
Maison >développement back-end >Tutoriel Python >Tutoriel Scrapy – explorer les N premiers articles d'un site Web
Tutoriel Scrapy – explorer les N premiers articles d'un site Web
- 巴扎黑original
- 2017-06-23 15:47:141734parcourir
1. Page de liste des 3000 meilleurs personnels
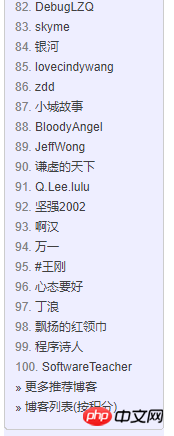

2) Analysez la structure de la page : Chaque TD est une personne.
Le premier petit est le classement
Le second une balise est le pseudo et le nom d'utilisateur, ainsi que l'adresse du blog de la page d'accueil. Le nom d'utilisateur est obtenu en interceptant l'adresse
La quatrième petite balise est le nombre de blogs et de points, qui peuvent être obtenus un par un après séparation des chaînes.
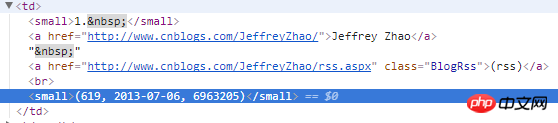
3) Code : utilisez XPath pour obtenir les balises et le contenu associé. Après avoir obtenu l'adresse du blog de la page d'accueil, envoyez une demande.
def parse(self, réponse):
for i in réponse.xpath("//table[@width='90%']//td"):
item = CnblogsItem()
item['top'] = i. 2].strip()
'nomutilisateur'] = i.xpath(
"./a[1]/@href") .extract()[0].split('/')[-2].strip()
"./a[1]/@href") totalAndScore = i.xpath(
"./small [2]//text()").extract()[0].lstrip('(').rstrip(')').split(',')
item['score'] = totalAndScore[ 2].strip()
# print(top)
# print(total) return ' : 1, 'item' : item},
callback=self.parse_page)
二、各人员博客列表页
1)页面结构:通过分析,每篇博客的a标签id中都包含“TitleUrl”,这样就可以获取到每篇博客的地址了。每页面地址,加上default.html?page=2,page跟着变动就可以了。

2)代码:置顶的文字会去除掉。
def parse_page(self, response):
# print(response.meta['nickName'])
#//a[contains(@id,'TitleUrl')]
urlArr = response.url.split('default.aspx?')
if len(urlArr) > 1:
baseUrl = urlArr[-2]
else:
baseUrl = response.url
list = response.xpath("//a[contains(@id,'TitleUrl')]")
for i in list:
item = CnblogsItem()
item['top'] = int(response.meta['item']['top'])
item['nickName'] = response.meta['item']['nickName']
item['userName'] = response.meta['item']['userName']
item['score'] = int(response.meta['item']['score'])
item['pageLink'] = response.url
item['title'] = i.xpath(
"./text()").extract()[0].replace(u'[置顶]', '').replace('[Top]', '').strip()
item['articleLink'] = i.xpath("./@href").extract()[0]
yield scrapy.Request(i.xpath("./@href").extract()[0], meta={'item': item}, callback=self.parse_content)
if len(list) > 0:
response.meta['page'] += 1
yield scrapy.Request(baseUrl + 'default.aspx?page=' + str(response.meta['page']), meta={'page': response.meta['page'], 'item': response.meta['item']}, callback=self.parse_page)
3)对于每篇博客的内容,这里没有抓取。也很简单,分析页面。继续发送请求,找到id为cnblogs_post_body的div就可以了。
def parse_content(self, response):
content = response.xpath("//div[@id='cnblogs_post_body']").extract()
item = response.meta['item']if len(content) == 0:
item['content'] = u'该文章已加密'else:
item['content'] = content[0]yield item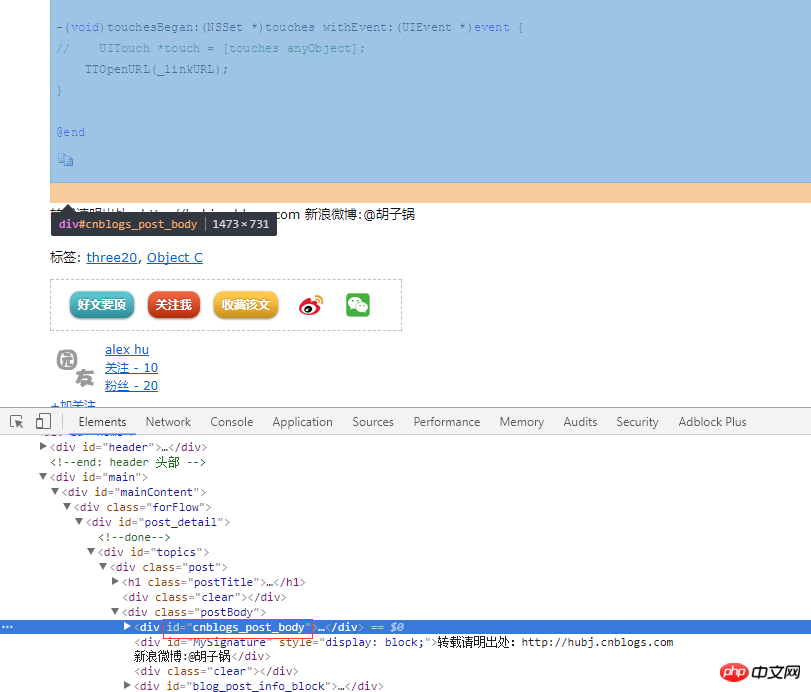
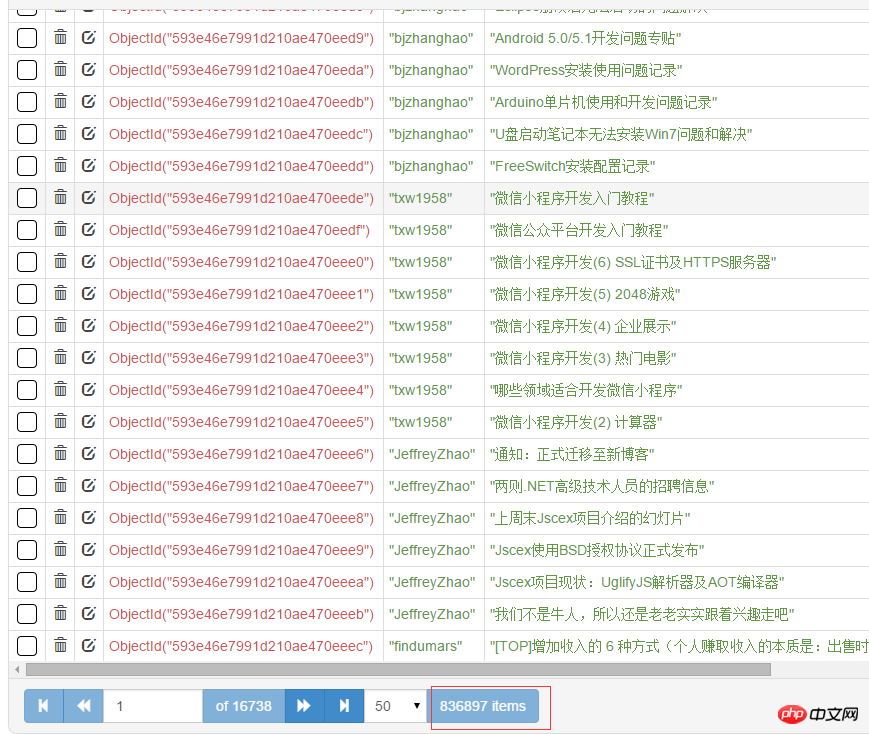
三、数据存储MongoDB
这一部分没什么难的。记着安装pymongo,pip install pymongo。总共有80+万篇文章。
from cnblogs.items import CnblogsItemimport pymongoclass CnblogsPipeline(object):def __init__(self): client = pymongo.MongoClient(host='127.0.0.1', port=27017) dbName = client['cnblogs'] self.table = dbName['articles'] self.table.createdef process_item(self, item, spider):if isinstance(item, CnblogsItem): self.table.insert(dict(item))return item
四、代理及Model类
scrapy中的代理,很简单,自定义一个下载中间件,指定一下代理ip和端口就可以了。
def process_request(self, request, spider): request.meta['proxy'] = 'http://117.143.109.173:80'
Model类,存放的是对应的字段。
class CnblogsItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 排名top = scrapy.Field() nickName = scrapy.Field() userName = scrapy.Field()# 积分score = scrapy.Field()# 所在页码地址pageLink = scrapy.Field()# 文章标题title = scrapy.Field()# 文章链接articleLink = scrapy.Field()
# 文章内容
content = scrapy.Field()
五、wordcloud词云分析
对每个人的文章进行词云分析,存储为图片。wordcloud的使用用,可参考园内文章。
这里用了多线程,一个线程用来生成分词好的txt文本,一个线程用来生成词云图片。生成词云大概,1秒一个。

# coding=utf-8import sysimport jiebafrom wordcloud import WordCloudimport pymongoimport threadingfrom Queue import Queueimport datetimeimport os
reload(sys)
sys.setdefaultencoding('utf-8')class MyThread(threading.Thread):def __init__(self, func, args):
threading.Thread.__init__(self)
self.func = func
self.args = argsdef run(self):
apply(self.func, self.args)# 获取内容 线程def getTitle(queue, table):for j in range(1, 3001):# start = datetime.datetime.now()list = table.find({'top': j}, {'title': 1, 'top': 1, 'nickName': 1})if list.count() == 0:continuetxt = ''for i in list:
txt += str(i['title']) + '\n'name = i['nickName']
top = i['top']
txt = ' '.join(jieba.cut(txt))
queue.put((txt, name, top), 1)# print((datetime.datetime.now() - start).seconds)def getImg(queue, word):for i in range(1, 3001):# start = datetime.datetime.now()get = queue.get(1)
word.generate(get[0])
name = get[1].replace('<', '').replace('>', '').replace('/', '').replace('\\', '').replace('|', '').replace(':', '').replace('"', '').replace('*', '').replace('?', '')
word.to_file('wordcloudimgs/' + str(get[2]) + '-' + str(name).decode('utf-8') + '.jpg')print(str(get[1]).decode('utf-8') + '\t生成成功')# print((datetime.datetime.now() - start).seconds)def main():
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
dbName = client['cnblogs']
table = dbName['articles']
wc = WordCloud(
font_path='msyh.ttc', background_color='#ccc', width=600, height=600)if not os.path.exists('wordcloudimgs'):
os.mkdir('wordcloudimgs')
threads = []
queue = Queue()
titleThread = MyThread(getTitle, (queue, table))
imgThread = MyThread(getImg, (queue, wc))
threads.append(imgThread)
threads.append(titleThread)for t in threads:
t.start()for t in threads:
t.join()if __name__ == "__main__":
main()六、完整源码地址
附:mongodb内存限制windows:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!