
Maison >développement back-end >Tutoriel Python >Exemples de traitement Python de données texte désordonnées
Exemples de traitement Python de données texte désordonnées

- PHP中文网original
- 2017-06-20 16:34:565581parcourir
1. Environnement d'exploitation
1. Python version 2.7.13. Tous les codes de blog sont cette version
2. Environnement système : système win7 64 bits
2. texte désordonné Traitement des données
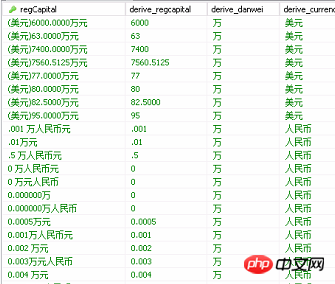
Certaines captures d'écran des données sont les suivantes. Le premier champ est le champ d'origine, et les trois suivants sont les champs nettoyés. En observant les champs agrégés dans la base de données, à première vue, les données sont relativement. régulier, similaire à (montant en devise Dix mille yuans) De cette façon, j'ai pensé à utiliser SQL pour écrire des jugements conditionnels et les convertir uniformément en l'unité de « dix mille yuans ». Je pourrais utiliser un script SQL pour intercepter la chaîne. , j'ai découvert plus tard que les données étaient irrégulières et qu'il y avait trop de jugements conditionnels et que la qualité du nettoyage n'était pas bonne. Bien sûr, certains n'ont pas de crochets gauches devant eux, certains champs n'ont pas de valeur, certains chiffres le sont. pas des entiers, et certains n'ont pas 10 000 caractères. De cette façon, si les deux champs sont stockés sous forme de nombres et d'unité « 10 000 yuans », il sera compliqué d'écrire le script SQL. Je n'ai pas trouvé de fonction dans MySQL. peut extraire des nombres à partir du texte. Les expressions régulières sont souvent utilisées dans les conditions Where. Si quelqu'un sait que MySQL a une fonction similaire au filtrage du texte pour extraire les nombres du texte, pouvez-vous me le dire, afin que vous n'ayez pas à dépenser autant d'argent. .Pour beaucoup d'efforts, utilisez simplement Kettle comme un outil. Il est préférable d'apprendre et d'utiliser l'outil de manière flexible.
Combiné à l'expérience de l'utilisation de Python, Python possède de nombreuses fonctions pour le filtrage de chaînes. Cette méthode est utilisée dans le code ultérieur pour filtrer le texte.
3. Réfléchir à la logique macro du traitement des données
Après avoir obtenu les données, ne vous précipitez pas pour écrire du code, pensez d'abord à la logique du nettoyage. Dans la bonne direction, vous obtiendrez deux fois le résultat avec la moitié de l'effort. Le reste du temps est du code Le processus d'implémentation de la logique et du code de débogage.
3.1 Processus de réflexion sans écrire de code :
Le nettoyage final des données que je souhaite réaliser est de convertir le champ du fonds en une combinaison de [montant + unité + chaque devise] ou [montant + unité ] + Monnaie RMB unifiée] (conversion du taux de change), cela peut se faire en deux ou trois étapes
3.1.1 Divisé en trois champs, nombre, unité, devise
(Les unités sont divisé en dizaines de milliers et à l'exclusion des dix mille, et les devises sont divisées en RMB et devises étrangères spécifiques)
3.1.2 Convertir les unités en unités de dizaines de milliers
L'unité dans le premier l'étape n'est pas La partie numérique de dix mille/10000, la partie numérique de dix mille reste inchangée
3.1.3 Unifier la monnaie en RMB
La monnaie est le RMB, les deux premiers champs restent inchangé, non La partie numérique est remplacée par un nombre * le taux de change de chaque devise étrangère en RMB, l'unité reste inchangée et est toujours le « dix mille » unifié dans la deuxième étape
3.2 Énumération des données du effet de nettoyage attendu de chaque étape :
À partir de là, nous avons commencé à le démonter étape par étape, en triant d'abord la partie logique de nettoyage
3.2.1 L'effet attendu de la première le nettoyage a été divisé en trois champs, unité monétaire numérique :
① valeur du champ = " 2000 yuans", le premier nettoyage 2000 不含万 人民币
② valeur du champ = " 20 millions de yuans ", le premier nettoyage 2000 万 人民币
③ valeur du champ = "20 millions de yuans" Devise étrangère", le premier nettoyage 2000 万 外币
3.2.2 L'effet attendu du deuxième nettoyage sera unifié en dix mille :
#二次处理条件case when 单位=‘万’ then 金额 else 金额/10000 end as 第二次金额
①Valeur du champ = "2000 Yuan RMB"0.2 万 人民币
②Valeur du champ = "20 millions de RMB"2000 万 人民币
③Valeur du champ = « 20 millions de devises étrangères »2000 万 外币
Remarque : si les conditions ci-dessus sont remplies, le nettoyage est terminé. Si vous souhaitez convertir l'unité en RMB, effectuez les trois nettoyages suivants
3.2.3 L'effet attendu du troisième nettoyage : la monnaie unitaire est unifiée à 10 000 + RMB Si l'exigence finale est de convertir la monnaie en RMB unifié, alors nous pouvons simplement écrire les conditions sur la base du deuxième nettoyage,#三次处理条件case when 币种=‘人民币’ then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额①Valeur du champ = "2000 yuans RMB"
0.2 万 人民币②Valeur du champ = "20 millions de RMB"2000 万 人民币③Field valeur = « 20 millions de devises étrangères »2000*外币兑换人民币汇率 万 人民币
La première chose que je sais de ce code, c'est qu'il peut extraire les nombres du texte. En regroupant les champs et en les agrégeant, je connais les champs avec des points décimaux. n'ont plus de points décimaux, tels que « 200 100 ». filter(str.isdigit,字段的值)Le nombre retiré est 2001. Évidemment, ce nombre est incorrect, vous devez donc vous demander s'il y a un point décimal. S'il y a un point décimal, ce devrait être le. identique au champ d'originefilter(str.isdigit,‘20.01万’)
#带小数点的以小数点分割 取出小数点前后部分进行拼接if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)#单位 以万和不含万 为统一if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万' #币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币' 5. Code complet : lire les données de la base de données pour une mesure complète NettoyageLa quatrième étape consiste à tester certaines données pour vérifier que le code est correct. le temps, la logique doit être étendue d'un point de vue macro et la variable d'information doit être modifiée dynamiquement dans toutes les valeurs de la base de données pour effectuer un nettoyage complet #coding:utf-8from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_datafor data in data_tuple:
item={}#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])if data[-2]:if len(data[-2]) >0 :
info=data[-2].encode('utf-8')else:
info=''if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万'if '美元' in info:
derive_currency='美元'elif '港币' in info:
derive_currency = '港币'elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'elif '澳元' in info:
derive_currency = '澳元'elif '英镑' in info:
derive_currency = '英镑'elif '加拿大元' in info:
derive_currency = '加拿大元'elif '日元' in info:
derive_currency = '日元'elif '港币' in info:
derive_currency = '港币'elif '法郎' in info:
derive_currency = '法郎'elif '欧元' in info:
derive_currency = '欧元'elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)#print len(old_data)for i in range(len(old_data)):if not old_data[i] :
old_data[i]=''else:pass
data2=old_data[i].replace('"','')
item[i+1]=data2print item[1] #插入测试环境 的表
project2.insert(item=item,db='local_db') 6. Opération de code <.>6.1 Lire les données de la table originale de la base de données et les champs créés dans la nouvelle table
 Lire les données de la table originale de la base de données et les champs créés dans la nouvelle table
Lire les données de la table originale de la base de données et les champs créés dans la nouvelle table 6.2 Insérez le nouveau tableau et effectuez le premier nettoyage des données
La partie boîte rouge est la partie nettoyage, et les autres données ont été désensibilisées
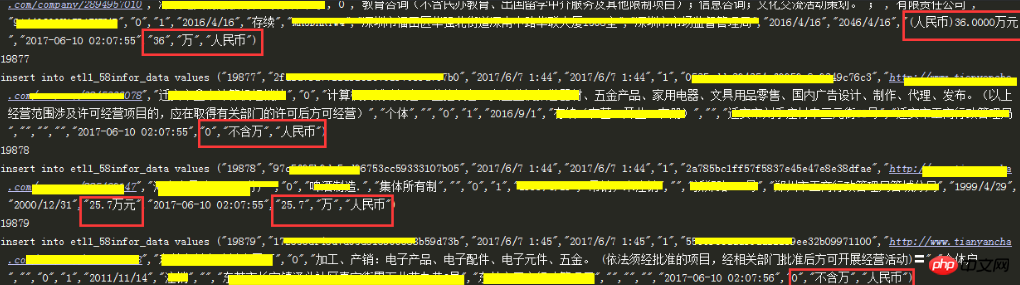 Insérez une nouvelle table et effectuez le premier nettoyage des données
Insérez une nouvelle table et effectuez le premier nettoyage des données 6.3 数据表数据清洗结果
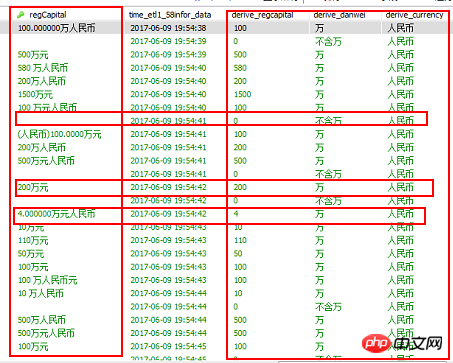
七、增量数据处理
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestodayCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!