
Maison >Java >javaDidacticiel >Explication détaillée du principe du pool de threads ThreadPoolExecutor de JAVA et de ses exemples de méthodes d'exécution
Explication détaillée du principe du pool de threads ThreadPoolExecutor de JAVA et de ses exemples de méthodes d'exécution

- 怪我咯original
- 2017-06-30 10:38:362664parcourir
L'éditeur suivant vous proposera un article sur le principe du pool de threads ThreadPoolExecutor et sa méthode d'exécution (explication détaillée). L'éditeur le trouve plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence pour tout le monde. Venez jeter un oeil avec l'éditeur
jdk1.7.0_79
La plupart des gens utilisent des pools de threads, et ils savent aussi pourquoi. C'est juste que les tâches doivent être exécutées de manière asynchrone et que les threads doivent être gérés de manière uniforme. Concernant l'obtention de threads à partir du pool de threads, la plupart des gens savent peut-être seulement que si j'ai besoin d'un thread pour effectuer une tâche, je lancerai la tâche dans le pool de threads. S'il y a des threads inactifs dans le pool de threads, ils seront exécutés. S'il n'y a pas de threads inactifs, ils seront exécutés. En fait, le principe d’exécution du pool de threads est bien plus que cela simple.
Le package de concurrence Java fournit une classe de pool de threads - ThreadPoolExecutor. En fait, nous sommes plus nombreux à utiliser le pool de threads fourni par la classe d'usine Executors : newFixedThreadPool, newSingleThreadPool, newCachedThreadPool, ces trois pools de threads ne sont pas une sous-classe. de ThreadPoolExecutor. Concernant la relation entre ceux-ci, regardons d'abord ThreadPoolExecutor. Vérifiez le code source et constatez qu'il a un total de 4 méthodes de construction .
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
Tout d'abord, commençons par ces paramètres pour comprendre le principe d'exécution du pool de threads ThreadPoolExecutor.
corePoolSize : Le nombre de threads dans le pool de threads principal
maximumPoolSize : Nombre maximum de threads du pool de threads
keepAliveTime : Temps de rétention de l'activité des threads, après le thread de travail de le pool de threads est inactif, il est temps de rester en vie.
unité : Unité de temps de rétention de l'activité du thread.
workQueue : Spécifiez la file d'attente de blocage utilisée par la file d'attente des tâches
corePoolSize et maximumPoolSize sont dans le thread spécifié Le nombre de threads dans le pool, il semble que lorsque vous utilisez habituellement le pool de threads, il vous suffit de transmettre un paramètre de taille du pool de threads pour créer un pool de threads. Java nous fournit certaines classes de pool de threads couramment utilisées. , à savoir le newFixedThreadPool mentionné ci-dessus. , newSingleThreadExecutor, newCachedThreadPool Bien sûr, si nous voulons créer nous-mêmes un pool de threads personnalisé, nous devons "configurer" nous-mêmes certains paramètres liés au pool de threads.
Lorsqu'une tâche est transmise au pool de threads pour traitement, le principe d'exécution du pool de threads est tel qu'indiqué dans la figure ci-dessous. Reportez-vous à "L'art de la programmation simultanée Java"
. 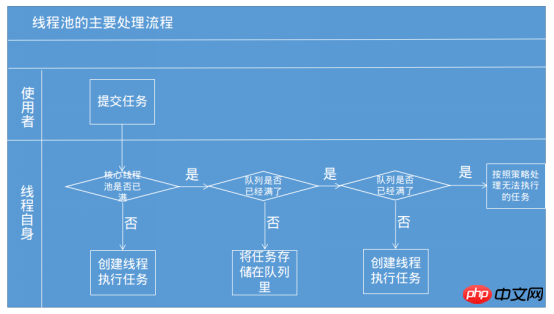
① Tout d'abord, il déterminera s'il y a des threads dans le pool de threads principaux qui peuvent être exécutés. S'il y a des threads inactifs, un thread sera créé pour effectuer la tâche.
②Lorsqu'aucun thread n'est disponible pour l'exécution dans le pool de threads principal, la tâche est lancée dans la file d'attente des tâches.
③ Si la file d'attente des tâches (limitée) est également pleine, mais que le nombre de threads en cours d'exécution est inférieur au nombre du pool de threads maximum, un nouveau thread sera créé pour exécuter la tâche, mais si l'exécution de la tâche Lorsque le nombre de threads a atteint le nombre maximum de pools de threads, les threads ne peuvent pas être créés pour effectuer des tâches.
Donc, en fait, le pool de threads ne jette pas simplement la tâche dans le pool de threads, s'il y a des threads dans le pool de threads, la tâche sera exécutée, et s'il n'y a pas de threads, elle attendra. .
Pour consolider les principes des pools de threads, apprenons maintenant les trois pools de threads couramment utilisés mentionnés ci-dessus :
Executors.newFixedThreadPool : Créer un pool de threads avec un nombre fixe de threads .
// Executors#newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}Vous pouvez voir que la classe ThreadPoolExecutor est appelée dans newFixedThreadPool et que le paramètre passé corePoolSize= maximumPoolSize=nThread. En repensant au principe d'exécution du pool de threads, lorsqu'une tâche est soumise au pool de threads, il est d'abord déterminé s'il y a des threads inactifs dans le pool de threads principal. S'il y a des threads inactifs, un thread sera créé. , la tâche sera placée dans la file d'attente des tâches (voici la file d'attente de blocage limitée LinkedBlockingQueue ). Si la file d'attente des tâches est pleine, pour newFixedThreadPool, son nombre maximum de pools de threads = nombre de pools de threads principaux à ce moment-là. la file d'attente est également pleine et les nouveaux threads ne peuvent pas être développés pour exécuter des tâches.
Executors.newSingleThreadExecutor : Créez un pool de threads contenant un seul thread.
//Executors# newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}只有一个线程的线程池好像有点奇怪,并且并没有直接将返回ThreadPoolExecutor,甚至也没有直接将线程池数量1传递给newFixedThreadPool返回。那就说明这个只含有一个线程的线程池,或许并没有只包含一个线程那么简单。在其源码注释中这么写到:创建只有一个工作线程的线程池用于操作一个无界队列(如果由于前驱节点的执行被终止结束了,一个新的线程将会继续执行后继节点线程)任务得以继续执行,不同于newFixedThreadPool(1)不会有额外的线程来重新继续执行后继节点。也就是说newSingleThreadExecutor自始至终都只有一个线程在执行,这和newFixedThreadPool一样,但如果线程终止结束过后newSingleThreadExecutor则会重新创建一个新的线程来继续执行任务队列中的线程,而newFixedThreaPool则不会。
Executors.newCachedThreadPool:根据需要创建新线程的线程池。
//Executors#newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}可以看到newCachedThread返回的是ThreadPoolExecutor,其参数核心线程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,这也就是说当任务被提交到newCachedThread线程池时,将会直接把任务放到SynchronousQueue任务队列中,maximumPool从任务队列中获取任务。注意SynchronousQueue是一个没有容量的队列,也就是说每个入队操作必须等待另一个线程的对应出队操作,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,newCachedThreadPool会不断创建线程,线程多并不是一件好事,严重会耗尽CPU和内存资源。
题外话:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,这三者都直接或间接调用了ThreadPoolExecutor,为什么它们三者没有直接是其子类,而是通过Executors来实例化呢?这是所采用的静态工厂方法,在java.util.Connections接口中同样也是采用的静态工厂方法来创建相关的类。这样有很多好处,静态工厂方法是用来产生对象的,产生什么对象没关系,只要返回原返回类型或原返回类型的子类型都可以,降低API数目和使用难度,在《Effective Java》中的第1条就是静态工厂方法。
回到ThreadPoolExecutor,首先来看它的继承关系:
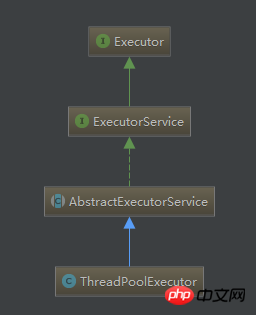
ThreadPoolExecutor它的顶级父类是Executor接口,只包含了一个方法——execute,这个方法也就是线程池的“执行”。
//Executor#execute
public interface Executor {
void execute(Runnable command);
}Executor#execute的实现则是在ThreadPoolExecutor中实现的:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
…
}一来就碰到个不知所云的ctl变量它的定义:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
这个变量使用来干嘛的呢?它的作用有点类似我们在《ReadWriteLock接口及其实现ReentrantReadWriteLock》中提到的读写锁有读、写两个同步状态,而AQS则只提供了state一个int型变量,此时将state高16位表示为读状态,低16位表示为写状态。这里的clt同样也是,它表示了两个概念:
workerCount:当前有效的线程数
runState:当前线程池的五种状态,Running、Shutdown、Stop、Tidying、Terminate。
int型变量一共有32位,线程池的五种状态runState至少需要3位来表示,故workCount只能有29位,所以代码中规定线程池的有效线程数最多为229-1。
//ThreadPoolExecutor private static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,线程数量所占位数 private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大线程数,229-1 //五种线程池状态 private static final int RUNNING = -1 << COUNT_BITS; /int型变量高3位(含符号位)101表RUNING private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000 private static final int STOP = 1 << COUNT_BITS; //高3位001 private static final int TIDYING = 2 << COUNT_BITS; //高3位010 private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
再次回到ThreadPoolExecutor#execute方法:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); //由它可以获取到当前有效的线程数和线程池的状态
/*1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中*/
if (workerCountOf(c) < corePoolSize){
if (addWorker(command, tre)) //在addWorker中创建工作线程执行任务
return ;
c = ctl.get();
}
/*2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中*/
if (isRunning(c) && workQueue.offer(command)) { //线程池是否处于运行状态,且是否任务插入任务队列成功
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command)) //线程池是否处于运行状态,如果不是则使刚刚的任务出队
reject(command); //抛出RejectedExceptionException异常
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常*/
else if (!addWorker(command, false)){
reject(command); //抛出RejectedExceptionException异常
}
}上面代码注释第7行的即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
//ThreadPoolExecutor#addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
/*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/
...
if (compareAndIncrementWorkerCount(c))
break retry;
...
/*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock; //全局锁
w = new Woker(firstTask); //将线程封装为Worker工作线程
final Thread t = w.thread;
if (t != null) {
mainLock.lock(); //获取全局锁
/*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/
try {
int c = clt.get();
int rs = runStateOf(c); //线程池运行状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空
if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的
throw new IllegalThreadStateException();
workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中
int s = worker.size(); //工作线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //新构造的工作线程加入成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法
workerStarted = true;
}
}
} finally {
if (!workerStarted) //未能成功创建执行工作线程
addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除
}
return workerStarted;
}在上面第35代码中,工作线程被成功添加到工作线程集合中后,则开始start执行,这里start执行的是Worker工作线程中的run方法。
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1); //设置AQS的同步状态为-1,禁止中断,直到调用runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //通过线程工厂来创建一个线程,将自身作为Runnable传递传递
}
public void run() {
runWorker(this); //运行工作线程
}
}ThreadPoolExecutor#runWorker,在此方法中,Worker在执行完任务后,还会循环获取任务队列里的任务执行(其中的getTask方法),也就是说Worker不仅仅是在执行完给它的任务就释放或者结束,它不会闲着,而是继续从任务队列中获取任务,直到任务队列中没有任务可执行时,它才退出循环完成任务。理解了以上的源码过后,往后线程池执行原理的第二步、第三步的理解实则水到渠成。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!