
Maison >développement back-end >Tutoriel Python >Implémentation Python d'un exemple de tutoriel de moteur de recherche (Pylucene)
Implémentation Python d'un exemple de tutoriel de moteur de recherche (Pylucene)

- 零下一度original
- 2017-07-18 10:12:5213879parcourir
Document, classe de documents. L'unité de base de l'indexation dans Pylucene est le « Document ». Un document peut être une page Web, un article ou un e-mail. Le document est l'unité utilisée pour créer l'index et constitue également l'unité de résultat lors de la recherche. Une conception appropriée de celui-ci peut fournir des services de recherche personnalisés.
Déposé, classe de domaine. Un Document peut contenir plusieurs champs (Field). Classé est un composant du document, tout comme un article peut être composé de plusieurs fichiers tels que le titre de l'article, le corps de l'article, l'auteur, la date de publication, etc.
Traitez une page comme un document, qui contient trois champs : l'adresse URL de la page (url), le titre de la page (titre) et le contenu textuel principal du page (contenu). Pour la méthode de stockage de l'index, choisissez d'utiliser la classe SimpleFSDirectory pour enregistrer l'index dans un fichier. L'analyseur choisit CJKAnalyzer fourni avec Pylucene. Cet analyseur prend en charge le chinois et convient au traitement de texte du contenu chinois.
Qu'est-ce qu'un moteur de recherche ?
Le moteur de recherche est « un système qui collecte et organise les ressources d'informations du réseau et fournit des services de requête d'informations, comprenant trois parties : la collecte d'informations, le tri des informations et la requête des utilisateurs ». La figure 1 est la structure générale d'un moteur de recherche. Le module de collecte d'informations collecte des informations sur Internet dans la base de données d'informations du réseau (généralement à l'aide de robots d'exploration) ; informations collectées. Établissez une table d'index (généralement un index inversé) pour former une base de données d'index. Enfin, le module de requête utilisateur peut identifier les besoins de récupération de l'utilisateur et fournir des services de récupération.
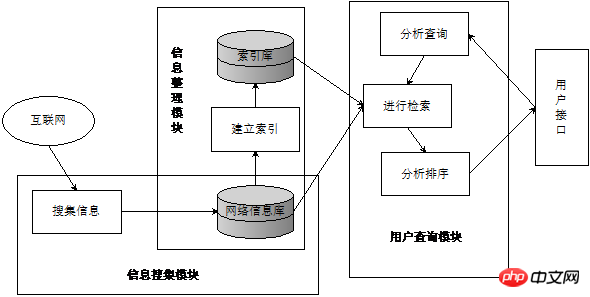
Figure 1 Structure générale du moteur de recherche
2. Utilisez Python pour implémenter un moteur de recherche simple
2.1 Analyse du problème
À partir de la figure 1, une architecture complète de moteur de recherche commence par la collecte d'informations sur Internet. Vous pouvez utiliser Python pour écrire un robot, ce qui est la force de Python.
Ensuite, le module de traitement de l'information. Participe? Des mots vides ? Tableau inversé ? quoi ? C'est quoi ce gâchis ? Ne vous inquiétez pas, nous avons la roue construite par nos prédécesseurs --- Pylucene (une version python de lucene. Lucene peut aider les développeurs à ajouter des fonctions de recherche aux logiciels et aux systèmes. Lucene est un ensemble de bibliothèques open source pour des applications complètes. récupération et recherche de texte) . L'utilisation de Pylucene peut simplement nous aider à traiter les informations collectées, y compris la création d'index et la recherche.
Enfin, afin d'utiliser notre moteur de recherche sur la page Web, nous utilisons flask, un framework d'application Web léger, pour créer une petite page Web afin d'obtenir des instructions de recherche et des commentaires sur les résultats de recherche.
2.2 Conception du robot
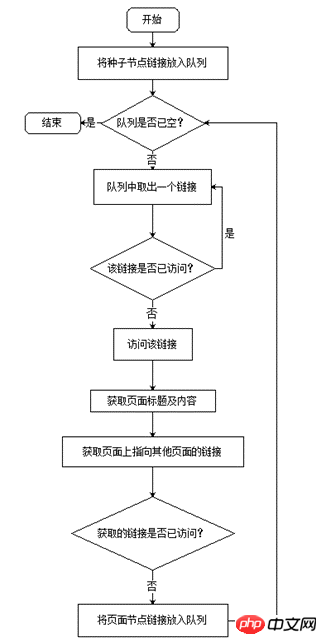
Collecte principalement le contenu suivant : le titre de la page Web cible, le contenu textuel principal de la page Web cible et les adresses URL des autres pages que le Web cible la page pointe vers. Le flux de travail du robot d'exploration Web est illustré à la figure 2. La structure de données principale du robot est la file d'attente. Tout d'abord, le nœud initial entre dans la file d'attente, puis retire un nœud de la file d'attente pour y accéder, récupère les informations cibles sur la page du nœud, puis place le lien URL de la page du nœud pointant vers d'autres pages dans la file d'attente, puis prend le nouveau nœud de la file d'attente est accessible jusqu'à ce que la file d'attente soit vide. Grâce à la fonctionnalité « premier entré, premier sorti » de la file d'attente, un algorithme de parcours en largeur est mis en œuvre pour accéder à chaque page du site une par une.
dexWriter, Document, Classé.
Directory est une classe pour les opérations sur les fichiers dans Pylucene. Il comporte 11 sous-classes telles que SimpleFSDirectory, RAMDirectory, CompoundFileDirectory et FileSwitchDirectory. Les quatre sous-classes répertoriées sont liées à l'enregistrement du répertoire d'index ; une méthode de sauvegarde d'index composée et FileSwitchDirectory permet un changement temporaire de la méthode de sauvegarde d'index pour tirer parti de diverses méthodes de sauvegarde d'index.
Analyseur, analyseur. C'est une classe qui traite le texte obtenu par le robot pour être indexé. Y compris des opérations telles que la segmentation des mots du texte, la suppression des mots vides et la conversion de la casse. Pylucene est livré avec plusieurs analyseurs, et vous pouvez également utiliser des analyseurs tiers ou des analyseurs auto-écrits lors de la création d'index. La qualité de l'analyseur est liée à la qualité de la construction de l'index ainsi qu'à la précision et à la rapidité que le service de recherche peut fournir.
IndexWriter, classe d'écriture d'index. Dans l'espace de stockage ouvert par Directory, IndexWriter peut effectuer des opérations telles que l'écriture, la modification, l'ajout et la suppression d'index, mais il ne peut pas lire ou rechercher l'index.
Document, classe de documents. L'unité de base de l'indexation dans Pylucene est le « Document ». Un document peut être une page Web, un article ou un e-mail. Le document est l'unité utilisée pour créer l'index et constitue également l'unité de résultat lors de la recherche. Une conception appropriée de celui-ci peut fournir des services de recherche personnalisés.
Déposé, classe de domaine. Un Document peut contenir plusieurs champs (Field). Classé est un composant du document, tout comme un article peut être composé de plusieurs fichiers tels que le titre de l'article, le corps de l'article, l'auteur, la date de publication, etc.
Traitez une page comme un document, qui contient trois champs : l'adresse URL de la page (url), le titre de la page (titre) et le contenu textuel principal de la page (contenu). Pour la méthode de stockage de l'index, choisissez d'utiliser la classe SimpleFSDirectory pour enregistrer l'index dans un fichier. L'analyseur choisit CJKAnalyzer fourni avec Pylucene. Cet analyseur prend en charge le chinois et convient au traitement de texte du contenu chinois.
Les étapes spécifiques pour créer un index à l'aide de Pylucene sont les suivantes :
lucene.initVM()
INDEXIDR = self.__index_dir
indexdir = SimpleFSDirectory(File(INDEXIDR))①
analyzer = CJKAnalyzer(Version.LUCENE_30)②
index_writer = IndexWriter(indexdir, analyzer, True, IndexWriter.MaxFieldLength(512))③
document = Document()④
document.add(Field("content", str(page_info["content"]), Field.Store.NOT, Field.Index.ANALYZED))⑤
document.add(Field("url", visiting, Field.Store.YES, Field.Index.NOT_ANALYZED))⑥
document.add(Field("title", str(page_info["title"]), Field.Store.YES, Field.Index.ANALYZED))⑦
index_writer.addDocument(document)⑧
index_writer.optimize()⑨
index_writer.close()⑩
Il y a 10 étapes principales pour créer un index :
① Instanciez un objet SimpleFSDirectory et enregistrez l'index dans un fichier local. Le chemin enregistré est le chemin personnalisé "INDEXIDR".
② Instanciez un analyseur CJKAnalyzer. Le paramètre Version.LUCENE_30 lors de l'instanciation est le numéro de version de Pylucene.
③ Instanciez un objet IndexWriter. Les quatre paramètres portés sont l'objet SimpleFSDirectory précédemment instancié et l'analyseur CJKAnalyzer. La variable booléenne true signifie créer un nouvel index IndexWriter.MaxFieldLength spécifie le nombre maximum de champs (Filed) dans. un indice.
④ Instanciez un objet Document et nommez-le document.
⑤Ajoutez un domaine nommé « contenu » au document. Le contenu de ce champ est le contenu textuel principal d'une page Web obtenu par le robot d'exploration. Le paramètre de cette opération est l'objet Field qui est instancié et utilisé immédiatement ; les quatre paramètres de l'objet Field sont :
(1) "content", le nom du domaine.
(2) page_info["content"], le contenu textuel principal de la page Web collecté par le robot.
(3) Field.Store est une variable utilisée pour indiquer si la valeur de ce champ peut être restaurée aux caractères d'origine. Field.Store.YES indique que le contenu stocké dans ce champ peut être restauré aux caractères d'origine. le contenu du texte original. Field Store.NOT signifie qu'il n'est pas récupérable.
(4) La variable Field.Index indique si le contenu du champ doit être traité par l'analyseur Field.ANALYZED indique que l'analyseur est utilisé pour le traitement des caractères dans le champ. NOT_ANALYZED indique que l'analyseur n'est pas utilisé pour le champ. L'analyseur traite les caractères.
⑥Ajoutez un domaine nommé "url" pour enregistrer l'adresse de la page.
⑦ Ajoutez un champ nommé "titre" pour enregistrer le titre de la page.
⑧Instancier l'objet IndexWriter pour écrire le document dans le fichier d'index.
⑨ Optimisez les fichiers de la bibliothèque d'index et fusionnez les petits fichiers de la bibliothèque d'index en gros fichiers.
⑩Fermez l'objet IndexWriter une fois l'opération de création d'index terminée en un seul cycle.
Les principales classes de Pylucene pour la recherche par indexation incluent IndexSearcher, Query et QueryParser[16].
IndexSearcher, classe de recherche d'index. Utilisé pour effectuer des opérations de recherche dans la bibliothèque d'index construite par IndexWriter.
Query, une classe qui décrit les requêtes de requête. Il soumet la demande de requête à IndexSearcher pour terminer l'opération de recherche. Query comporte de nombreuses sous-classes pour répondre à différentes requêtes de requête. Par exemple, TermQuery recherche par terme, qui est le type de requête le plus basique et le plus simple, et est utilisé pour faire correspondre des documents avec des éléments spécifiques dans un domaine spécifié ; RangeQuery, recherche dans une plage spécifiée, est utilisé pour faire correspondre des documents dans une plage spécifique ; un domaine spécifié ; FuzzyQuery, une requête floue, peut simplement identifier des correspondances de synonymes sémantiquement similaires au mot-clé de la requête.
QueryParser, analyseur de requêtes. Lorsque vous devez implémenter différentes exigences de requête, vous devez utiliser différentes sous-classes fournies par Query, ce qui facilite la confusion lors de l'utilisation de Query. Par conséquent, Pylucene fournit également l'analyseur de requêtes QueryParser. QueryParser peut analyser l'instruction de requête soumise et sélectionner la sous-classe de requête appropriée en fonction de la syntaxe de requête pour compléter la requête correspondante. Les développeurs n'ont pas besoin de se soucier de la classe d'implémentation de requête utilisée en bas. Par exemple, l'instruction de requête "mot-clé 1 et mot-clé 2" QueryParser analyse pour interroger les documents qui correspondent à la fois au mot-clé 1 et au mot-clé 2 ; l'instruction de requête "id[123 à 456]" QueryParser analyse pour interroger le domaine dont le nom est "id" Documents dont la valeur est comprise dans la plage spécifiée de « 123 » à « 456 » ; Instruction de requête « mot-clé site : www.web.com » QueryParser analyse en une requête qui satisfait également la valeur de « www.web » dans le domaine nommé « site » " .com " et les documents correspondant aux deux conditions de requête de " mot clé ".
La recherche d'index est l'un des domaines sur lesquels Pylucene se concentre. Une classe nommée requête est écrite pour implémenter la recherche d'index et comporte les étapes principales suivantes pour implémenter la recherche d'index :
lucene.initVM()
if query_str.find(":") ==-1 and query_str.find(":") ==-1:
query_str="title:"+query_str+" OR content:"+query_str①
indir= SimpleFSDirectory(File(self.__indexDir))②
lucene_analyzer= CJKAnalyzer(Version.LUCENE_CURRENT)③
lucene_searcher= IndexSearcher(indir)④
my_query = QueryParser(Version.LUCENE_CURRENT,"title",lucene_analyzer).parse(query_str)⑤
total_hits = lucene_searcher.search(my_query, MAX)⑥
for hit in total_hits.scoreDocs:⑦
print"Hit Score: ", hit.score
doc = lucene_searcher.doc(hit.doc)
result_urls.append(doc.get("url").encode("utf-8"))
result_titles.append(doc.get("title").encode("utf-8"))
print doc.get("title").encode("utf-8")
result = {"Hits": total_hits.totalHits, "url":tuple(result_urls), "title":tuple(result_titles)}
return result<.>
Il y a 7 étapes principales dans la recherche par index : ① Tout d'abord, jugez l'instruction de recherche. Si l'instruction n'est pas une requête de domaine unique pour le titre ou le contenu de l'article, elle ne contient pas de mots-clés. Lorsque « titre : » ou « contenu : » est utilisé, les champs de titre et de contenu sont recherchés par défaut. ②Instancier un objet SimpleFSDirectory et spécifier son chemin de travail comme chemin où l'index a été précédemment créé.③实例化一个CJKAnalyzer分析器,搜索时使用的分析器应与索引构建时使用的分析器在类型版本上均一致。
④实例化一个IndexSearcher对象lucene_searcher,它的参数为第○2步的SimpleFSDirectory对象。
⑤实例化一个QueryParser对象my_query,它描述查询请求,解析Query查询语句。参数Version.LUCENE_CURRENT为pylucene的版本号,“title”指默认的搜索域,lucene_analyzer指定了使用的分析器,query_str是Query查询语句。在实例化QueryParser前会对用户搜索请求作简单处理,若用户指定了搜索某个域就搜索该域,若用户未指定则同时搜索“title”和“content”两个域。
⑥lucene_searcher进行搜索操作,返回结果集total_hits。total_hits中包含结果总数totalHits,搜索结果的文档集scoreDocs,scoreDocs中包括搜索出的文档以及每篇文档与搜索语句相关度的得分。
⑦lucene_searcher搜索出的结果集不能直接被Python处理,因而在搜索操作返回结果之前应将结果由Pylucene转为普通的Python数据结构。使用For循环依次处理每个结果,将结果文档按相关度得分高低依次将它们的地址域“url”的值放入Python列表result_urls,将标题域“title”的值放入列表result_titles。最后将包含地址、标题的列表和结果总数组合成一个Python“字典”,将最后处理的结果作为整个搜索操作的返回值。
用户在浏览器搜索框输入搜索词并点击搜索,浏览器发起一个GET请求,Flask的路由route设置了由result函数响应该请求。result函数先实例化一个搜索类query的对象infoso,将搜索词传递给该对象,infoso完成搜索将结果返回给函数result。函数result将搜索出来的页面和结果总数等传递给模板result.html,模板result.html用于呈现结果
如下是Python使用flask模块处理搜索请求的代码:
app = Flask(__name__)#创建Flask实例
@app.route('/')#设置搜索默认主页
def index():
html="<h1>title这是标题</h1>"
return render_template('index.html')
@app.route("/result",methods=['GET', 'POST'])#注册路由,并指定HTTP方法为GET、POST
def result(): #resul函数
if request.method=="GET":#响应GET请求
key_word=request.args.get('word')#获取搜索语句
if len(key_word)!=0:
infoso = query("./glxy") #创建查询类query的实例
re = infoso.search(key_word)#进行搜索,返回结果集
so_result=[]
n=0
for item in re["url"]:
temp_result={"url":item,"title":re["title"][n]}#将结果集传递给模板
so_result.append(temp_result)
n=n+1
return render_template('result.html', key_word=key_word, result_sum=re["Hits"],result=so_result)
else:
key_word=""
return render_template('result.html')
if __name__ == '__main__':
app.debug = True
app.run()#运行web服务Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!