
Maison >Java >javaDidacticiel >Comment utiliser volatile en Java ?
Comment utiliser volatile en Java ?

- PHP中文网original
- 2017-06-21 13:31:382082parcourir
Préface
Nous savons que le rôle du mot clé volatile est d'assurer la visibilité des variables entre plusieurs threads, ce qui est java.util. Le cœur du package concurrent, sans volatile, il n'y aurait pas autant de classes concurrentes à utiliser.
Cet article explique en détail comment le mot clé volatile assure la visibilité des variables entre plusieurs threads. Avant cela, il est nécessaire d'expliquer la connaissance pertinente du cache CPU maîtrisant cette partie de la connaissance. est nécessaire Cela nous permettra de mieux comprendre le principe de volatile, afin de pouvoir mieux et plus correctement utiliser le mot-clé volatile.
Cache CPU
L'émergence du cache CPU vise principalement à résoudre la contradiction entre la vitesse de fonctionnement du CPU et la vitesse de lecture et d'écriture de la mémoire , car la vitesse de fonctionnement du CPU est beaucoup plus rapide que la vitesse de lecture et d'écriture de la mémoire, par exemple :
Un accès à la mémoire principale prend généralement des dizaines à des centaines de cycles d'horloge
Un cache L1 La lecture et l'écriture ne nécessitent que 1 à 2 cycles d'horloge
-
La lecture et l'écriture d'un cache L2 ne nécessitent que des dizaines de cycles d'horloge
Cette différence significative dans la vitesse d'accès peut amener le processeur à attendre longtemps l'arrivée des données ou à écrire des données dans la mémoire.
Sur cette base, désormais le CPU n'accède plus directement à la mémoire pour lire et écrire dans la plupart des cas (le CPU n'a pas de broches connectées à la mémoire), mais c'est le CPU le cache, qui est une mémoire temporaire située entre le CPU et la mémoire. Sa capacité est bien inférieure à celle de la mémoire mais la vitesse d'échange est bien plus rapide que la mémoire. Les données dans le cache représentent une petite partie des données dans la mémoire, mais cette petite partie est sur le point d'être accédée par le CPU dans un court laps de temps. Lorsque le CPU appelle une grande quantité de données, elles peuvent être lues. le cache en premier, accélérant ainsi la vitesse de lecture.
Selon le degré de combinaison de la séquence de lecture avec le CPU, le cache du CPU peut être divisé en :
Cache de niveau 1 : Le cache L1 en abrégé, situé à côté du cœur du CPU, est le cache CPU le plus étroitement intégré au CPU
Cache de deuxième niveau : L2 Cache en abrégé, divisé en interne et externe. Pour les deux puces, le cache L2 de la puce interne fonctionne à la même vitesse que la fréquence principale, tandis que le cache L2 de la puce externe fonctionne à seulement la moitié de la fréquence principale
Cache L3 : Appelé Cache L3, disponible uniquement sur certains processeurs haut de gamme
Les données stockées dans chaque niveau de cache font tous partie du cache de niveau supérieur. Ces trois La difficulté technique et le coût de fabrication de ce cache sont relativement décroissants, donc sa capacité est également relativement croissante.
Lorsque le processeur veut lire une donnée, il la recherche d'abord dans le cache de premier niveau. S'il ne la trouve pas, il la recherche ensuite à partir du deuxième niveau. Si ce n'est toujours pas le cas, il le recherche ensuite dans le cache ou la mémoire de troisième niveau. D'une manière générale, le taux de réussite de chaque niveau de cache est d'environ 80 %, ce qui signifie que 80 % du volume total de données peuvent être trouvés dans le cache de premier niveau et que seulement 20 % du volume total de données doivent être récupérés. le cache de deuxième niveau, le cache L3 ou la lecture en mémoire.
Problèmes causés par l'utilisation du cache du processeur
Utilisez une image pour représenter le processeur - ->Cache CPU-->La relation entre la lecture des données de la mémoire principale :

Lorsque le système est en cours d'exécution Lorsque le CPU effectue des calculs, le processus est le suivant :
Le programme et les données sont chargés dans la mémoire principale
Les instructions et les données sont chargées dans le cache du CPU
Le CPU exécute les instructions et écrit les résultats dans le cache
Les données en cache sont réécrites dans la mémoire principale
Si le serveur est un processeur monocœur, alors ces étapes ne poseront aucun problème, mais si le serveur est un processeur multicœur, alors le problème vient du cache. du processeur Intel Core i7 Prenons le modèle conceptuel comme exemple (l'image est tirée de "Compréhension approfondie des systèmes informatiques") :
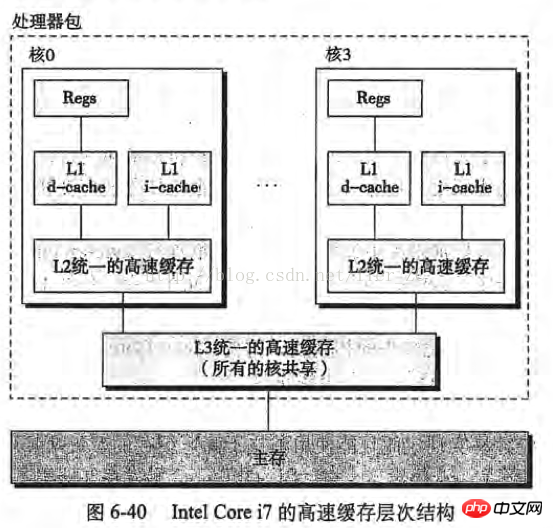
Imaginez simplement la situation suivante :
Le noyau 0 lit un octet Selon le principe de localité, ses octets adjacents sont également lus. dans le cache du core 0
Le Core 3 fait la même chose que ci-dessus, pour que les caches du core 0 et du core 3 aient les mêmes données
Le noyau 0 a modifié cet octet. Après la modification, cet octet a été réécrit dans le cache du noyau 0, mais les informations n'ont pas été réécrites dans la mémoire principale
Le Core 3 accède à l'octet Puisque le Core 0 n'a pas réécrit les données dans la mémoire principale, les données sont désynchronisées
Lorsqu'un CPU modifie des octets dans le cache, les autres CPU du serveur seront avertis et leurs caches sera considéré comme invalide . Par conséquent, dans la situation ci-dessus, le noyau 3 constate que les données dans son cache ne sont pas valides, le noyau 0 réécrira immédiatement ses données dans la mémoire principale, puis le noyau 3 relira les données.
On peut voir que le cache subira une certaine perte de performances lors de l'utilisation d'un processeur multicœur.
Désassemblez le bytecode Java et voyez ce qui est fait au mot-clé volatile au niveau de l'assembleur
Avec la base théorique ci-dessus, nous pouvons étudier comment le mot-clé volatile est implémenté. Écrivez d'abord un code simple :
1 /** 2 * @author 五月的仓颉 3 */ 4 public class LazySingleton { 5 6 private static volatile LazySingleton instance = null; 7 8 public static LazySingleton getInstance() { 9 if (instance == null) {10 instance = new LazySingleton();11 }12 13 return instance;14 }15 16 public static void main(String[] args) {17 LazySingleton.getInstance();18 }19 20 }Décompilez d'abord le fichier .class de ce code et jetez un œil au bytecode généré : 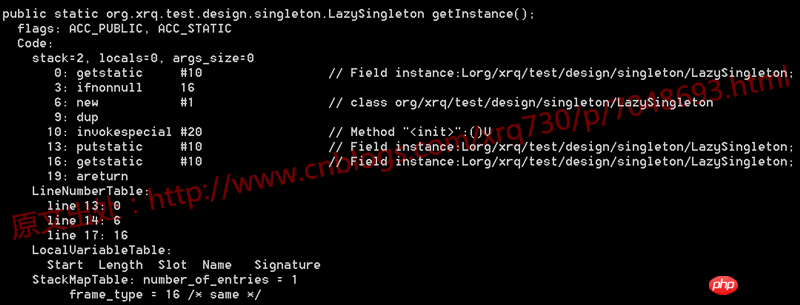
Par conséquent, puisque nous ne pouvons voir aucun indice au niveau du bytecode, voyons quels indices peuvent être vus en convertissant le code en instructions d'assemblage. Il n'est pas difficile de voir le code assembleur correspondant au code ci-dessus sous Windows (un coup de gueule, ce n'est pas difficile à dire, j'ai cherché toutes sortes d'informations pour ce problème, et je me suis presque préparé à installer une machine virtuelle sur le système Linux) , visitez hsdis Vous pouvez télécharger directement l'outil hsdis dans le chemin de l'outil. Après le téléchargement, décompressez-le et placez les deux fichiers hsdis-amd64.dll et hsdis-amd64.lib dans le chemin du serveur %JAVA_HOME%jrebin, comme indiqué ci-dessous :
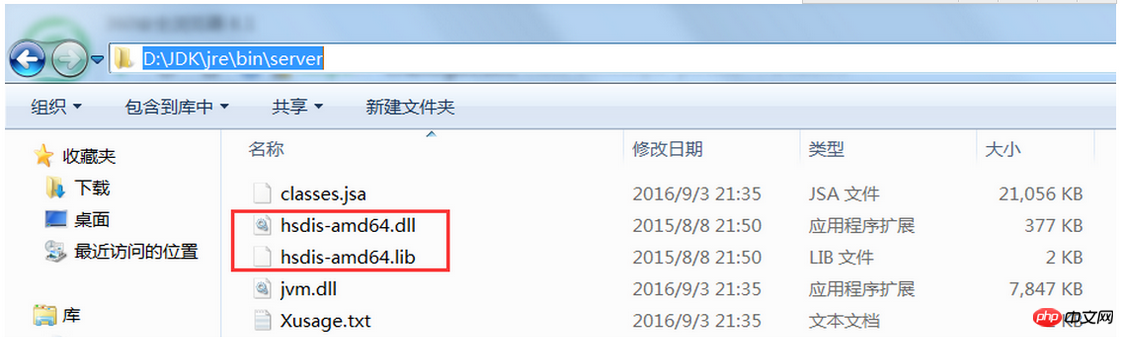
.
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*LazySingleton.getInstance
1 Java HotSpot(TM) 64-Bit Server VM warning: PrintAssembly is enabled; turning on DebugNonSafepoints to gain additional output 2 CompilerOracle: compileonly *LazySingleton.getInstance 3 Loaded disassembler from D:\JDK\jre\bin\server\hsdis-amd64.dll 4 Decoding compiled method 0x0000000002931150: 5 Code: 6 Argument 0 is unknown.RIP: 0x29312a0 Code size: 0x00000108 7 [Disassembling for mach='amd64'] 8 [Entry Point] 9 [Verified Entry Point]10 [Constants]11 # {method} 'getInstance' '()Lorg/xrq/test/design/singleton/LazySingleton;' in 'org/xrq/test/design/singleton/LazySingleton'12 # [sp+0x20] (sp of caller)13 0x00000000029312a0: mov dword ptr [rsp+0ffffffffffffa000h],eax14 0x00000000029312a7: push rbp15 0x00000000029312a8: sub rsp,10h ;*synchronization entry16 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@-1 (line 13)17 0x00000000029312ac: mov r10,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')}18 0x00000000029312b6: mov r11d,dword ptr [r10+58h]19 ;*getstatic instance20 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@0 (line 13)21 0x00000000029312ba: test r11d,r11d22 0x00000000029312bd: je 29312e0h23 0x00000000029312bf: mov r10,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')}24 0x00000000029312c9: mov r11d,dword ptr [r10+58h]25 0x00000000029312cd: mov rax,r1126 0x00000000029312d0: shl rax,3h ;*getstatic instance27 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@16 (line 17)28 0x00000000029312d4: add rsp,10h29 0x00000000029312d8: pop rbp30 0x00000000029312d9: test dword ptr [330000h],eax ; {poll_return}31 0x00000000029312df: ret32 0x00000000029312e0: mov rax,qword ptr [r15+60h]33 0x00000000029312e4: mov r10,rax34 0x00000000029312e7: add r10,10h35 0x00000000029312eb: cmp r10,qword ptr [r15+70h]36 0x00000000029312ef: jnb 293135bh37 0x00000000029312f1: mov qword ptr [r15+60h],r1038 0x00000000029312f5: prefetchnta byte ptr [r10+0c0h]39 0x00000000029312fd: mov r11d,0e07d00b2h ; {oop('org/xrq/test/design/singleton/LazySingleton')}40 0x0000000002931303: mov r10,qword ptr [r12+r11*8+0b0h]41 0x000000000293130b: mov qword ptr [rax],r1042 0x000000000293130e: mov dword ptr [rax+8h],0e07d00b2h43 ; {oop('org/xrq/test/design/singleton/LazySingleton')}44 0x0000000002931315: mov dword ptr [rax+0ch],r12d45 0x0000000002931319: mov rbp,rax ;*new ; - org.xrq.test.design.singleton.LazySingleton::getInstance@6 (line 14)46 0x000000000293131c: mov rdx,rbp47 0x000000000293131f: call 2907c60h ; OopMap{rbp=Oop off=132}48 ;*invokespecial <init>49 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@10 (line 14)50 ; {optimized virtual_call}51 0x0000000002931324: mov r10,rbp52 0x0000000002931327: shr r10,3h53 0x000000000293132b: mov r11,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')}54 0x0000000002931335: mov dword ptr [r11+58h],r10d55 0x0000000002931339: mov r10,7ada9e428h ; {oop(a 'java/lang/Class' = 'org/xrq/test/design/singleton/LazySingleton')}56 0x0000000002931343: shr r10,9h57 0x0000000002931347: mov r11d,20b2000h58 0x000000000293134d: mov byte ptr [r11+r10],r12l59 0x0000000002931351: lock add dword ptr [rsp],0h ;*putstatic instance60 ; - org.xrq.test.design.singleton.LazySingleton::getInstance@13 (line 14)61 0x0000000002931356: jmp 29312bfh62 0x000000000293135b: mov rdx,703e80590h ; {oop('org/xrq/test/design/singleton/LazySingleton')}63 0x0000000002931365: nop64 0x0000000002931367: call 292fbe0h ; OopMap{off=204}65 ;*new ; - org.xrq.test.design.singleton.LazySingleton::getInstance@6 (line 14)66 ; {runtime_call}67 0x000000000293136c: jmp 2931319h68 0x000000000293136e: mov rdx,rax69 0x0000000002931371: jmp 2931376h70 0x0000000002931373: mov rdx,rax ;*new ; - org.xrq.test.design.singleton.LazySingleton::getInstance@6 (line 14)71 0x0000000002931376: add rsp,10h72 0x000000000293137a: pop rbp73 0x000000000293137b: jmp 2932b20h ; {runtime_call}74 [Stub Code]75 0x0000000002931380: mov rbx,0h ; {no_reloc}76 0x000000000293138a: jmp 293138ah ; {runtime_call}77 [Exception Handler]78 0x000000000293138f: jmp 292fca0h ; {runtime_call}79 [Deopt Handler Code]80 0x0000000002931394: call 2931399h81 0x0000000002931399: sub qword ptr [rsp],5h82 0x000000000293139e: jmp 2909000h ; {runtime_call}83 0x00000000029313a3: hlt84 0x00000000029313a4: hlt85 0x00000000029313a5: hlt86 0x00000000029313a6: hlt87 0x00000000029313a7: hlt
之所以定位到这两行是因为这里结尾写明了line 14,line 14即volatile变量instance赋值的地方。后面的add dword ptr [rsp],0h都是正常的汇编语句,意思是将双字节的栈指针寄存器+0,这里的关键就是add前面的lock指令,后面详细分析一下lock指令的作用和为什么加上lock指令后就能保证volatile关键字的内存可见性。
lock指令做了什么
之前有说过IA-32架构,关于CPU架构的问题大家有兴趣的可以自己查询一下,这里查询一下IA-32手册关于lock指令的描述,没有IA-32手册的可以去这个地址下载IA-32手册下载地址,是个中文版本的手册。
我摘抄一下IA-32手册中关于lock指令作用的一些描述(因为lock指令的作用在手册中散落在各处,并不是在某一章或者某一节专门讲):
在修改内存操作时,使用LOCK前缀去调用加锁的读-修改-写操作,这种机制用于多处理器系统中处理器之间进行可靠的通讯,具体描述如下: (1)在Pentium和早期的IA-32处理器中,LOCK前缀会使处理器执行当前指令时产生一个LOCK#信号,这种总是引起显式总线锁定出现 (2)在Pentium4、Inter Xeon和P6系列处理器中,加锁操作是由高速缓存锁或总线锁来处理。如果内存访问有高速缓存且只影响一个单独的高速缓存行,那么操作中就会调用高速缓存锁,而系统总线和系统内存中的实际区域内不会被锁定。同时,这条总线上的其它Pentium4、Intel Xeon或者P6系列处理器就回写所有已修改的数据并使它们的高速缓存失效,以保证系统内存的一致性。如果内存访问没有高速缓存且/或它跨越了高速缓存行的边界,那么这个处理器就会产生LOCK#信号,并在锁定操作期间不会响应总线控制请求
32位IA-32处理器支持对系统内存中的某个区域进行加锁的原子操作。这些操作常用来管理共享的数据结构(如信号量、段描述符、系统段或页表),两个或多个处理器可能同时会修改这些数据结构中的同一数据域或标志。处理器使用三个相互依赖的机制来实现加锁的原子操作:1、保证原子操作2、总线加锁,使用LOCK#信号和LOCK指令前缀3、高速缓存相干性协议,确保对高速缓存中的数据结构执行原子操作(高速缓存锁)。这种机制存在于Pentium4、Intel Xeon和P6系列处理器中
IA-32处理器提供有一个LOCK#信号,会在某些关键内存操作期间被自动激活,去锁定系统总线。当这个输出信号发出的时候,来自其他处理器或总线代理的控制请求将被阻塞。软件能够通过预先在指令前添加LOCK前缀来指定需要LOCK语义的其它场合。 在Intel386、Intel486、Pentium处理器中,明确地对指令加锁会导致LOCK#信号的产生。由硬件设计人员来保证系统硬件中LOCK#信号的可用性,以控制处理器间的内存访问。 对于Pentinum4、Intel Xeon以及P6系列处理器,如果被访问的内存区域是在处理器内部进行高速缓存的,那么通常不发出LOCK#信号;相反,加锁只应用于处理器的高速缓存。
<span style="color: #000000">为显式地强制执行LOCK语义,软件可以在下列指令修改内存区域时使用LOCK前缀。当LOCK前缀被置于其它指令之前或者指令没有对内存进行写操作(也就是说目标操作数在寄存器中)时,会产生一个非法操作码异常(#UD)。 【</span><span style="color: #800080">1</span><span style="color: #000000">】位测试和修改指令(BTS、BTR、BTC) 【</span><span style="color: #800080">2</span><span style="color: #000000">】交换指令(XADD、CMPXCHG、CMPXCHG8B) 【</span><span style="color: #800080">3</span><span style="color: #000000">】自动假设有LOCK前缀的XCHG指令<br>【4】下列单操作数的算数和逻辑指令:INC、DEC、NOT、NEG<br>【5】下列双操作数的算数和逻辑指令:ADD、ADC、SUB、SBB、AND、OR、XOR<br>一个加锁的指令会保证对目标操作数所在的内存区域加锁,但是系统可能会将锁定区域解释得稍大一些。<br>软件应该使用相同的地址和操作数长度来访问信号量(用作处理器之间发送信号的共享内存)。例如,如果一个处理器使用一个字来访问信号量,其它处理器就不应该使用一个字节来访问这个信号量。<br>总线锁的完整性不收内存区域对齐的影响。加锁语义会一直持续,以满足更新整个操作数所需的总线周期个数。但是,建议加锁访问应该对齐在它们的自然边界上,以提升系统性能:<br>【1】任何8位访问的边界(加锁或不加锁)<br>【2】锁定的字访问的16位边界<br>【3】锁定的双字访问的32位边界<br>【4】锁定的四字访问的64位边界<br>对所有其它的内存操作和所有可见的外部事件来说,加锁的操作都是原子的。所有取指令和页表操作能够越过加锁的指令。加锁的指令可用于同步一个处理器写数据而另一个处理器读数据的操作。</span>
IA-32架构提供了几种机制用来强化或弱化内存排序模型,以处理特殊的编程情形。这些机制包括: 【1】I/O指令、加锁指令、LOCK前缀以及串行化指令等,强制在处理器上进行较强的排序 【2】SFENCE指令(在Pentium III中引入)和LFENCE指令、MFENCE指令(在Pentium4和Intel Xeon处理器中引入)提供了某些特殊类型内存操作的排序和串行化功能 ...(这里还有两条就不写了) 这些机制可以通过下面的方式使用。 总线上的内存映射设备和其它I/O设备通常对向它们缓冲区写操作的顺序很敏感,I/O指令(IN指令和OUT指令)以下面的方式对这种访问执行强写操作的排序。在执行了一条I/O指令之前,处理器等待之前的所有指令执行完毕以及所有的缓冲区都被都被写入了内存。只有取指令和页表查询能够越过I/O指令,后续指令要等到I/O指令执行完毕才开始执行。
反复思考IA-32手册对lock指令作用的这几段描述,可以得出lock指令的几个作用:
锁总线,其它CPU对内存的读写请求都会被阻塞,直到锁释放,不过实际后来的处理器都采用锁缓存替代锁总线,因为锁总线的开销比较大,锁总线期间其他CPU没法访问内存
lock后的写操作会回写已修改的数据,同时让其它CPU相关缓存行失效,从而重新从主存中加载最新的数据
不是内存屏障却能完成类似内存屏障的功能,阻止屏障两遍的指令重排序
(1)中写了由于效率问题,实际后来的处理器都采用锁缓存来替代锁总线,这种场景下多缓存的数据一致是通过缓存一致性协议来保证的,我们来看一下什么是缓存一致性协议。
缓存一致性协议
讲缓存一致性之前,先说一下缓存行的概念:
缓存是分段(line)的,一个段对应一块存储空间,我们称之为缓存行,它是CPU缓存中可分配的最小存储单元,大小32字节、64字节、128字节不等,这与CPU架构有关。当CPU看到一条读取内存的指令时,它会把内存地址传递给一级数据缓存,一级数据缓存会检查它是否有这个内存地址对应的缓存段,如果没有就把整个缓存段从内存(或更高一级的缓存)中加载进来。注意,这里说的是一次加载整个缓存段,这就是上面提过的局部性原理
上面说了,LOCK#会锁总线,实际上这不现实,因为锁总线效率太低了。因此最好能做到:使用多组缓存,但是它们的行为看起来只有一组缓存那样。缓存一致性协议就是为了做到这一点而设计的,就像名称所暗示的那样,这类协议就是要使多组缓存的内容保持一致。
缓存一致性协议有多种,但是日常处理的大多数计算机设备都属于"嗅探(snooping)"协议,它的基本思想是:
<span style="color: #000000">所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线:缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个CPU缓存可以读写内存)。<br>CPU缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其它处理器马上知道这块内存在它们的缓存段中已失效。</span>
Le protocole MESI est actuellement le protocole de cohérence de cache le plus courant. Dans le protocole MESI, chaque ligne de cache a 4 états, qui peuvent être représentés par 2 bits. Ils sont :
<.>
Les états I, S et M ici ont déjà des concepts correspondants : segments de cache invalides/déchargés, propres et sales. Le nouveau point de connaissance ici est donc uniquement l'état E, qui représente un accès exclusif. Cet état résout le problème « avant de commencer à modifier un certain morceau de mémoire, nous devons le dire aux autres processeurs » : uniquement lorsque la ligne de cache est dans le cache. Dans l'état E ou M, le processeur peut l'écrire, c'est-à-dire que dans ces deux états seulement, le processeur occupe exclusivement cette ligne de cache. Lorsque le processeur souhaite écrire sur une certaine ligne de cache, s'il n'a pas de droits exclusifs, il doit d'abord envoyer une demande "Je veux des droits exclusifs" au bus Cela informera les autres processeurs d'écrire le. même ligne de cache qu'ils possèdent. La copie du segment de cache est invalidée (le cas échéant). Ce n'est qu'après avoir obtenu les droits exclusifs que le processeur peut commencer à modifier les données - et à ce stade, le processeur sait qu'il n'y a qu'une seule copie de cette ligne de cache, dans mon propre cache, donc il n'y aura pas de conflits. Statut "Partager". S'il s'agit d'une ligne de cache modifiée, le contenu doit d'abord être réécrit en mémoire.
Retour sur la lecture et l'écriture de variables volatiles via l'instruction de verrouillage
Je crois qu'avec ce qui précède pour L'explication du verrouillage et le principe de mise en œuvre du mot-clé volatile devraient être clairs en un coup d'œil. Regardez d'abord une image :
La mémoire de travail est en fait une abstraction des registres et du cache du processeur, ou en d'autres termes la mémoire de travail de chaque thread peut également être simplement comprise comme des registres CPU et du cache. 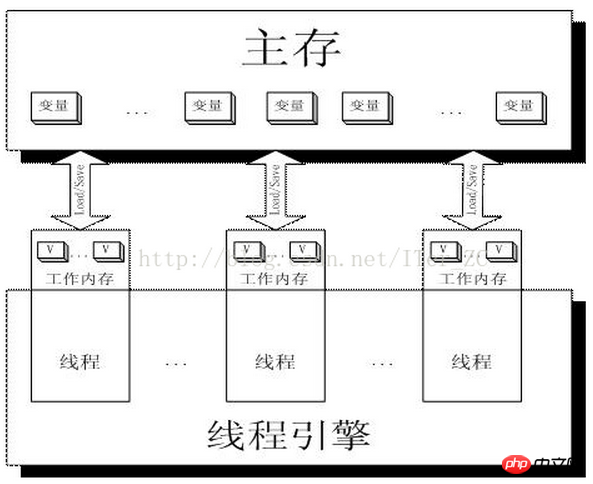
Ensuite, lors de l'écriture de deux threads, Thread-A et Threab-B, pour faire fonctionner une variable volatile i dans la mémoire principale en même temps, Thread-A écrit la variable i, puis :
Thread-A émet la commande LOCK#
émet la commande LOCK# pour verrouiller le bus (ou verrouiller la ligne de cache), et en même temps invalider le contenu de la ligne de cache dans le cache Thread-B
-
Thread-A réécrit le dernier i modifié
dans la mémoire principale Thread-B lit la variable i, puis :
Thread-B trouve l'adresse correspondante La ligne de cache est verrouillée, en attendant que le verrou soit libéré. Le protocole de cohérence du cache garantira qu'il lit la dernière valeur
<.> On peut voir à partir de cela que volatile est la clé. Il n'y a fondamentalement aucune différence entre lire des mots et lire des variables ordinaires. La principale différence réside dans l'opération d'écriture des variables.
Postscript
J'ai personnellement déjà quelques connaissances sur le rôle des mots-clés volatils. Des malentendus déroutants. Après avoir profondément compris le rôle du mot-clé volatile, je sens que ma compréhension de volatile est beaucoup plus profonde. Je crois que si vous lisez cet article, tant que vous êtes prêt à réfléchir et à étudier, vous ressentirez le même sentiment d'illumination et d'illumination que moi ^_^
Références
"Manuel du développeur de logiciels d'architecture IA-32 Volume 3 : Guide de programmation système"
"Programmation simultanée Java L'art de""Compréhension approfondie de la machine virtuelle Java : fonctionnalités avancées et meilleures pratiques JVM"
PrintAssembly Afficher les notes sur le code d'assemblage volatile
Introduction à la cohérence du cache
Parlons de la haute concurrence (34) Modèle de mémoire Java (2) Comprendre le cache du processeur Comment ça marche
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!