
Maison >développement back-end >Tutoriel Python >images de robot d'exploration python, exploiter Excel
images de robot d'exploration python, exploiter Excel

- PHP中文网original
- 2017-06-20 14:01:292082parcourir
J'ai récemment regardé les cours en ligne en direct de Tanzhou Education et j'ai été très impressionné par le côté pratique des cours du professeur. Étudiez-le simplement comme vos propres notes. Nous savons tous que lorsque vous apprenez un programme, vous le copiez d'abord, puis vous le créez. Ici, je suis entièrement l’explication du professeur et je la copie pour l’étudier.
1. Python capture des photos de filles Douban.
Outils : python3.6.0 ; bs4.6.0 ; xlwt (1.2.0) nécessitent les versions correspondantes. J'ai déjà installé bs4 mais lors de l'exécution, il indique que la version ne correspond pas. Vous pouvez mettre à niveau en ligne : pip install update buautifulsoup4
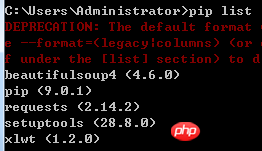
1. pip list, vous pouvez afficher l'installation locale.
1. Explorez la photo de la fille Douban et connaissez son adresse, url = ''.
2. Vérifiez le code source de la page Web, F12, réseau, et recherchez les informations de la page Web capturées à gauche pour trouver l'agent utilisateur. Le but principal est de imiter la connexion du navigateur <.> et prévenez les anti-crawlers.


1 import urllib 2 import urllib.request 3 from bs4 import BeautifulSoup 4 url = '' 5 x=0 6 #获取源码 7 #自定义函数 8 #User-Agent模拟浏览器进行访问,反爬虫 9 def crawl(url):10 headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3088.3 Safari/537.36'}11 req=urllib.request.Request(url,headers=headers)#创建对象12 page=urllib.request.urlopen(req,timeout=20)#设置超时13 contents=page.read()#获取源码14 #print (contents.decode())15 soup = BeautifulSoup(contents,'html.parser')#html.parser主要是解析网页的一种形式。16 my_girl=soup.find_all('img')#找到所有img标签17 # 5.获取图片18 for girl in my_girl:#遍历19 link=girl.get('src')#获取src20 print(link)21 global x#全局变量22 # 6.下载 urlretrieve23 urllib.request.urlretrieve(link,'image\%s.jpg'%x)#下载,urlretrieve(需要下载的,路径)24 x+=125 print('正在下载第%s张'%x)26 #7.多页27 for page in range(1,10):#range本身自动生成整数序列,爬取多页图片。28 #page+=129 url='{}'.format(page)#30 #url = 'http://www.dbmeinv.com/?pager_offset=%d' % page31 crawl(url)32 33 print('图片下载完毕')
import requestsfrom bs4 import BeautifulSoupimport xlwtdef get_content(url,headers=None,proxy=None):
html=requests.get(url,headers=headers).contentreturn htmldef get_url(html):
soup = BeautifulSoup(html,'html.parser')
shop_url_list=soup.find_all('div',class_='tit')#class在Python是关键字,# 列表推导式return [i.find('a')['href'] for i in shop_url_list]#商品的详细信息,名字,评论,人均def get_detail_content(html):
soup=BeautifulSoup(html,'html.parser')
price=soup.find('span',id='avgPriceTitle').text
evaluation=soup.find('span',id='comment_score').find_all('span',class_='item')#find_all是有多个,这里三个#for i in evaluation: # print(i.text)the_star=soup.find('div',class_='brief-info').find('span')['title']
title=soup.find('div',class_='breadcrumb').find('span').text
comments=soup.find('span',id='reviewCount').text
address=soup.find('span',itemprop='street-address').textprint(u'店名:'+title)for i in evaluation:print(i.text)print(price)print(u'评论数量:'+comments)print(u'地址:'+address.strip())print(u'评价星级:'+the_star)print('================')return (title,evaluation[0].text,evaluation[1].text,evaluation[2].text,price,comments,address,the_star)if __name__=='__main__':
items=[]
start_url=''base_url=''headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3088.3 Safari/537.36','Cookie':'_hc.v=461407bd-5a08-f3fa-742e-681a434748bf.1496365678; __utma=1.1522471392.1496365678.1496365678.1496365678.1; __utmc=1; __utmz=1.1496365678.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; PHOENIX_ID=0a0102b7-15c6659b548-25fc89; s_ViewType=10; JSESSIONID=E815A43E028078AFA73AF08D9C9E4A15; aburl=1; cy=344; cye=changsha; __mta=147134984.1496365814252.1496383356849.1496383925586.4'}
start_html=get_content(start_url)#一页# url_list=get_url(start_html)#多页url_list = [base_url + url for url in get_url(start_html)]for i in url_list:
detail_html=get_content(i,headers=headers)
item=get_detail_content(detail_html)
items.append(item)#写excel,txt差别,Excel:xlwgnewTable='DZDP.xls'wb=xlwt.Workbook(encoding='utf-8')
ws=wb.add_sheet('test1')
headData=['商户名字','口味评分','环境评分','服务评分','人均价格','评论数量','地址','商户评价']for colnum in range(0,8):
ws.write(0,colnum,headData[colnum],xlwt.easyxf('font:bold on'))
index=1lens=len(items)for j in range(0,lens):for i in range(0,8):
ws.write(index,i,items[j][i])
index +=1wb.save(newTable)Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!