
Maison >développement back-end >Tutoriel Python >Explication détaillée du traitement du Big Data en Python
Explication détaillée du traitement du Big Data en Python

- 零下一度original
- 2017-06-27 10:37:395092parcourir
Partager

Points de connaissances :
lubrifier le temps de démontage du paquet | POSIXlt
Utiliser la classification des arbres de décision et la prédiction aléatoire des forêts
Utiliser des logarithmes pour l'ajustement et la fonction exp pour restaurer
L'ensemble d'entraînement provient des données de location de vélos dans le programme de partage de vélos Kaggle Washington, et la relation entre les vélos partagés, la météo, l'heure, etc. est analysée. L'ensemble de données comprend un total de 11 variables et plus de 10 000 lignes de données.
Tout d'abord, jetons un coup d'œil aux données officielles. Il existe deux tableaux, tous deux pour 2011-2012. La différence est que le fichier Test contient toutes les dates de chaque mois, mais il. n'est pas des utilisateurs enregistrés et des utilisateurs aléatoires. Le fichier Train ne compte que 1 à 20 jours par mois, mais il existe deux types d'utilisateurs.
Solution : Complétez le nombre d'utilisateurs de 21 à 30 dans la fiche Train. Le critère d'évaluation est la comparaison des prévisions avec les quantités réelles.

Chargez d'abord les fichiers et les packages
library(lubridate)library(randomForest)library(readr)setwd("E:")
data<-read_csv("train.csv")head(data)Ici, j'ai rencontré un piège, en utilisant The read.csv par défaut du langage R ne peut pas lire le format de fichier correct. C'est encore pire lorsqu'il est remplacé par xlsx. Cela devient tout le temps un nombre étrange comme 43045. J'ai déjà essayé as.Date et il peut être converti correctement, mais cette fois, comme il y a des minutes et des secondes, je ne peux utiliser que l'horodatage, mais le résultat n'est pas bon.
Enfin, j'ai téléchargé le package "readr" et utilisé l'instruction read_csv pour l'interpréter en douceur.
Parce que la date du test est plus complète que celle du train, mais que le nombre d'utilisateurs est manquant, train et test doivent être fusionnés.
test$registered=0test$casual=0test$count=0 data<-rbind(train,test)
Extraire l'heure : vous pouvez utiliser l'horodatage. L'heure ici est relativement simple, c'est le nombre d'heures, vous pouvez donc également intercepter la chaîne directement.
data$hour1<-substr(data$datetime,12,13) table(data$hour1)
Comptez l'utilisation totale par heure, c'est comme ça (pourquoi est-ce si soigné) :

L'étape suivante consiste à utiliser des diagrammes en boîte pour voir la relation entre les utilisateurs, l'heure et les jours de la semaine. Pourquoi utiliser le diagramme en boîte au lieu de l'histogramme ? Parce que le diagramme en boîte a une expression ponctuelle discrète, donc le logarithme est utilisé pour trouver l'ajustement
Comme le montre la figure, en termes de temps, l'utilisation des utilisateurs enregistrés et des utilisateurs non enregistrés Le temps fait une grande différence.
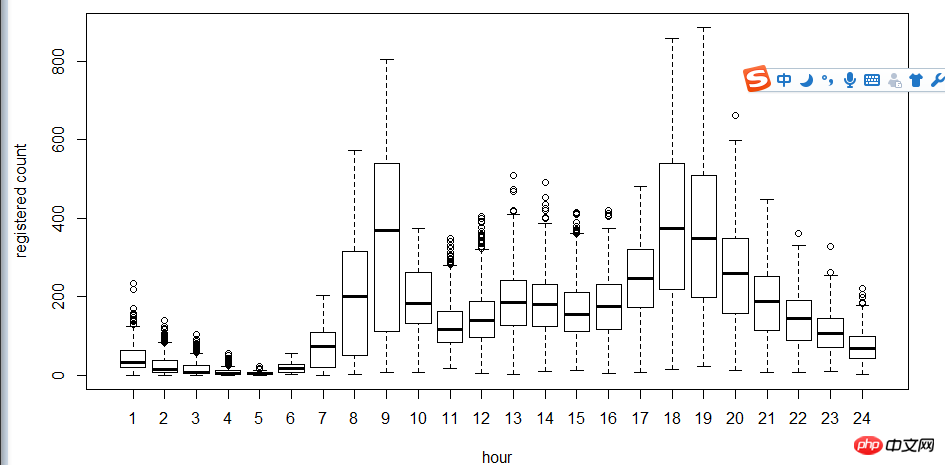
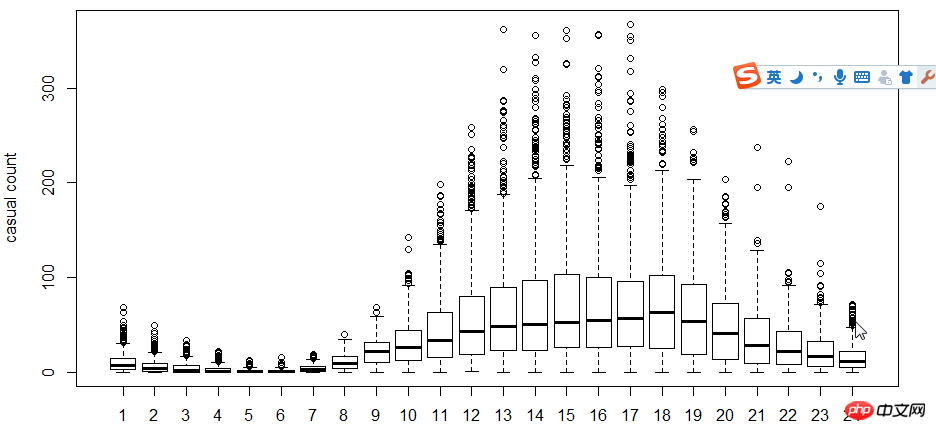
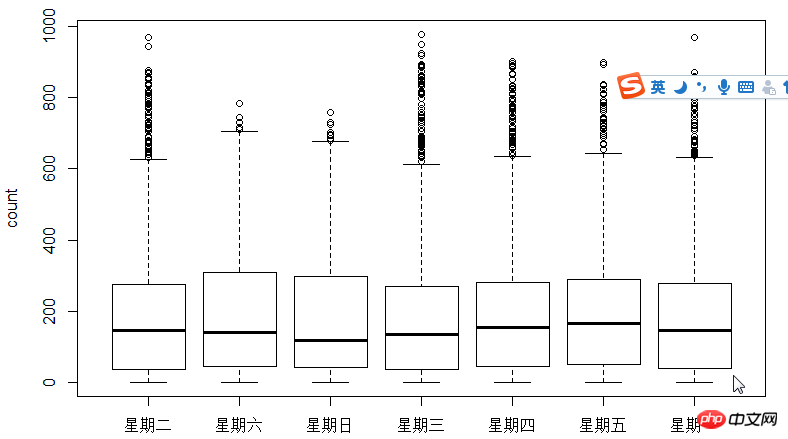
Ensuite, utilisez le coefficient de corrélation cor pour tester la relation entre l'utilisateur, la température, la température perçue, l'humidité et la vitesse du vent.
Coefficient de corrélation : une mesure d'association linéaire entre des variables, testant le degré de corrélation entre différentes données.
La plage de valeurs est [-1, 1]. Plus elle est proche de 0, moins elle est pertinente.
Il ressort des résultats du calcul que le nombre d'utilisateurs est négativement corrélé à la vitesse du vent, qui a un impact plus important que la température.

L'étape suivante consiste à classer des facteurs tels que le temps à l'aide d'arbres de décision, puis à utiliser des forêts aléatoires pour prédire. Algorithmes pour forêts aléatoires et arbres de décision. Cela semble très avancé, mais c’est en fait très couramment utilisé maintenant, vous devez donc l’apprendre.
Le modèle d'arbre de décision est un classificateur non paramétrique simple et facile à utiliser. Il ne nécessite aucune hypothèse a priori sur les données, est rapide dans les calculs, facile à interpréter les résultats, robuste et ne craint pas les données bruyantes et les données manquantes.
Les étapes de calcul de base du modèle d'arbre de décision sont les suivantes : sélectionnez d'abord l'une des n variables indépendantes, trouvez le meilleur point de division et divisez les données en deux groupes. Pour les données groupées, répétez les étapes ci-dessus jusqu'à ce qu'une certaine condition soit remplie.
Il y a trois problèmes importants qui doivent être résolus dans la modélisation d'arbre de décision :
Comment choisir les variables indépendantes
Comment choisir le point de partage
Déterminer les conditions d'arrêt de la division
Prendre l'arbre de décision des utilisateurs et des heures enregistrés,
train$hour1<-as.integer(train$hour1)d<-rpart(registered~hour1,data=train)rpart.plot(d)
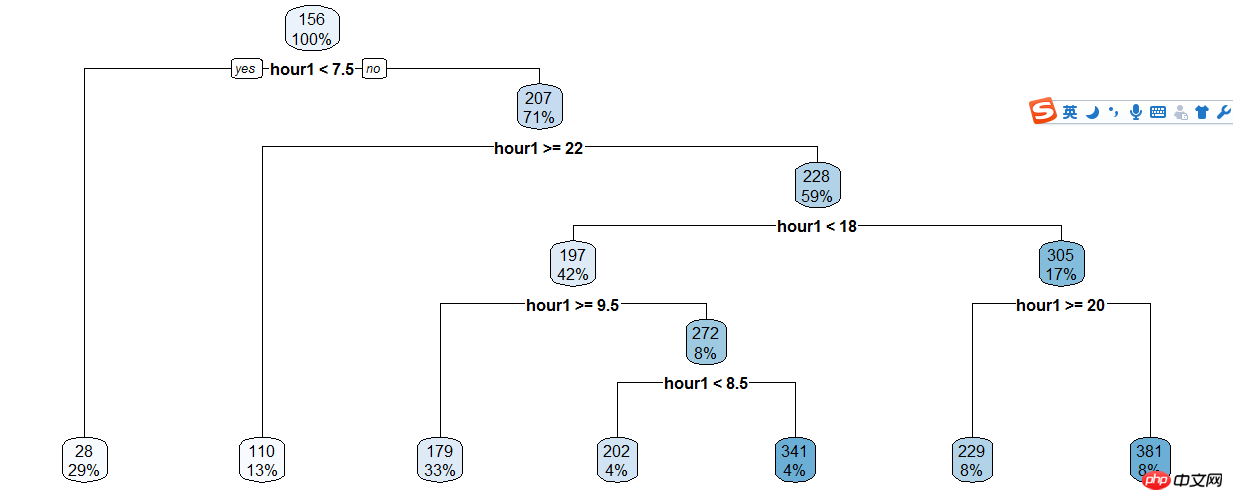
Puis en fonction de l'arbre de décision Les résultats sont classés manuellement, donc le code est toujours plein...
train$hour1<-as.integer(train$hour1)data$dp_reg=0data$dp_reg[data$hour1<7.5]=1data$dp_reg[data$hour1>=22]=2data$dp_reg[data$hour1>=9.5 & data$hour1<18]=3data$dp_reg[data$hour1>=7.5 & data$hour1<18]=4data$dp_reg[data$hour1>=8.5 & data$hour1<18]=5data$dp_reg[data$hour1>=20 & data$hour1<20]=6data$dp_reg[data$hour1>=18 & data$hour1<20]=7
De même, créez des arbres de décision tels que (heure | température) .
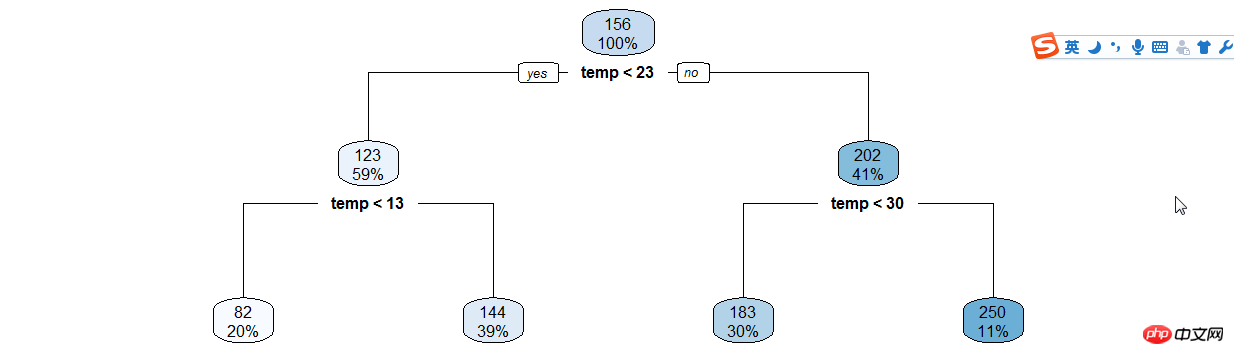
年份月份,周末假日等手动分类
data$year_part=0data$month<-month(data$datatime)data$year_part[data$year=='2011']=1data$year_part[data$year=='2011' & data$month>3]=2data$year_part[data$year=='2011' & data$month>6]=3data$year_part[data$year=='2011' & data$month>9]=4
data$day_type=""data$day_type[data$holiday==0 & data$workingday==0]="weekend"data$day_type[data$holiday==1]="holiday"data$day_type[data$holiday==0 & data$workingday==1]="working day"data$weekend=0data$weekend[data$day=="Sunday"|data$day=="Saturday"]=1
接下来用随机森林语句预测
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,再在其中选取最优的特征。这样决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
ntree指定随机森林所包含的决策树数目,默认为500,通常在性能允许的情况下越大越好;
mtry指定节点中用于二叉树的变量个数,默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。一般是需要进行人为的逐次挑选,确定最佳的m值—摘自datacruiser笔记。这里我主要学习,所以虽然有10000多数据集,但也只定了500。就这500我的小电脑也跑了半天。
train<-dataset.seed(1234) train$logreg<-log(train$registered+1)test$logcas<-log(train$casual+1) fit1<-randomForest(logreg~hour1+workingday+day+holiday+day_type+temp_reg+humidity+atemp+windspeed+season+weather+dp_reg+weekend+year+year_part,train,importance=TRUE,ntree=250) pred1<-predict(fit1,train) train$logreg<-pred1
这里不知道怎么回事,我的day和day_part加进去就报错,只有删掉这两个变量计算,还要研究修补。
然后用exp函数还原
train$registered<-exp(train$logreg)-1 train$casual<-exp(train$logcas)-1 train$count<-test$casual+train$registered
最后把20日后的日期截出来,写入新的csv文件上传。
train2<-train[as.integer(day(data$datetime))>=20,]submit_final<-data.frame(datetime=test$datetime,count=test$count)write.csv(submit_final,"submit_final.csv",row.names=F)
大功告成!
github代码加群
原来的示例是炼数成金网站的kaggle课程第二节,基本按照视频的思路。因为课程没有源代码,所以要自己修补运行完整。历时两三天总算把这个功课做完了。下面要修正的有:
好好理解三个知识点(lubridate包/POSIXlt,log线性,决策树和随机森林);
用WOE和IV代替cor函数分析相关关系;
用其他图形展现的手段分析
随机树变量重新测试学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入学习交流群
626062078,我们一起学Python!
完成了一个“浩大完整”的数据分析,还是很有成就感的!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!