
Maison >base de données >tutoriel mysql >Causes et solutions d'erreur du délai d'expiration de la demande de disque SQL Server 833_MsSql
Causes et solutions d'erreur du délai d'expiration de la demande de disque SQL Server 833_MsSql

- 微波original
- 2017-06-28 15:41:282486parcourir
Cet article présente principalement les causes et les solutions de l'erreur 833 du délai d'expiration de la demande de disque SQL Server. Les amis dans le besoin peuvent s'y référer
J'ai récemment rencontré un serveur SQL Server qui a répondu extrêmement lentement et des demandes client se sont produites. En cas d'erreur, un message d'erreur apparaît dans le journal des erreurs de la base de données indiquant que la demande de disque prend plus de 15 secondes.
Pour ce genre de problème, s'agit-il d'une panne du système de stockage ou du disque, d'un problème de SQL Server lui-même, ou est-ce causé par l'application ? Comment le résoudre ?
Cet article procédera à une analyse simple de certains facteurs à l'origine de ce problème, mais il ne peut pas couvrir toutes les possibilités potentielles, une analyse spécifique doit donc être effectuée lorsque vous rencontrez des problèmes similaires.
Délai d'expiration de la demande de disque dans SQL Server
La version anglaise de l'erreur message d'erreur est la suivante :
SQL Server a rencontré %d occurrence(s) de requêtes d'E/S prenant plus de %d secondes pour se terminer sur le fichier [%ls] dans l'ID de base de données %d. Le descripteur de fichier du système d'exploitation est 0x%p. 🎜 > Le décalage de la dernière E/S longue est : %#016I64x
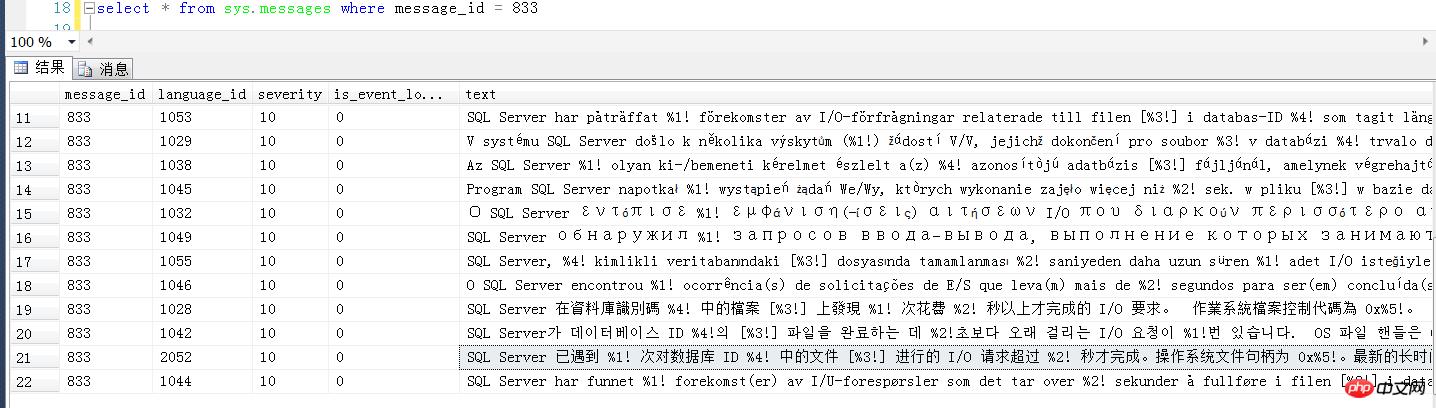
La signification de l'erreur 833 du moteur de base de données
Examinons d'abord la signification spécifique de cette erreur 833, je ne l'expliquerai pas moi-même. . , c’est écrit très clairement dans ce livre classique. En bref, cela signifie que lorsque SQL Server demande la lecture et l'écriture du disque, il rencontre un disque occupé ou d'autres facteurs et ne l'a pas terminé depuis plus de 15 secondes Par exemple, lors de la lecture et de l'écriture données, il doit lire et écrire des données sur le disque. Lorsqu'une requête est lancée, mais que le disque est occupé ou qu'il y a d'autres problèmes, il est trop tard ou la réponse n'est pas assez rapide. Cela affectera sans aucun doute sérieusement le temps de réponse. du serveur externe de SQL Server.

Analyse des causes
Puisqu'il s'agit d'un serveur SQL Server dédié, il n'y a aucune demande provenant d'autres applications. Cela est très probablement lié à la requête adressée à la base de données sqlserver. En fait, il y avait des signes avant-coureurs avant que ce problème ne se produise. Le serveur est généralement assez stable (le CPU dépasse rarement 60 %, la mémoire PLE peut être stable pendant plus de 20 minutes, la latence des E/S du disque est faible, etc. ), mais parfois il y aura des convulsions pendant un certain temps Lorsque les convulsions se produisent, le CPU montera à environ 80%, le PLE de la mémoire sera sérieusement réduit et le délai d'E/S sera sérieusement augmenté. Maintenant, nous ne pouvons commencer qu'avec laSession de SQL Server En observant la session active dans SQL Server, nous avons constaté que la requête heure d'un certain type de. L'instruction SQL est très longue, Habituellement, ce type de SQL est exécuté relativement fréquemment sur une certaine période de temps.
Mais dans des circonstances normales, l'efficacité d'exécution de ce type de SQL est encore relativement élevée. Pourquoi devient-elle soudainement très faible ?
Lors de la vérification du plan d'exécution correspondant de la session active, nous avons constaté que l'état d'attente de ce type de session active est IO en attente (PAGEIOLATCH_SH), et l'exécution de SQL est complètement inattendue.
Étant donné que des requêtes similaires sont exécutées relativement fréquemment, ces sessions seront initiées à partir de différents clients. Une fois l'efficacité de l'exécution SQL diminuée, un grand nombre de sessions actives seront accumulées sur le serveur
Cela amène le SQL correspondant à utiliser un plan d'exécution déraisonnable pour implémenter la requête, et en même temps provoque une congestion de session. Le client envoie un grand nombre de sessions et les exécute lentement de manière inefficace. chemin. .
index provoquent le problème évoqué au début.
Enfin, le problème a été résolu grâce à la reconstruction de l'index (favorisant la mise à jour des informations statistiques, bien sûr, la mise à jour des informations statistiques pures est également possible. Pour une prévention à long terme, il est nécessaire d'organiser un travail pour définir artificiellement le seuil). valeur et pourcentage d’échantillonnage de la mise à jour des informations statistiques.Résumé :
De nombreux problèmes sur le serveur de base de données sont un processus de réaction en chaîne, ce qui correspond à certains des phénomènes observés. soyez ce qu'il semble à première vue (la demande de disque expire, le problème est-il au niveau du stockage ?) Un poste professionnel doit avoir des qualités professionnelles. Par exemple, au début, le DBA a pensé à tort qu'il s'agissait d'un problème de stockage, et l'ingénieur de stockage. J'ai pensé qu'il s'agissait d'un problème de serveur. Il est anormal que la mémoire soit pleine, etc. En fait, ce n'est pas la cause première du problème.
Face à un problème, nous devons remonter à sa source et découvrir la cause la plus fondamentale. C'est la clé pour résoudre le problème.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!