
Maison >base de données >tutoriel mysql >Cas de test d'optimisation de la pagination MySQL
Cas de test d'optimisation de la pagination MySQL

- PHP中文网original
- 2017-06-20 15:27:551425parcourir
Récemment, j'ai accidentellement vu un scénario de test pour l'optimisation de la pagination MySQL. Sans explication très précise du scénario de test, une solution classique a été proposée,
Car en réalité, de nombreuses situations ne sont pas résolues. Pour pouvoir résumer des pratiques ou des règles générales, nous devons envisager de nombreux scénarios
En même temps, face aux moyens de parvenir à l'optimisation, nous devons enquêter sur les raisons de la même approche, si la scène est modifiée et la. l'effet d'optimisation ne peut pas être obtenu, les raisons doivent être recherchées.
J'ai personnellement exprimé des doutes sur l'utilisation de ce scénario, puis je l'ai testé moi-même, j'ai trouvé quelques problèmes et j'ai également confirmé certaines idées attendues.
Cet article fera une analyse simple sur l'optimisation de la pagination MySQL, en partant de la situation la plus simple.
Autre : L'environnement de test de cet article est le serveur cloud avec la configuration la plus basse. Relativement parlant, l'environnement matériel du serveur est limité, mais les différentes déclarations (méthodes d'écriture) doivent être "égales"
Approche « d'optimisation » de pagination classique de MySQL
Dans l'optimisation de pagination MySQL, il existe un problème classique. Plus les données « en arrière » sont interrogées, plus elles sont lentes. (selon la table) Le type d'index, pour les index structurés en B-tree, il en va de même dans SQL Server)
select * from t order by id limit m,n. C'est-à-dire qu'à mesure que M augmente, l'interrogation de la même quantité de données deviendra de plus en plus lente
Face à ce problème, une approche classique est née, qui est similaire à (ou une variante de) ) Le La manière d'écrire suivante
consiste d'abord à trouver l'identifiant dans la plage de pagination séparément, puis à l'associer à la table de base, et enfin à interroger les données requises
sélectionner * à partir de t
jointure interne (
select id from t order by id limit m,n)t1 on t1.id = t.id
S'il y a des conditions de filtre, l'instruction
sql devient Elle devient select * from. t où *** ordre par id limite m,n
Si vous suivez la même méthode, réécrivez-le comme quelque chose comme
select * from t
jointure interne (sélectionnez l'identifiant de t où *** ordre par id limit m,n )t1 on t1.id = t.id
Dans ce cas, l'instruction SQL réécrite peut-elle toujours atteindre l'objectif d'optimisation ?
Configuration de l'environnement de test
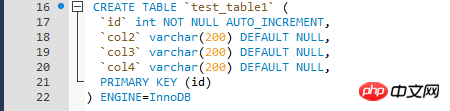
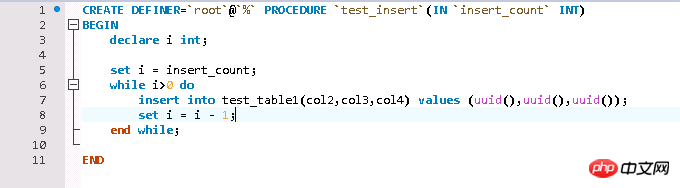
Les données de test sont relativement simples et sont écrites dans un boucle à travers la procédure stockée Données de test, table du moteur InnoDB de la table de test.

Les raisons de l'optimisation des requêtes de pagination
Jetons d'abord un coup d'œil à ce problème classique lors de la pagination, plus la requête est "en arrière", plus la réponse est lente. est
Test 1 : interroger les 1 à 20 premières lignes de données, 0,01 seconde
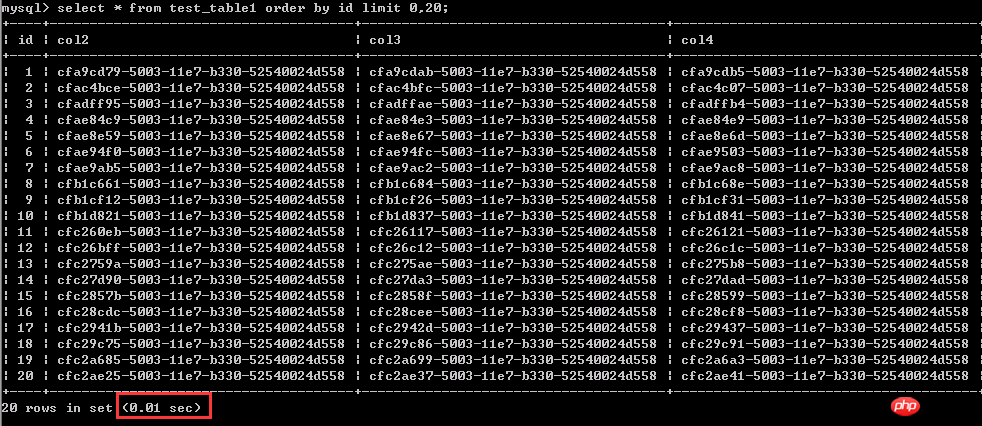 La même requête concerne 20 lignes de données, interrogeant relativement " plus tard", comme les lignes de données 4900001-4900020 ici, cela a pris 1,97 seconde.
La même requête concerne 20 lignes de données, interrogeant relativement " plus tard", comme les lignes de données 4900001-4900020 ici, cela a pris 1,97 seconde.
 On peut voir à partir de cela que lorsque les conditions de requête restent inchangées, plus la requête est éloignée, plus l'efficacité de la requête est faible. Cela peut être simplement compris comme : la même recherche de 20 lignes de données, plus les données sont éloignées, plus le coût de la requête est élevé.
On peut voir à partir de cela que lorsque les conditions de requête restent inchangées, plus la requête est éloignée, plus l'efficacité de la requête est faible. Cela peut être simplement compris comme : la même recherche de 20 lignes de données, plus les données sont éloignées, plus le coût de la requête est élevé.
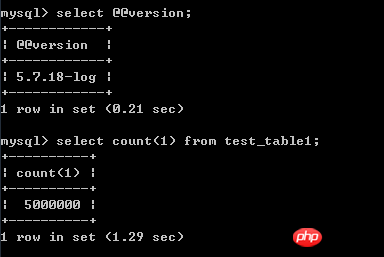
L'environnement de test est centos 7, mysql 5.7, les données de la table de test sont 500W
Reproduire l'"optimisation" de pagination classique Lorsqu'il n'y a pas de conditions de filtre et que la colonne de tri est un index clusterisé, il n'y aura aucune amélioration
Ici, comparons les performances des deux méthodes d'écriture suivantes lorsque des colonnes d'index clusterisées sont utilisées comme conditions de tri
select * from t order by id limit m,n.sélectionnez * dans t
jointure interne (sélectionnez l'identifiant dans t ordre par limite d'identifiant m,n)t1 sur t1.id = t.id
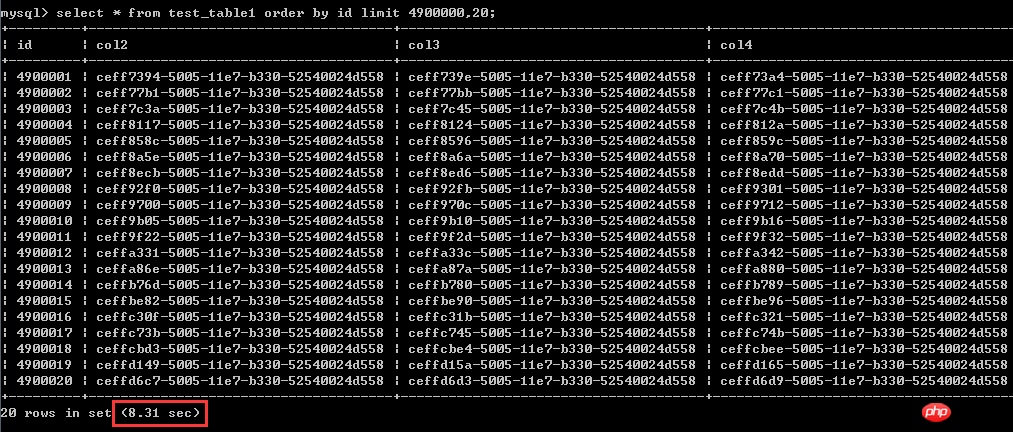
La première façon de écrit :
select * from test_table1 order by id asc limit 4900000,20; Les résultats du test sont affichés dans la capture d'écran, Le temps d'exécution est de 8,31 secondes
Le deuxième type d'écriture réécrite :
sélectionnez t1.* dans test_table1 t1
jointure interne (sélectionnez l'identifiant dans test_table1 par limite d'identifiant 4900000,20)t2 sur t1.id = t2.id;Exécuter Le temps est de 8,43 secondes
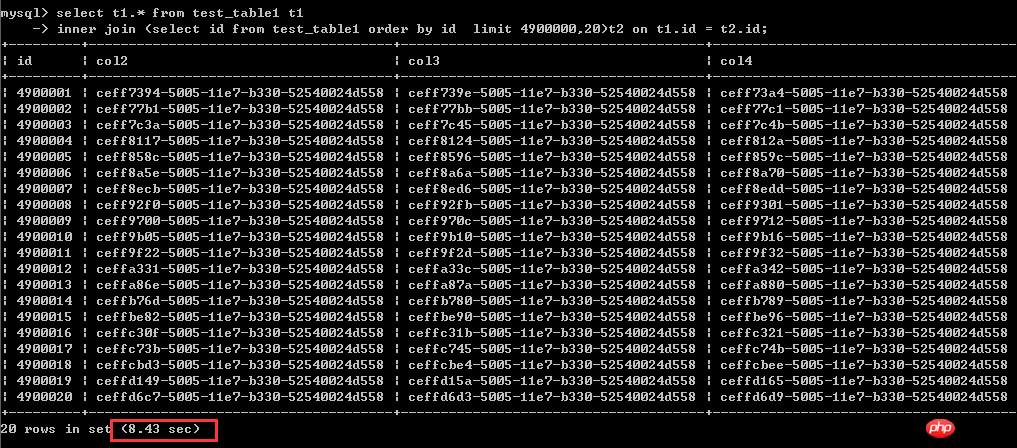
Il est très clair ici qu'après la réécriture via la méthode de réécriture classique, les performances ne se sont pas améliorées du tout, et même ralenti un peu,
Le test réel montre qu'il n'y a pas de différence linéaire évidente de performances entre les deux. L'affiche originale des deux a fait plusieurs tests.
Personnellement, quand je vois des conclusions similaires, je dois les tester. On ne peut pas se fier à cette chose, ou à la chance. Pourquoi l'efficacité peut-elle être améliorée, et pourquoi ne peut-elle pas être améliorée ?
Alors pourquoi la méthode réécrite n'a-t-elle pas amélioré les performances comme légendairement ?
Quelle est la raison pour laquelle cette réécriture actuelle n'atteint pas l'objectif d'amélioration des performances ?
Comment cette dernière améliore-t-elle les performances ?
Tout d'abord, jetez un œil à la structure de la table de test. Il y a un index sur la colonne de tri. Ce n'est pas un problème. La clé est que l'index sur la colonne de tri est la clé primaire (clustérisée). indice).
Pourquoi est-ce que lorsque la colonne de tri est un index clusterisé, le SQL réécrit relativement « optimisé » ne peut pas atteindre l'objectif d'« optimisation » ?
Lors du tri Lorsque la colonne est une colonne d'index clusterisé, les deux analysent la table séquentiellement pour interroger les données qualifiées
Bien que cette dernière pilote d'abord une sous-requête, puis utilise les résultats de la sous-requête pour piloter la table principale,
Mais le la sous-requête ne change pas la méthode de "analyse séquentielle de la table pour interroger les données qualifiées". Dans les circonstances actuelles, même la méthode réécrite semble superflue
Reportez-vous aux deux plans d'exécution suivants, la première capture d'écran Une ligne du le plan d'exécution est fondamentalement le même que la troisième ligne du plan d'exécution SQL réécrit (la ligne avec l'identifiant =2).


Requête de pagination lorsqu'il n'y a pas de condition de filtre et que la colonne de tri est un index clusterisé, la soi-disant optimisation des requêtes de pagination est tout simplement superflue
À l'heure actuelle, les deux méthodes d'interrogation des données ci-dessus sont très lentes. Alors, que devez-vous faire si vous souhaitez interroger les données ci-dessus ?
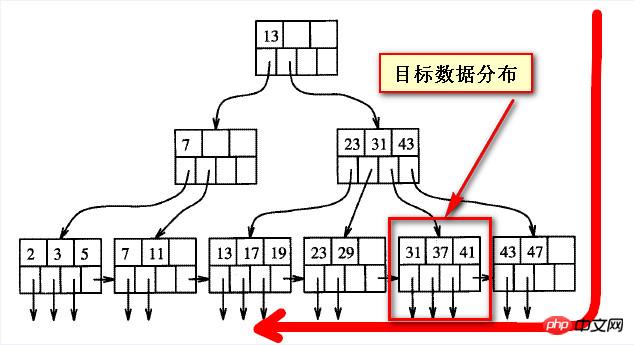
Nous devons encore voir pourquoi il est lent. Nous devons d'abord comprendre la structure du solde du numéro B, d'après ma propre compréhension approximative, comme le montre la figure ci-dessous,
Lorsque les données de la requête sont "en retard", il s'écarte en fait de la direction One de l'index B-tree, les données cibles affichées dans les deux captures d'écran suivantes
En fait, il n'y a pas de soi-disant "avant" et "arrière" pour les données sur l'arbre équilibré, "avant" et "arrière" sont tous deux relatifs à l'autre partie, ou dans la direction de numérisation
En regardant les données "arrière" dans une direction, ce sont les données "avant" dans une direction, et l'avant et le retour n’est pas absolu.
Les deux captures d'écran suivantes sont des représentations approximatives de la structure de l'index B-tree Si la position des données cibles est fixe, ce qu'on appelle "l'arrière" est relatif à celle de gauche. à droite. C'est vrai ;
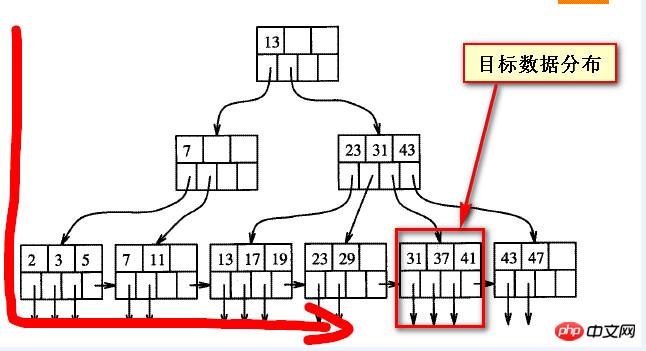
Si vous regardez de droite à gauche, les soi-disant données à l'arrière sont en fait "en avant".
Tant que les données sont au premier plan, il est toujours possible de retrouver efficacement cette partie des données. Mysql devrait également avoir des méthodes similaires aux analyses transférées et inversées dans sqlserver.
Si vous utilisez l'analyse inversée pour les données ultérieures, vous devriez pouvoir trouver cette partie des données rapidement, puis trier à nouveau les données trouvées (asc). Le résultat devrait être le même,
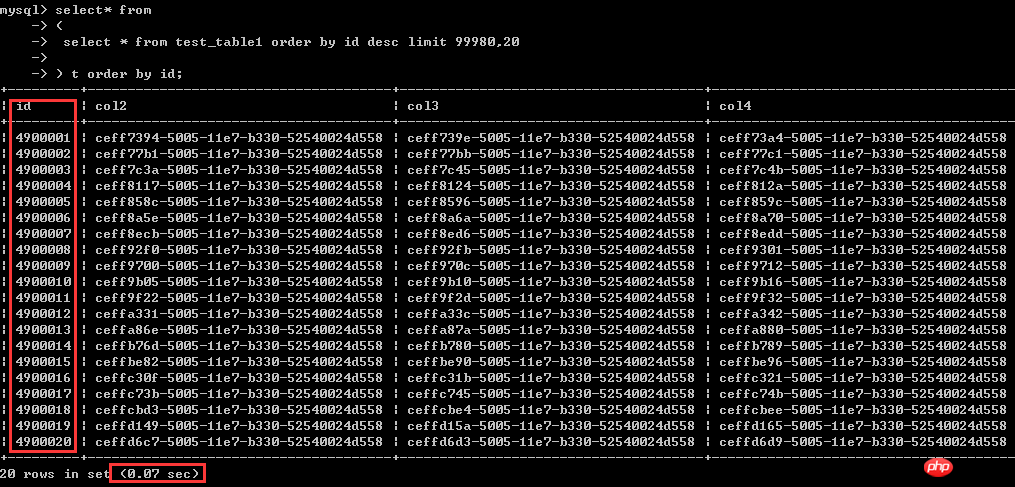
Regardons d'abord l'effet : le résultat est exactement le même que la requête ci-dessus Cela ne prend que 0,07 seconde Les deux méthodes d'écriture précédentes prenaient toutes deux plus de 8 secondes et l'efficacité est de plusieurs centaines. de moments différents.
Quant à savoir pourquoi, je pense que sur la base de l'explication ci-dessus, je devrais être capable de le comprendre. Voici le SQL.
Si vous interrogez souvent les données dites ultérieures, telles que les données avec des identifiants plus grands ou les données plus récentes dans la dimension temporelle, vous pouvez utiliser l'index d'analyse arrière pour obtenir des requêtes de pagination efficaces
(Veuillez calculer la page où se trouvent les données ici. Pour les mêmes données, le "numéro de page" de départ est différent dans l'ordre avant et arrière)
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
Lorsqu'il n'y a pas de condition de filtrage et que la colonne de tri est un index non clusterisé, elle sera améliorée
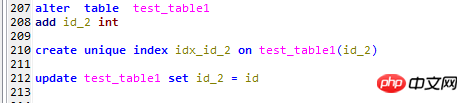
Voici les modifications suivantes apportées à la table de test test_table1
1, ajoutez une colonne id_2,
2, créez un index unique sur ce champ,
3, remplissez ce champ avec l'identifiant de clé primaire correspondant
Le test ci-dessus a été trié en fonction de l'index de clé primaire (index clusterisé). Trions maintenant en fonction de l'index non clusterisé, c'est-à-dire la colonne id_2 nouvellement ajoutée, et testons les deux méthodes de pagination mentionnées à l'adresse suivante. le début.
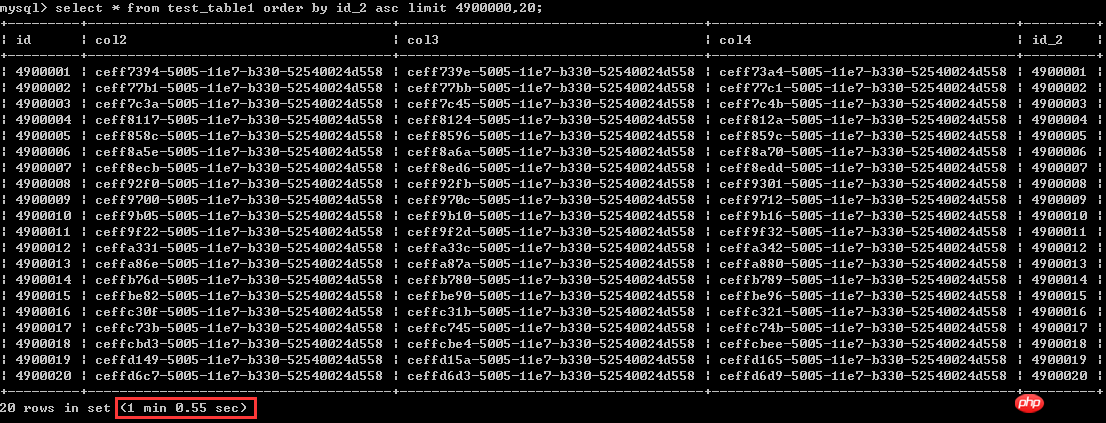
Regardons d'abord la première façon d'écrire
Sélectionnez * dans la commande test_table1 par id_2 asc limit 4900000,20 ; le temps d'exécution est d'un peu plus d'une minute, considérons cela dure 60 secondes
La deuxième façon d'écrire
sélectionnez t1.* dans test_table1 t1
jointure interne (sélectionnez l'identifiant dans test_table1 commander par id_2 limite 4900000, 20)t2 sur t1.id = t2.id;Temps d'exécution 1,67 secondes
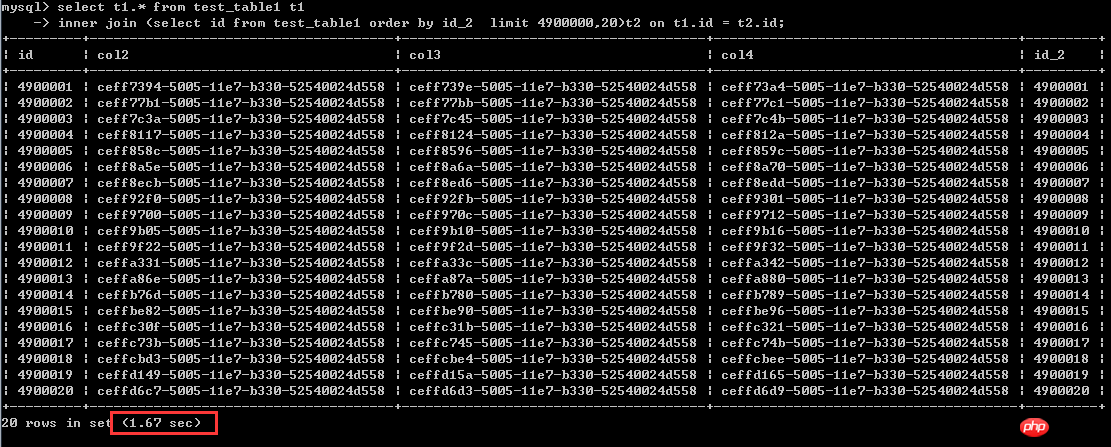
De cette situation, c'est à Par exemple, la colonne de tri est Lorsque vous utilisez des colonnes d'index non clusterisées, cette dernière méthode d'écriture peut en effet grandement améliorer l'efficacité. C'est presque une amélioration de 40 fois.
Alors quelle est la raison ?
Regardons d'abord le plan d'exécution de la première façon d'écrire. On peut simplement comprendre que la table entière est analysée lors de l'exécution de ce sql, puis triée à nouveau selon id_2, et enfin les 20 premières données. sont prises.
Tout d'abord, l'analyse complète d'une table est un processus très long, et le tri est également un coût très élevé, les performances sont donc très faibles.

Regardons le plan d'exécution de ce dernier. Il analyse d'abord la sous-requête selon l'ordre d'index sur id_2, puis utilise la clé primaire qualifiée Id pour interroger. la table. Data
De cette façon, vous pouvez éviter d'interroger une grande quantité de données puis de les réorganiser (en utilisant le tri de fichiers)
Si vous comprenez le plan d'exécution de sqlserver, par rapport au premier, ce dernier devrait éviter les tables fréquentes. renvoie ( Le processus appelé recherche de clé ou recherche de signets dans sqlserver
peut être considéré comme un processus par lots et unique d'interrogation de 20 données qualificatives dans la table externe pilotée par une sous-requête.
En fait, seulement dans les circonstances actuelles, c'est-à-dire lorsque la colonne de tri est une colonne d'index non clusterisée, le SQL réécrit peut améliorer l'efficacité des requêtes de pagination  Même ainsi, cette méthode a été "optimisée". assez différente de l'efficacité de la pagination écrite comme suit
Même ainsi, cette méthode a été "optimisée". assez différente de l'efficacité de la pagination écrite comme suit
<.>
Une autre question que je souhaite mentionner est que si les requêtes de pagination sont fréquentes et dans un certain ordre, alors pourquoi ne pas créer un index clusterisé sur cette colonne.
Par exemple, si l'instruction incrémente automatiquement l'ID, ou si l'heure + les autres champs garantissent l'unicité, mysql créera automatiquement un index clusterisé sur la clé primaire.
Ensuite, avec l'index clusterisé, "avant" et "arrière" ne sont que des concepts logiques relatifs. Si vous souhaitez récupérer des données "en arrière" ou plus récentes la plupart du temps, vous pouvez utiliser la méthode d'écriture ci-dessus,
Optimisation des requêtes de pagination lorsqu'il y a des conditions de filtrage
Après réflexion sur cette partie, la situation est trop compliquée et il est difficile de résumer Un cas très représentatif est sorti, donc je ne ferai pas trop de tests. select * from t Where *** order by id limit m,n
1. Par exemple, la condition de sélection du pinceau elle-même est très efficace une fois filtrée, seule une petite partie des données est laissée. , donc la signification du SQL n'a pas d'importance qu'il soit modifié ou non. Pas grand-chose, car les conditions de filtrage elles-mêmes peuvent obtenir un filtrage très efficace
2. Par exemple, les conditions de sélection du pinceau elles-mêmes ont peu d'effet (la quantité de les données sont toujours énormes après le filtrage). Cette situation revient en fait à la situation où il n'y a pas de conditions de filtrage, et cela dépend aussi de la façon de trier, de l'ordre avant ou arrière, etc.
3. Par exemple, les conditions de filtrage. eux-mêmes ont peu d'effet (la quantité de données est toujours énorme après le filtrage). Une question très pratique à considérer est la distribution des données,
La distribution des données affectera également l'efficacité d'exécution de SQL (l'expérience de sqlserver, mysql ne devrait pas l'être). très différent)
4. Lorsque la requête elle-même est relativement complexe, il est difficile de dire qu'une certaine méthode peut atteindre des objectifs efficaces
Ici, nous n'analyserons pas la situation de l'ajout de conditions de filtrage à la requête une par une, mais ce qui est sûr c'est que sans le scénario réel, il n'y a définitivement pas de solution solide.
Résumé
Requête de page, plus on est loin, plus la situation est lente. En fait, pour l'index B-tree, l'avant et l'arrière. sont Un concept logiquement relatif, la différence de performances est basée sur la structure de l'index B-tree et la méthode d'analyse.Si des conditions de filtrage sont ajoutées, la situation deviendra plus compliquée. Le principe de ce problème est le même dans SQL Server. Oui, il a été initialement testé dans SQL Server, je ne le répéterai donc pas ici.
Dans la situation actuelle, la colonne de tri, les conditions de requête et la distribution des données ne sont pas nécessairement certaines, il est donc difficile d'utiliser une méthode spécifique pour réaliser une « optimisation ». Sinon, cela aura des effets secondaires superflus.
Par conséquent, lors de l'optimisation de la pagination, vous devez effectuer une analyse basée sur des scénarios spécifiques. Il n'y a pas nécessairement une seule méthode. Toute conclusion séparée du scénario réel est absurde.
Ce n'est qu'en comprenant les tenants et les aboutissants de ce problème que nous pourrons le résoudre facilement.
Par conséquent, ma conclusion personnelle sur « l'optimisation » des données doit être basée sur une analyse spécifique de problèmes spécifiques. Il est très tabou de résumer un ensemble de règles (règles 1, 2, 3, 4, 5) que d'autres peuvent « appliquer ». ". Puisque je suis aussi très Food, encore moins résumer certains dogmes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!