb comprend un tampon d'insertion, une page de données, une page d'index, un dictionnaire de données et un hachage. Log buffer est utilisé pour mettre en cache les journaux de transactions afin d'améliorer les performances. innodb comprend un espace table, un segment, une zone, un bloc de page / et une ligne. La structure d'index est une structure B+tree, comprenant un index secondaire et un index de clé primaire. Le nœud feuille de l'index secondaire est la clé primaire PK, et le nœud feuille est indexé en fonction. la clé primaire pointe vers le bloc de données stocké. Cette structure de stockage arborescente B+ peut mieux répondre aux exigences IO des opérations de requête aléatoires. Elle est divisée en pages de données et pages d'index secondaires. La modification des pages d'index secondaires implique des opérations aléatoires. Pour améliorer les performances d'écriture, utilisez insert buffer pour effectuer une écriture séquentielle, puis le thread d'arrière-plan fusionnera plusieurs insertions dans la page d'index secondaire à une certaine fréquence. Afin d'assurer la cohérence de la base de données(fichiers de données mémoire et disque dur), et de raccourcir le temps de récupération de l'instance, la base de données relationnelle dispose également d'un point de contrôle fonction, utilisez Pour écrire les pages sales précédentes dans la mémoire tampon sur le disque proportionnellement au (ancien LSN), de sorte que le redolog du fichier LSNLe journal précédent peut être écrasé et recyclé ; lors de la récupération après échec, il vous suffit de récupérer à partir du point LSN dans le journal. En termes de prise en charge des fonctionnalités de transaction, les bases de données relationnelles doivent répondre aux quatre fonctionnalités de ACID. Différents niveaux d'isolation des transactions doivent être définis en fonction des différentes exigences de simultanéité des transactions et de visibilité des données, et ils sont indissociables de. Le mécanisme de verrouillage pour les conflits de ressources consiste à éviter les blocages. mysql effectue un contrôle de concurrence au niveau de la couche Serveur et du moteur de stockage, principalement reflété dans les verrous en lecture-écriture en fonction de la granularité du verrouillage. , il existe des verrous à différents niveaux (verrouillage de table, verrouillage de ligne, verrouillage de page, MVCC) basé sur la prise en compte de l'amélioration des performances de concurrence, du contrôle de concurrence multi-version MVCC ; est utilisé pour prendre en charge L'isolation des transactions est implémentée sur la base de annuler Lors de l'annulation d'une transaction, le segment annuler sera également utilisé. mysql Utilisez redolog pour garantir les performances d'écriture des données et la récupération après échec. Lors de la modification des données, il vous suffit de modifier la mémoire, puis d'enregistrer la modification dans le journal des transactions (SéquentielIO), il n'est pas nécessaire de conserver la modification des données elle-même sur le disque dur à chaque fois(AléatoireIO), ce qui améliore considérablement les performances. En termes de fiabilité, innodbLe moteur de stockage fournit un mécanisme d'écriture doubledouble écrivain pour éviter les erreurs de vidage des pages vers le stockage et résoudre le problème de demi-écriture du disque . Ø Pour une simultanéité élevée et des performances élevées mysql De manière générale, le réglage des performances peut être effectué dans plusieurs dimensions. a, niveau matériel, Le stockage des journaux et des données doit être séparé. Les journaux sont écrits séquentiellement et doivent être effectués <.>raid1 +0, et utilisez buffer-IO ; les données sont lues et écrites discrètement, utilisez simplement direct IO pour éviter les problèmes causés par l'utilisation du système de fichiers cache des frais généraux. SASdisqueraid ( raid cache de la carte, désactivez la lecture du cache, désactivez le cache du disque, désactivez la lecture anticipée, utilisez uniquement le tampon d'écriture, mais vous devez prendre en compte le problème de charge et de décharge), bien sûr, si l'échelle de données n'est pas grande, des appareils à grande vitesse peuvent être utilisés pour le stockage de données, tels que Fusion IO et SSD . accès au cache par conséquent, estimez les IOPS requis par le système et évaluez-les ; les besoins Le nombre de disques durs (fusion io jusqu'à IOPS est supérieur à 10w , disques durs ordinaires 150) . En termes de Cpu, une instance unique désactive NUMA et mysql ne prend pas très bien en charge le multicœur. Plusieurs instances peuvent être liées au CPU. . b. Optimisation du niveau du système d'exploitation, noyau et socket , optimisation du réseau bond, système de fichiers, IO planification innodb est principalement utilisé dans Les applications OLTP sont généralement des applications intensives en IO Sur la base de l'amélioration des capacités IO, elles utilisent pleinement le mécanisme de cache. Les éléments à considérer sont : Sur la base de la garantie de la mémoire disponible du système, essayez autant que possible L'expansion du pool de tampons innodb est généralement définie sur 3/4 de la mémoire physique du système de fichiers. est utilisé uniquement pour enregistrer les journaux de transactions. Lorsque vous utilisez le cache du système de fichiers ; essayez d'éviter mysql d'utiliser swap (vous pouvez définir vm.swappiness=0 pour libérer le système de fichiers lorsque la mémoire est limitée) cache) optimisation de la planification, réduction des blocages inutiles et réduction du caractère aléatoire IOLatence d'accès(CFQ, Date limite, NOOP) niveau serveur et moteur de stockage (gestion des connexions, gestion du réseau, gestion des tables, log) cache/buffer, Connexion, IO schéma avec une redondance appropriée ; l'optimisation des problèmes de CPU et les problèmes de mémoire causés par sql requêtes, pour réduire la portée des verrous, réduire les analyses de table arrière, couvrir les index) maître-maître, maître-esclave, le mode maître-maître est celui qui est responsable de la lecture et de l'écriture en tant que maître , et l'autre est responsable de la reprise après sinistre en tant que veille maser-slave est celui qui fournit des opérations d'écriture en tant que maître, et plusieurs autres nœuds servent d'opérations de lecture, prenant en charge la lecture et l'écriture. séparation. peut être utilisé Le logiciel HA, bien sûr, peut également utiliser zookeeper comme service de coordination du cluster dans la perspective d'une personnalisation plus fine. . , méthode de clustering, comme le rack de oracle, l'inconvénient est qu'il est plus compliqué b, méthode de stockage SAN partagée, les fichiers de données associés et les fichiers journaux sont placés sur le stockage partagé. L'avantage est que les données restent cohérentes pendant le basculement actif/veille et ne seront pas perdues. . Cependant, en raison de la sauvegarde, si la machine est arrêtée pendant un certain temps, elle sera temporairement indisponible c Les méthodes principales et de sauvegarde pour. synchronisation des données, la synchronisation courante des journaux peut être assurée et les performances en temps réel sont bonnes, mais pendant la commutation, certaines données peuvent ne pas être synchronisées, provoquant des problèmes de cohérence des données. Vous pouvez enregistrer le journal des opérations pendant l'utilisation de la base de données principale. Lors du passage en veille, il vérifiera avec le journal des opérations pour compenser les données non synchronisées d. Une autre façon consiste à basculer la base de données de secours vers le stockage de regolog de la base de données principale pour garantir que les données ne sont pas perdues. L'efficacité de la réplication maître-esclave de la base de données n'est pas trop élevée sur mysql La raison principale est que les transactions maintiennent strictement l'ordre et l'index . 🎜>mysqlEn termes de réplication, y compris logIO et relog log, les deux processus sont des opérations série à thread unique. En termes d'optimisation de la copie de données, essayez de réduire <.>IO influencer autant que possible. Cependant, avec la version Mysql5.6, la réplication parallèle sur différentes bibliothèques peut être prise en charge. sharding est utilisé comme maître pour plusieurs lectures. De même, pour les commandes, puisque les utilisateurs ont davantage besoin d'interroger leurs propres commandes, la base de données des commandes doit également être segmentée en fonction des utilisateurs, et soutient un Seigneur en savoir plus. est adoptée Stockage ; Pour les fichiers de données, il y aura un grand nombre d'opérations de lecture et d'écriture aléatoires pour les utilisateurs ou les commandes. Bien sûr, l'augmentation de la mémoire est un aspect. De plus, la vitesse élevée . La mémoire flash du périphérique IO peut être utilisée, telle que la PCIeCarte fusion-io. L'utilisation de la mémoire flash convient également aux charges de travail monothread, telles que la réplication maître-esclave. Vous pouvez configurer la carte fusion-IO sur le nœud esclave pour réduire la latence de réplication. Pour les affaires de commandes, le volume est en constante augmentation, la capacité de stockage de la carte est relativement limitée et les données chaudes des affaires de commande ne concernent que la dernière période(par exemple, les derniers3 mois), à droite Il existe deux solutions répertoriées ici. L'une est la méthode flashcache, qui utilise une méthode de stockage hybride open source basée sur la mémoire flash et le stockage sur disque dur pour stocker les données de point d'accès dans la mémoire flash. Une autre méthode consiste à exporter régulièrement les anciennes données vers la base de données distribuée HBase Lorsque les utilisateurs interrogent la liste de commandes, les données récentes sont obtenues à partir de mysql et les anciennes données peuvent être obtenues à partir de <.>HBase. Les requêtes dans 🎜>HBase nécessitent certainement une bonne conception rowkey de HBase pour s'adapter aux besoins des requêtes. Pour un accès hautement simultané aux données, les bases de données relationnelles traditionnelles fournissent une solution de séparation en lecture-écriture, mais cela entraîne des problèmes de cohérence des données fournis par la solution de segmentation des données de plus en plus massive ; les données, les bases de données traditionnelles utilisent des sous-bases de données et des sous-tables, qui sont plus compliquées à mettre en œuvre et nécessitent une migration et une maintenance continues dans la période ultérieure pour une haute disponibilité et une mise à l'échelle, les données traditionnelles utilisent le mode de veille principal, le mode de veille et le mode maître-esclave, solution multi-maître, mais son évolutivité est relativement faible. L'ajout de nœuds et les temps d'arrêt nécessitent une migration des données. Pour les problèmes soulevés ci-dessus, la base de données distribuée HBase dispose d'un ensemble complet de solutions adaptées aux exigences d'accès massif aux données à haute concurrence. Ø HBase Le stockage efficace basé sur des colonnes réduit les IO Hautes performances Arbre LSM Convient aux scénarios d'écriture à grande vitesse Accès aux données fortement cohérent MVCC L'accès cohérent aux données de HBase se fait via MVCC à réaliser. HBase doit passer par plusieurs étapes dans le processus d'écriture des données, l'écriture de HLog, l'écriture de memstore, La mise à jour MVCC; >L'écriture est réussie et l'isolation des transactions doit être contrôlée par mvcc Par exemple, la lecture des données ne peut pas obtenir des données qui n'ont pas été soumises par d'autres threads. Haute fiabilitéLe stockage des données de HBase est basé sur HDFS , fournit un mécanisme de redondance. Le temps d'arrêt du nœud Région fournit un mécanisme de récupération fiable pour les données en mémoire qui n'ont pas été vidées Segmentation, migration automatique et évolutive Serveur de région , et enfin localisez la .
Region Server se développe en se publiant sur Master, Master de manière uniforme distribué. DisponibilitéIl y a un seul point de défaillance, Serveur de région Après le temps d'arrêt, la région maintenue par le sera inaccessible pendant une courte période, en attendant que le prenne effet. maintient l'état de santé de chaque Serveur de région via MaîtreetRégiondistribution. Plusieurs Maître, Maître est en panne et il y a un mécanisme de vote paxos du zookeeper pour sélectionner le prochain Maître . Même si Master est complètement en panne, la lecture et l'écriture de Région ne seront pas affectées. Maître n'agit que comme un rôle d'exploitation et de maintenance automatique. HDFS est un moteur de stockage distribué avec une sauvegarde et trois sauvegardes, une haute fiabilité et 0 perte de données. Le namenode de HDFS est un SPOF. Pour éviter des accès trop fréquents à une seule région et une pression excessive sur une seule machine, un mécanisme de split est fourni HBase est écrit dans l'architecture de LSM-TREE Comme les données sont append, <.>HFileDe plus en plus, HBase fournit des fichiers HFile pour compact pour effacer les données expirées et améliorer les performances des requêtes. Sans schéma HBase n'a pas de schéma strict comme une base de données relationnelle, et vous pouvez librement ajouter et supprimer des champs dans le schéma. HBaseLa base de données distribuée ne prend pas très bien en charge l'index secondaire. Actuellement, elle ne prend en charge que rowkey rowkey est très critique pour les performances de la requête. 7. Configuration de gestion et de déploiementBibliothèque de configuration unifiée Plateforme de déploiement 8. Surveillance et statistiques Les systèmes distribués à grande échelle impliquent divers appareils, tels que des commutateurs réseau, des PCMachines, divers types de cartes réseau, disques durs, mémoires, etc., ainsi que surveillance des applications au niveau de l'entreprise. Lorsque le nombre est très important, la probabilité d'erreurs augmente et certaines exigences de surveillance sont relativement élevées, et d'autres. ont atteint le deuxième niveau ; les données anormales doivent être filtrées à partir d'une grande quantité de flux de données, et parfois des calculs complexes liés au contexte sont effectués sur les données pour déterminer si une alarme est nécessaire. Par conséquent, les performances, le débit et la disponibilité de la plateforme de surveillance sont plus importants. Il est nécessaire de planifier une plateforme de surveillance unifiée et intégrée pour surveiller le système à tous les niveaux. Classification des données de la plateforme métriques commerciales CPU, mémoire, réseau, IO Exigences de délais Seuil, alarme : Calcul en temps réel : Analyse hors ligne par heure et par jourRequête en temps réel Architecture L'agent Agent agent Les données sont collectées uniformément via le cluster collecteur et distribuées à différents clusters informatiques pour être traitées en fonction de différents types de données ; certaines données ne sont pas ponctuelles, comme les statistiques horaires, et sont placées dans ; cluster hadoop ; certaines données suivent les données du flux de requêtes et doivent être interrogées, elles peuvent ensuite être placées dans le cluster solr pour l'indexation ; certaines données doivent être calculées en temps réel puis alertées ; , il doit être mis en storm et traité dans le cluster. Une fois les données traitées par le cluster informatique, les résultats sont stockés dans Mysql ou HBaseIn. L'application de surveillance web peut transmettre les résultats de la surveillance en temps réel au navigateur et peut également fournir une API Pour l'affichage et la recherche de résultats. 3. Disponibilité multidimensionnelle
1) Équilibrage de charge, reprise après sinistre, Sauvegarde
2) Séparation en lecture et en écriture
3) Dépendances
4) Surveillance
4. Étirement
1) Divisé
2) Sans état
5. Optimiser l'utilisation des ressources
1) La capacité du système est limitée
2) Opérations atomiques et contrôle de la concurrence
3) En fonction de différentes logiques, adopter différentes stratégies
4) Isolation tolérante aux pannes
5) Libération des ressources
2. Plan d'architecture statique
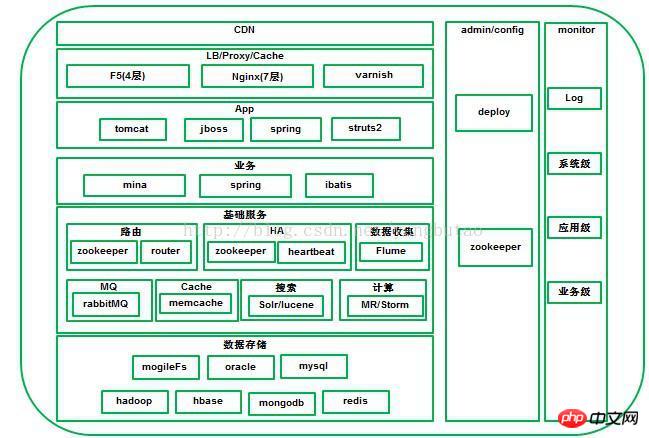
3. Architecture d'analyse
1. CDN
2. Équilibrage de charge, proxy inverse
3. AppAccès
4.

2) RouteurRouteur

Pour l'interaction asynchrone entre les différents systèmes de la plateforme, elle s'effectue via le composant
MQSystème
La recherche est une fonction très importante dans les plateformes de commerce électronique. Elle comprend principalement la navigation par catégorie de mots de recherche, les invites automatiques et les fonctions de tri de recherche.


8) Synchronisation des données


9) Analyse des données
10) Informatique en temps réel

Réel- application time push Il existe de nombreux scénarios, tels que le dessin de courbes en temps réel de la dynamique de surveillance du système, le push de messages sur téléphone mobile, le chat en temps réel
web12) Moteur de recommandation
6. Stockage des données

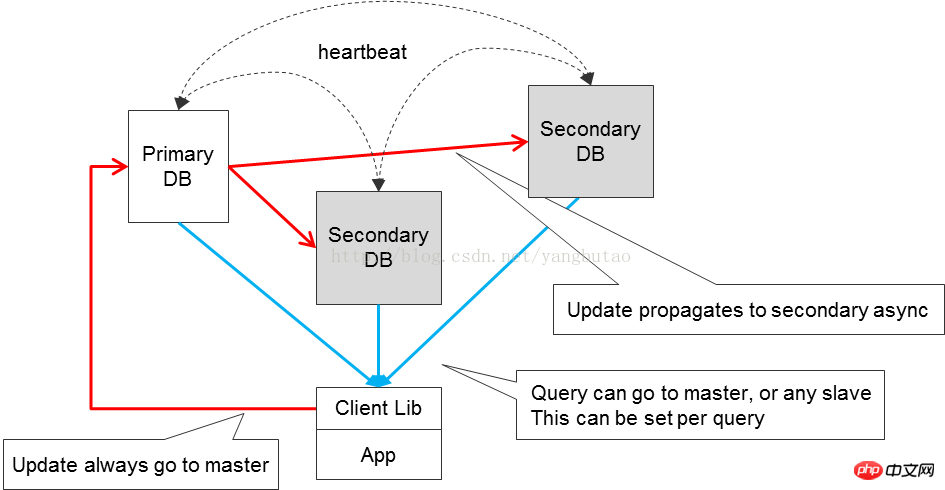
2) Base de données relationnelle

3) Base de données distribuée
Les requêtes habituelles ne nécessitent pas tous les champs d'affilée . La plupart ne nécessitent que quelques champs
Par rapport aux systèmes de stockage orientés lignes, toutes les données seront récupérées pour chaque requête, puis les champs requis seront sélectionnés parmi eux
Les systèmes de stockage orientés colonnes peuvent interroger une colonne séparément, réduisez ainsi considérablementIO
Améliorez l'efficacité de la compression
Les données dans la même colonne ont une grande similarité, ce qui augmentera l'efficacité de la compression
De nombreuses fonctionnalités de Hbase sont déterminées par le stockage en colonne
 cible via
cible via 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!