
Maison >Java >javaDidacticiel >Hash--Introduction aux algorithmes courants
Hash--Introduction aux algorithmes courants

- 零下一度original
- 2017-06-29 11:29:193046parcourir
Hash (Hash), également connu sous le nom de hachage, est un algorithme très courant. Le hachage est principalement utilisé dans la structure de données Java HashMap de . L'algorithme de hachage se compose de deux parties : la fonction de hachage et la table de hachage. Nous pouvons connaître les caractéristiques de notre tableau. Nous pouvons localiser rapidement les éléments grâce aux indices (O(1) De même, dans la table de hachage, nous pouvons utiliser la clé (valeur de hachage). ) Pour localiser rapidement une certaine valeur, la valeur de hachage est calculée via la fonction de hachage (hash(key) = adresse). L'élément [adresse] = valeur
peut être localisé grâce à la valeur de hachage. Le principe est similaire à celui d'un tableau.La meilleure fonction de hachage est bien sûr celle qui peut calculer une valeur de hachage unique pour chaque clé valeur, mais il peut souvent y avoir des différentes key
valeur de hachage, qui provoque des conflits. Il y a deux aspects pour juger si une fonction de hachage est bien conçue :1. Peu de conflits.
2. Le calcul est rapide.
Vous trouverez ci-dessous plusieurs fonctions de hachage couramment utilisées. Elles reposent toutes sur certains principes mathématiques et ont fait l'objet de beaucoup de pratique. Leurs principes mathématiques ne seront pas explorés ici. BKDRFonction de hachage (h = 31 * h + c)
Cette fonction de hachage est appliquée au calcul de la valeur de hachage de chaîne en Java
.//String#hashCodepublic int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i]; //BKDR 哈希函数,常数可以是131、1313、13131…… }
hash = h;
}return h;
}DJB2 Fonction de hachage ( h = h << 5 + h + c = h = 33 * h + c)
ElasticSearch profite de< Le 🎜>La fonction de hachage DJB2 hache la clé spécifiée du document à indexer.
SDBMFonction de hachage (h = h << 6 + h << 16 - h + c = 65599 * h + c)
est appliqué dans SDBM (un simple moteur de base de données).
Ce qui précède n'est qu'une liste de trois fonctions de hachage. Faisons une expérience pour voir comment elles entrent en conflit.Java
1 package com.algorithm.hash; 2 3 import java.util.HashMap; 4 import java.util.UUID; 5 6 /** 7 * 三种哈希函数冲突数比较 8 * Created by yulinfeng on 6/27/17. 9 */10 public class HashFunc {11 12 public static void main(String[] args) {13 int length = 1000000; //100万字符串14 //利用HashMap来计算冲突数,HashMap的键值不能重复所以length - map.size()即为冲突数15 HashMap<String, String> bkdrMap = new HashMap<String, String>();16 HashMap<String, String> djb2Map = new HashMap<String, String>();17 HashMap<String, String> sdbmMap = new HashMap<String, String>();18 getStr(length, bkdrMap, djb2Map, sdbmMap);19 System.out.println("BKDR哈希函数100万字符串的冲突数:" + (length - bkdrMap.size()));20 System.out.println("DJB2哈希函数100万字符串的冲突数:" + (length - djb2Map.size()));21 System.out.println("SDBM哈希函数100万字符串的冲突数:" + (length - sdbmMap.size()));22 }23 24 /**25 * 生成字符串,并计算冲突数26 * @param length27 * @param bkdrMap28 * @param djb2Map29 * @param sdbmMap30 */31 private static void getStr(int length, HashMap<String, String> bkdrMap, HashMap<String, String> djb2Map, HashMap<String, String> sdbmMap) {32 for (int i = 0; i < length; i++) {33 System.out.println(i);34 String str = UUID.randomUUID().toString();35 bkdrMap.put(String.valueOf(str.hashCode()), str); //Java的String.hashCode就是BKDR哈希函数, h = 31 * h + c36 djb2Map.put(djb2(str), str); //DJB2哈希函数37 sdbmMap.put(sdbm(str), str); //SDBM哈希函数38 }39 }40 41 /**42 * djb2哈希函数43 * @param str44 * @return45 */46 private static String djb2(String str) {47 int hash = 0;48 for (int i = 0; i != str.length(); i++) {49 hash = hash * 33 + str.charAt(i); //h = h << 5 + h + c = h = 33 * h + c50 }51 return String.valueOf(hash);52 }53 54 /**55 * sdbm哈希函数56 * @param str57 * @return58 */59 private static String sdbm(String str) {60 int hash = 0;61 for (int i = 0; i != str.length(); i++) {62 hash = 65599 * hash + str.charAt(i); //h = h << 6 + h << 16 - h + c = 65599 * h + c63 }64 return String.valueOf(hash);65 }66 }
Les éléments suivants sont 1010 000, 10010 000, 20010 000 situations de conflits :

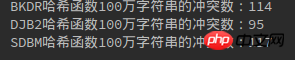
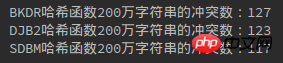
Python3
1 import uuid 2 3 def hash_test(length, bkdrDic, djb2Dic, sdbmDic): 4 for i in range(length): 5 string = str(uuid.uuid1()) #基于时间戳 6 bkdrDic[bkdr(string)] = string 7 djb2Dic[djb2(string)] = string 8 sdbmDic[sdbm(string)] = string 9 10 #BDKR哈希函数11 def bkdr(string):12 hash = 013 for i in range(len(string)):14 hash = 31 * hash + ord(string[i]) # h = 31 * h + c15 return hash16 17 #DJB2哈希函数18 def djb2(string):19 hash = 020 for i in range(len(string)):21 hash = 33 * hash + ord(string[i]) # h = h << 5 + h + c22 return hash23 24 #SDBM哈希函数25 def sdbm(string):26 hash = 027 for i in range(len(string)):28 hash = 65599 * hash + ord(string[i]) # h = h << 6 + h << 16 - h + c29 return hash30 31 length = 10032 bkdrDic = dict() #bkdrDic = {}33 djb2Dic = dict()34 sdbmDic = dict()35 hash_test(length, bkdrDic, djb2Dic, sdbmDic)36 print("BKDR哈希函数100万字符串的冲突数:%d"%(length - len(bkdrDic)))37 print("DJB2哈希函数100万字符串的冲突数:%d"%(length - len(djb2Dic)))38 print("SDBM哈希函数100万字符串的冲突数:%d"%(length - len(sdbmDic)))La table de hachage est une structure de données qui doit être utilisée avec des fonctions de hachage pour créer des index pour une recherche rapide——"Notes d'algorithme". De manière générale, il s'agit d'un espace de stockage de longueur fixe, tel que HashMapLa table de hachage par défaut est une table de hachage de longueur fixe de 16Entrée tableau. Après avoir disposant d'un espace de stockage de longueur fixe, le problème restant est de savoir comment mettre la valeur dans quelle position. Habituellement, si la valeur de hachage est m, la longueur est n, alors cette valeur est placée à la position m mod n.
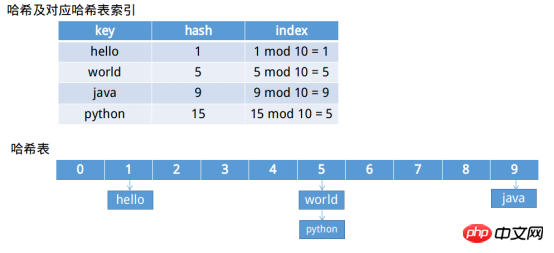
10, ce qui entraîne 1 collisions si le hachage. La longueur de la table est 20, alors il n'y aura pas de conflit. La recherche sera plus rapide mais gaspillera plus d'espace si la longueur de la table de hachage est 2<.>, inversera les recherches de conflits 3 plus lentement mais cela permettra d'économiser beaucoup d'espace. La sélection de la longueur de la table de hachage est donc cruciale, mais c'est aussi un problème important.
Supplément :Le hachage est utilisé dans de nombreux aspects, par exemple, différentes valeurs ont des valeurs de hachage différentes, mais Le L'algorithme de hachage peut également être conçu de manière à ce que des valeurs similaires ou identiques aient des valeurs de hachage similaires ou identiques. C'est-à-dire que si deux objets sont complètement différents, alors leurs valeurs de hachage sont complètement différentes ; si deux objets sont exactement les mêmes, alors leurs valeurs de hachage sont également exactement les mêmes ; alors leurs valeurs de hachage sont également complètement différentes. Il s'agit en fait d'un problème de similarité, ce qui signifie que cette idée peut être généralisée et appliquée aux calculs de similarité (comme le problème de distance de Jaccard), et finalement appliquée à un placement publicitaire précis, à une recommandation de produits, etc.
De plus, un hachage cohérent peut également être appliqué dans l'équilibrage de charge. Comment garantir que chaque serveur peut répartir uniformément la pression de charge, un bon algorithme de hachage peut également le faire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment définir les marges des boutons à l'intérieur d'un LinearLayout par programme ?
- Pourquoi et comment synchroniser sur des objets chaîne en Java ?
- Comment puis-je personnaliser la tokenisation d'entrée en Java à l'aide de « Scanner.useDelimiter() » ?
- Comment les Varargs de Java peuvent-ils simplifier la gestion d'un nombre indéterminé d'arguments ?
- Comment implémenter le serveur et le client de téléchargement de points d'arrêt en Java