
Maison >développement back-end >Tutoriel Python >Scrapy capture des exemples de reportages universitaires
Scrapy capture des exemples de reportages universitaires

- PHP中文网original
- 2017-06-21 10:47:111788parcourir
Récupérez toutes les demandes d'actualité sur le site officiel de l'École d'administration publique de l'Université du Sichuan ().
Processus expérimental
1. Déterminez la cible d'exploration.
2. .
3. Règles d'exploration « Écrire/Déboguer ».
4. Obtenir les données d'exploration
1. Déterminer la cible d'exploration
La cible que nous devons explorer cette fois est le Sichuan. Toutes les actualités et informations sur l'École de politique publique et de gestion de l'Université. Nous devons donc connaître la structure de mise en page du site officiel de l'École de politique publique et de gestion.
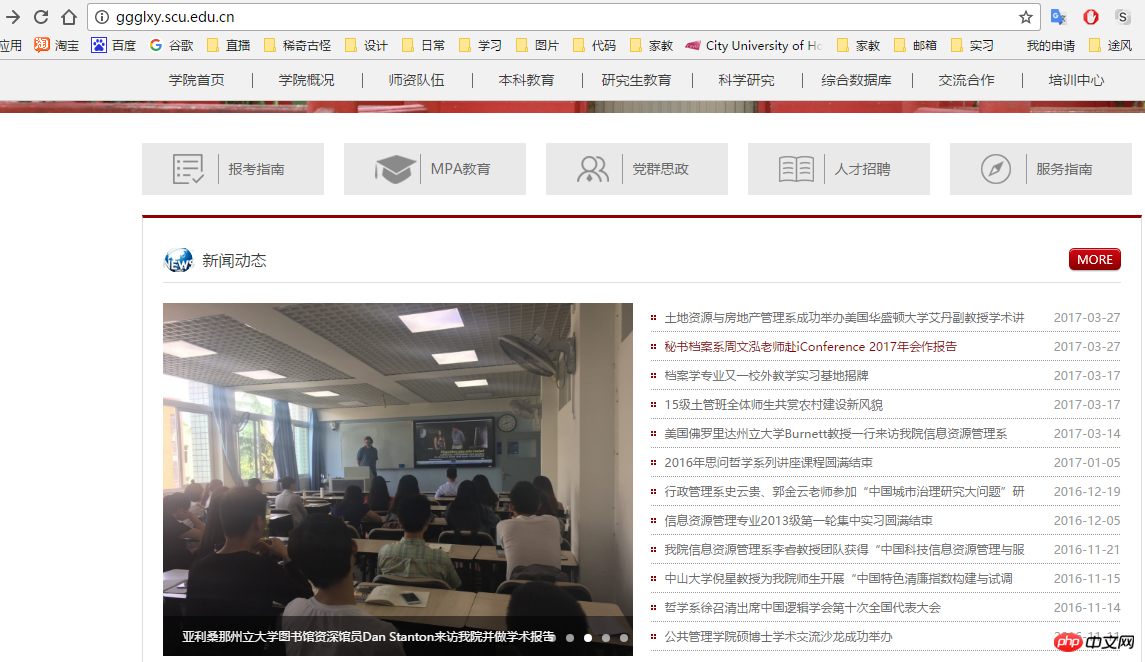
<.>WeChat screenshot_20170515223045.png

Paste_Image .png
Nous avons vu la rubrique actualités spécifique, mais cela ne correspond évidemment pas à notre exploration Besoins : la page Web d'actualités actuelle ne peut explorer que l'heure, le titre et l'URL de l'actualité, mais elle ne peut pas capturer le contenu de l'actualité. Nous devons donc accéder à la page de détails de l'actualité pour capturer le contenu spécifique de l'actualité
2. Formuler des règles d'exploration
Grâce à l'analyse de la première partie, nous penserons que si nous voulons récupérer les informations spécifiques d'une actualité, nous devons cliquer sur la page d'actualité pour entrer. la page de détails de l'actualité pour récupérer le contenu spécifique de l'actualité. Cliquons sur une actualité pour l'essayer
 Paste_Image.png
Paste_Image.pngNous avons constaté cela. nous pouvons récupérer les données dont nous avons besoin directement à partir de la page de détails de l'actualité : titre, heure, contenu.URL.
D'accord, nous avons maintenant une idée claire desaisir une actualité. Mais comment. explorer tout le contenu de l'actualité ?
Ce n'est évidemment pas difficile pour nous
Donc, pour organiser nos pensées, nous pouvons penser à une règle d'exploration évidente :
3. Règles d'exploration « Écriture/Débogage »
Afin de réduire au maximum la granularité du débogage du robot. combinera les modules d'écriture et de débogage.
Dans le robot d'exploration, je mettrai en œuvre les points fonctionnels suivants :3. Explorez toutes les actualités via une boucle. Les points de connaissance correspondants de
sont. :
1. Explorer les données de base sous une page.
2. Explorer deux fois les données analysées.3. Explorer toutes les données de la page Web via une boucle.3.1 Grimpez tous les liens d'actualités sous la colonne d'actualités sur une seule page
Sans plus tarder, commençons maintenant.


Testez et réussissez !
import scrapyclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())

<.>Écriture du code
Après intégration dans le code d'origine, il y a :#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):item = GgglxyItem()item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()item['href'] = responseitem['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")item['content'] = data[0].xpath('string(.)').extract()[0]
yield itemTest, réussi !import scrapyfrom ggglxy.items import GgglxyItemclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())#调用新闻抓取方法yield scrapy.Request(url, callback=self.parse_dir_contents)#进入新闻详情页的抓取方法 def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]yield itemPaste_Image.png
A ce moment, nous ajoutons une boucle :
NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUM
yield scrapy.Request(next_url, callback=self.parse)Test :import scrapyfrom ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())yield scrapy.Request(URL, callback=self.parse_dir_contents)global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield itemPaste_Image.png
抓到的数量为191,但是我们看官网发现有193条新闻,少了两条.
为啥呢?我们注意到log的error有两条:
定位问题:原来发现,学院的新闻栏目还有两条隐藏的二级栏目:
比如:

对应的URL为

URL都长的不一样,难怪抓不到了!
那么我们还得为这两条二级栏目的URL设定专门的规则,只需要加入判断是否为二级栏目:
if URL.find('type') != -1: yield scrapy.Request(URL, callback=self.parse)
组装原函数:
import scrapy
from ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())if URL.find('type') != -1:yield scrapy.Request(URL, callback=self.parse)yield scrapy.Request(URL, callback=self.parse_dir_contents)
global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

我们发现,抓取的数据由以前的193条增加到了238条,log里面也没有error了,说明我们的抓取规则OK!
4.获得抓取数据
<code class="haxe"> scrapy crawl <span class="hljs-keyword">new<span class="hljs-type">s_info_2 -o <span class="hljs-number">0016.json</span></span></span></code><br/><br/>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!