
Maison >base de données >tutoriel mysql >Comment mongoDB implémente-t-il la pagination ?
Comment mongoDB implémente-t-il la pagination ?

- 零下一度original
- 2017-07-03 16:39:201920parcourir
Cet article présente principalement en détail les deux méthodes de mongoDB pour implémenter la pagination Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
La pagination de MongoDB. requête utilise les trois fonctions tableau de limit(), skip() et sort() pour effectuer une requête de pagination.
Ce qui suit sont mes données de test
db.test.find().sort({"age":1});

La première méthode
Interrogez les données de la première page : db.test.find().sort({"age":1}).limit(2); 🎜>


La deuxième méthode
Interroger les données de la première page : db.test.find().sort({"age":1}).limit( 2);
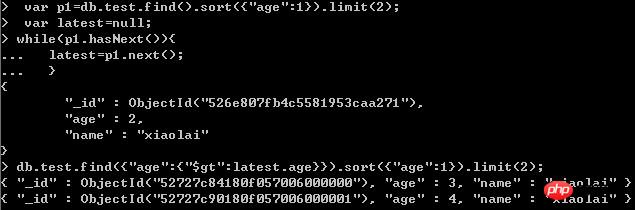
Skip saute trop d'enregistrements et l'efficacité est un peu faibleAprès un examen attentif, la deuxième méthode est. en effet ne convient pas au saut de page et n'est pas efficace non plus
Pour les données massives, nous devons effectuer un traitement spécial
Il existe les deux méthodes suivantes
<.>La première méthodeLimiter le nombre de pages de pagination, similaire au traitement de pagination de Baidu, qui ne fait que affiche les sept cents enregistrements précédents, comme celui-ci. Il n'est pas nécessaire de prendre en compte les problèmes de performances. Après tout, la plupart des gens se contentent de se tourner vers les dix premières pages et de trouver ce dont ils ont besoin 
Nous pouvons le faire en supposant qu'il soit trié en fonction. pour identifier, nous pouvons suivre l'identifiant. Le numéro de série de la page où se trouve l'identifiant est stocké dans redis/MemberCached,
comme ceci, en supposant que chaque page contient 10 enregistrements page d'identification1 12 1. . . 101112122. . . . 20 2De cette façon, lorsque nous vérifions la première page, nous pouvons récupérer directement dix éléments de données En supposant qu'il y ait 100 millions d'éléments de données, un enregistrement L'identifiant occupe 4 octets. Les autres informations occupent un octet et un enregistrement occupe 5 octets 1 0000 0000 *5/(1024*1024)=476MBCette approche utilise généralement l'espace pour le temps. La majeure partie du temps de requête de la base de données est consacrée à la connexion à la base de données. Le mettre dans le cache peut considérablement accélérer la requête.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!