
Maison >base de données >tutoriel mysql >Connaissez-vous l'optimisation des performances des bases de données Mysql ?
Connaissez-vous l'optimisation des performances des bases de données Mysql ?

- 怪我咯original
- 2017-07-05 11:19:511511parcourir
Aujourd'hui, les opérations de base de données deviennent de plus en plus le goulot d'étranglement des performances de l'ensemble de l'application, en particulier pour les applications Web. Concernant les performances de la base de données, ce n'est pas seulement quelque chose dont les administrateurs de base de données doivent s'inquiéter, mais c'est aussi quelque chose auquel nos programmeurs doivent prêter attention
Aujourd'hui, les opérations de base de données sont de plus en plus devenues le goulot d'étranglement des performances du l’ensemble de l’application. Cela est particulièrement vrai pour les applications Web. Concernant les performances de la base de données, ce n’est pas seulement quelque chose dont les administrateurs de base de données doivent s’inquiéter, mais c’est aussi quelque chose auquel nous, les programmeurs, devons prêter attention. Lorsque nous concevons la structure des tables de la base de données, nous devons tous prêter attention aux performances des opérations sur les données lors de l'exploitation de la base de données (en particulier les instructions SQL lors de la recherche de tables). Ici, nous ne parlerons pas trop de l’optimisation des instructions SQL, mais nous concentrerons uniquement sur MySQL, la base de données comportant le plus d’applications Web.
L'optimisation des performances de MySQL ne peut pas être réalisée du jour au lendemain. Vous devez procéder étape par étape et optimiser sous tous les aspects, et les performances finales seront grandement améliorées.
Base de données MySQL Technologie d'optimisation
L'optimisation Mysql est une technologie complète, comprenant principalement
•Rationalisation de la conception des tables (conforme à 3NF)
•Ajouter un index approprié (index) [quatre types : index ordinaire, index de clé primaire, index unique, complet index de texte]
•Technologie de fractionnement de table (séparation horizontale, division verticale)
•Lire et écrire [écrire : mettre à jour/supprimer/ajouter] séparation
•Procédure de stockage [Programmation modulaire, peut améliorer la vitesse]
• Optimiser la configuration MySQL [Configurer le nombre maximum de concurrence my.ini, ajuster la taille du cache ]
•Mise à niveau matérielle du serveur MySQL
•Effacez régulièrement les données inutiles et défragmentez régulièrement (MyISAM)
Travail d'optimisation de la base de données
Pour une application centrée sur les données, la qualité de la base de données affecte directement les performances du programme, les performances de la base de données sont donc cruciales. De manière générale, pour assurer l'efficacité de la base de données, les quatre aspects suivants doivent être réalisés :
① Conception de la base de données
② Optimisation des instructions SQL
③ Configuration des paramètres de la base de données
④ Ressources matérielles et système d'exploitation appropriés
De plus, l'utilisation de procédures stockées appropriées peut également améliorer les performances.
Cette commande montre également l'impact de ces quatre tâches sur les performances
Conception des tables de base de données
Une compréhension commune des trois paradigmes est très bénéfique pour la conception de bases de données. Dans la conception de bases de données, afin de mieux appliquer les trois paradigmes, il est nécessaire de comprendre les trois paradigmes d'une manière populaire (la compréhension populaire est une compréhension suffisante, pas la compréhension la plus scientifique et la plus précise) :
Première forme normale : 1NF est une contrainte d'atomicité sur les attributs, qui nécessite que les attributs (colonnes) soient atomiques et ne peuvent pas être décomposés (tant qu'il s'agit d'une
, elle satisfait 1NF) Deuxième forme normale : 2NF est la contrainte d'unicité sur les enregistrements, exigeant que les enregistrements aient des identifiants uniques, c'est-à-dire l'unicité des entités
Troisième forme normale : 3NF est la restriction sur l'unicité des enregistrements. Contraintes de redondance des champs, qui exigent que les champs ne soient pas redondants. Aucune conception de base de données redondante ne peut faire cela.
Cependant, une base de données sans redondance n'est peut-être pas la meilleure base de données. Parfois, afin d'améliorer l'efficacité opérationnelle, il est nécessaire d'abaisser la norme du paradigme et de conserver de manière appropriée les données redondantes. L'approche spécifique est la suivante : respecter le troisième paradigme lors de la conception de modèles de données conceptuels et prendre en compte le travail d'abaissement des normes de paradigme lors de la conception de modèles de données physiques. Réduire le formulaire normal signifie ajouter des champs et autoriser la redondance.
☞ Classification des bases de données
Base de données relationnelle : mysql/oracle/db2/informix/sysbase/sql server
Base de données non relationnelle : (Caractéristiques :
Orienté objet
Base de données NoSql : MongoDB (généralement orientée document)
Donnez un exemple de ce qu'est un licenciement modéré, ou un licenciement justifié !
 Ce qui précède est un licenciement inapproprié car :
Ce qui précède est un licenciement inapproprié car :
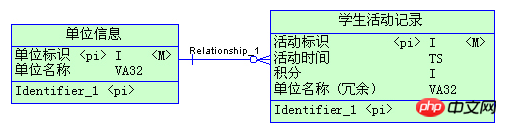
Ici, afin d'améliorer l'efficacité de la récupération des enregistrements d'activité des étudiants, le nom de l'unité est ajouté de manière redondante au tableau des enregistrements d'activité des étudiants. Il existe 500 enregistrements d'informations sur les unités et les enregistrements d'activités des étudiants
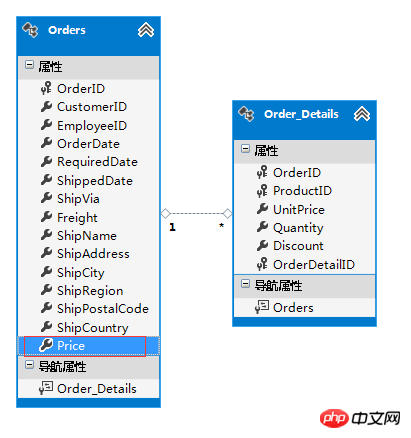
Le prix dans le tableau des commandes est un champ redondant, car nous pouvons calculer le prix de cette commande à partir du tableau des détails de la commande, mais cette redondance est raisonnable et peut également améliorer les performances des requêtes.
Une conclusion peut être tirée des deux exemples ci-dessus :
1 --- n redondance devrait se produire du côté 1.
Optimisation des instructions SQL
Étapes générales pour l'optimisation SQL
1. La commande status comprend la fréquence d’exécution de divers SQL.
2. Localisez les instructions SQL avec une faible efficacité d'exécution - (accent sur la sélection)
3. Analysez le SQL inefficace en expliquant
4. .Déterminez le problème et prenez les mesures d'optimisation correspondantes
-- select语句分类 Select Dml数据操作语言(insert update delete) dtl 数据事物语言(commit rollback savepoint) Ddl数据定义语言(create alter drop..) Dcl(数据控制语言) grant revoke -- Show status 常用命令 --查询本次会话 Show session status like 'com_%'; //show session status like 'Com_select' --查询全局 Show global status like 'com_%'; -- 给某个用户授权 grant all privileges on *.* to 'abc'@'%'; --为什么这样授权 'abc'表示用户名 '@' 表示host, 查看一下mysql->user表就知道了 --回收权限 revoke all on *.* from 'abc'@'%'; --刷新权限[也可以不写] flush privileges;
Paramètres d'optimisation des instructions SQL
Client MySQL Après un succès. connexion, les informations sur l'état du serveur peuvent être fournies à l'aide de la commande show [session|global] status. La session représente les résultats statistiques de la connexion actuelle et global représente les résultats statistiques depuis le dernier démarrage de la base de données. La valeur par défaut est le niveau de la session.
L'exemple suivant :
afficher le statut comme 'Com_%';
où Com_XXX représente le nombre de fois où l'instruction XXX a été été exécuté.
Remarque importante : Com_select, Com_insert, Com_update, Com_delete. Grâce à ces paramètres, vous pouvez facilement comprendre si l'application de base de données actuelle est principalement basée sur des opérations d'insertion et de mise à jour ou des opérations de requête, ainsi que divers types. de Quel est le taux d'exécution approximatif de SQL.
Il existe également plusieurs paramètres couramment utilisés pour aider les utilisateurs à comprendre la situation de base de la base de données.
Connexions : Le nombre de tentatives de connexion au serveur MySQL
Uptime : La durée pendant laquelle le serveur fonctionne (en secondes)
Slow_queries : Requêtes lentes Nombre de fois (la valeur par défaut est un temps de requête lent de 10 s)
show status like 'Connections' show status like 'Uptime' show status like 'Slow_queries'
Comment interroger le temps de requête lent de MySQL
Show variables like 'long_query_time';
Modifier le temps de requête lent de MySQL
set long_query_time=2
Optimisation des instructions SQL - localisation des requêtes lentes
La question est : comment localiser rapidement les instructions à exécution lente dans un grand projet. (Localisation des requêtes lentes)
Tout d'abord, nous comprenons comment interroger un certain état d'exécution de la base de données mysql (par exemple, si vous voulez connaître la durée d'exécution actuelle de mysql/combien de fois il a été exécuté au total
select/update/delete.. / current Connection)
Pour faciliter les tests, nous construisons une grande table (4 millions) -> en utilisant une procédure stockée
show variables like 'long_query_time' ; //可以显示当前慢查询时间 set long_query_time=1 ;//可以修改慢查询时间Construire une grande table->Il existe des exigences pour les enregistrements dans les grandes tables, et les enregistrements sont différents. C'est utile, sinon l'effet du test est très différent du réel Créer :
CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/ loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/ ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8;Données de test
Pour que la procédure stockée s'exécute normalement, nous devons modifier le délimiteur de caractères de fin d'exécution de la commande $$
INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999);Créer une fonction qui renverra une chaîne aléatoire de longueur spécifiée
create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串 begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; endÀ ce moment-là, si une instruction prend plus d'une seconde à s'exécuter, elle sera comptée
create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; #set autocommit =0 把autocommit设置成0 set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand()); until i = max_num end repeat; commit; end #调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp(100001,4000000);
Si la requête lente SQL est enregistrée dans l'un de nos journaux
Par défaut, les versions inférieures de MySQL n'enregistreront pas les requêtes lentes. Vous devez spécifier l'enregistrement des requêtes lentes lorsque. démarrage de mysql
binmysqld.exe - -safe-mode - -slow-query-log [mysql5 .5 peut être spécifié dans my.ini]
binmysqld.exe –log-slow-queries=d:/abc.log [la version inférieure de mysql5.0 peut être spécifiée dans my.ini]
Le journal des requêtes lentes sera placé dans le répertoire de données [dans mysql5 .0, il sera placé dans le répertoire d'installation de mysql/data/]. Sous mysql5.5.19, vous devez le visualiser
My.ini's datadir="C:/Documents and Settings/ Tous les utilisateurs/Données d'application/MySQL/MySQL Server 5.5/Data/" à déterminer.
Dans mysql5.6, la valeur par défaut est de démarrer la journalisation lente des requêtes. Le répertoire où se trouve my.ini est : C:ProgramDataMySQLMySQL Server 5.6, qui a un élément de configuration
slow-query-log=1
Il existe deux façons de démarrer une requête lente pour mysql5.5
binmysqld.exe - -safe-mode - -slow-query-log
peut également être utilisé dans ma configuration dans le fichier .ini :
Localisez les instructions SQL avec une faible efficacité d'exécution grâce à des journaux de requêtes lents. Le journal des requêtes lentes enregistre toutes les instructions SQL dont le temps d'exécution dépasse le paramètre long_query_time.
[mysqld] # The TCP/IP Port the MySQL Server will listen on port=3306 slow-query-log
Ajouter des données à la table dept
show variables like 'long_query_time'; set long_query_time=2;
****Instruction de test***[L'enregistrement de la table emp peut être 3600000, l'effet est évidemment lent]
desc dept; ALTER table dept add id int PRIMARY key auto_increment; CREATE PRIMARY KEY on dept(id); create INDEX idx_dptno_dptname on dept(deptno,dname); INSERT into dept(deptno,dname,loc) values(1,'研发部','康和盛大厦5楼501'); INSERT into dept(deptno,dname,loc) values(2,'产品部','康和盛大厦5楼502'); INSERT into dept(deptno,dname,loc) values(3,'财务部','康和盛大厦5楼503');UPDATE emp set deptno=1 where empno=100002;
Si vous passez commande par e.empno, la vitesse sera encore plus lente, parfois plus d'1 minute.
select * from emp where empno=(select empno from emp where ename='研发部')
Déclaration de test
Voir le journal des requêtes lentes : la valeur par défaut est host-name-slow.log dans les données du répertoire de données. Les versions inférieures de MySQL doivent être configurées à l'aide de -log-slow-queries[=file_name] lors de l'ouverture de MySQL
select * from emp e,dept d where e.empno=100002 and e.deptno=d.deptno;
produira les informations suivantes :
Explain select * from emp where ename=“wsrcla”
select_type : Indique le type de requête.
table : La table qui génère l'ensemble de résultats
type : Représente le type de connexion de la table
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明

explain select * from emp where ename='JKLOIP'
如果要测试Extra的filesort可以对上面的语句修改
explain select * from emp order by ename\G
EXPLAIN详解
id
SELECT识别符。这是SELECT的查询序列号
id 示例
SELECT * FROM emp WHERE empno = 1 and ename = (SELECT ename FROM emp WHERE empno = 100001) \G;
select_type
PRIMARY :子查询中最外层查询
SUBQUERY : 子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY:子查询内层第一个SELECT,依赖于外部查询
UNION :UNION语句中第二个SELECT开始后面所有SELECT,
SIMPLE
UNION RESULT UNION 中合并结果
Table
显示这一步所访问数据库中表名称
Type
对表访问方式
ALL:
SELECT * FROM emp \G
完整的表扫描 通常不好
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system:表仅有一行(=系统表)。这是const联接类型的一个特
const:表最多有一个匹配行
Possible_keys
该查询可以利用的索引,如果没有任何索引显示 null
Key
Mysql 从 Possible_keys 所选择使用索引
Rows
估算出结果集行数
Extra
查询细节信息
No tables :Query语句中使用FROM DUAL 或不含任何FROM子句
Using filesort :当Query中包含 ORDER BY 操作,而且无法利用索引完成排序,
Impossible WHERE noticed after reading const tables: MYSQL Query Optimizer
通过收集统计信息不可能存在结果
Using temporary:某些操作必须使用临时表,常见 GROUP BY ; ORDER BY
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!