
Maison >Opération et maintenance >exploitation et maintenance Linux >Introduction détaillée à la configuration Heka
Introduction détaillée à la configuration Heka

- 零下一度original
- 2017-07-18 16:47:213052parcourir
Ce tutoriel Linux vous expliquera la configuration Heka et le processus de fonctionnement spécifique :
Architecture de journaux backend distribuée basée sur Heka, ElasticSearch et Kibana
Les journaux backend grand public actuels sont les Le mode wapiti standard (Elasticsearch, Logstash, Kinaba) est adopté, qui est respectivement responsable du stockage, de la collecte et de la visualisation des journaux.
Cependant, comme nos fichiers journaux sont divers et distribués sur différents serveurs, divers journaux sont utilisés pour faciliter le développement secondaire et la personnalisation à l'avenir. Par conséquent, Mozilla a adopté Heka, qui est implémenté en utilisant l'open source Golang et imite Logstash.
Architecture de journaux backend distribuée basée sur Heka, ElasticSearch et Kibana
Actuellement, les journaux backend traditionnels adoptent le mode elk standard (Elasticsearch, Logstash, Kinaba), qui sont respectivement responsables du stockage des journaux, de la collecte et visualisation du journal.
Cependant, comme nos fichiers journaux sont divers et distribués sur différents serveurs, divers journaux sont utilisés pour faciliter le développement secondaire et la personnalisation à l'avenir. Par conséquent, Mozilla a adopté Heka, qui est implémenté en utilisant l'open source Golang et imite Logstash.
Schéma d'architecture globale
L'architecture globale après utilisation de Heka, ElasticSearch et Kibana est présentée dans la figure ci-dessous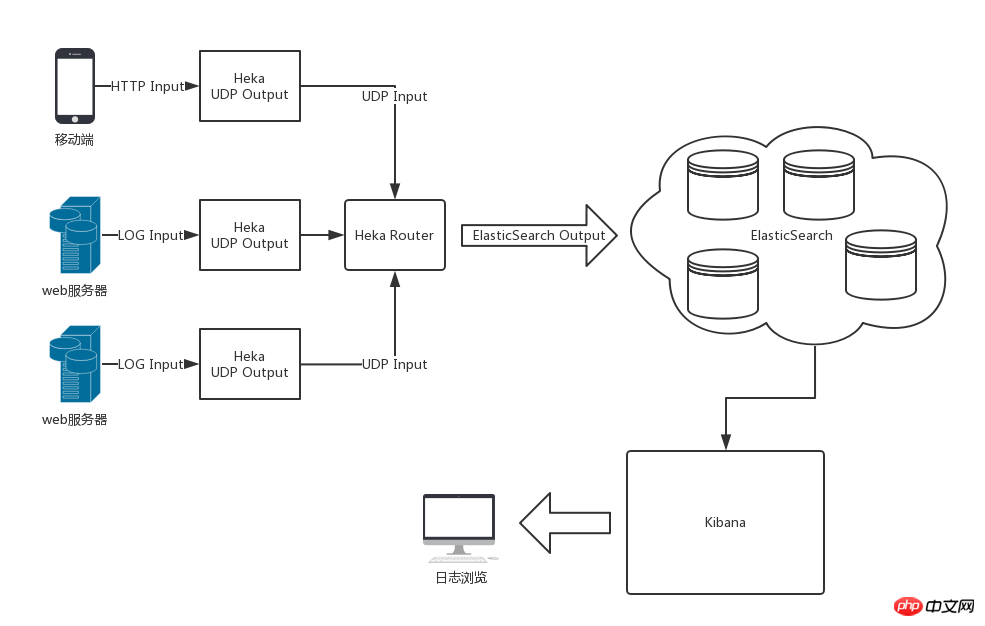
Article Heka
Introduction
Le flux de traitement des journaux de Heka comprend la segmentation des entrées, le décodage, le filtrage, l'encodage et la sortie. Le flux de données au sein d'un seul service Heka circule au sein de chaque module via le modèle de données Message défini par Heka.
Heka intègre les plug-ins de modules les plus couramment utilisés, tels que
Le plug-in d'entrée dispose d'une entrée Logstreamer, qui peut utiliser des fichiers journaux comme sources d'entrée. ,
Le plug-in de décodage Nginx Access Log Decoder peut décoder le journal d'accès nginx en données de paire clé-valeur standard et le transmettre au plug-in de module suivant pour traitement.
Grâce à la configuration flexible des entrées et des sorties, les données de journal collectées par Heka à divers endroits peuvent être traitées et transmises à Heka dans le centre de journalisation pour un codage unifié, puis transmises à ElasticSearch pour le stockage.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Apprenez à installer le serveur Nginx sous Linux
- Introduction détaillée à la commande wget de Linux
- Explication détaillée d'exemples d'utilisation de yum pour installer Nginx sous Linux
- Explication détaillée des problèmes de connexions des travailleurs dans Nginx
- Explication détaillée du processus d'installation de python3 sous Linux