
Maison >développement back-end >Tutoriel Python >Crawler Python : protocole HTTP, bibliothèque de requêtes
Crawler Python : protocole HTTP, bibliothèque de requêtes
- 巴扎黑original
- 2017-06-23 16:25:041525parcourir
Protocole HTTP :
HTTP (Hypertext Transfer Protocol) : Protocole de transfert hypertexte. L'URL est le chemin Internet permettant d'accéder aux ressources via le protocole HTTP. Une URL correspond à une ressource de données.
Fonctionnement des ressources par protocole HTTP :

La bibliothèque Requests fournit toutes les méthodes de requêtes de base de HTTP . Introduction officielle :
Les 6 méthodes principales de la bibliothèque Requests :

Exceptions dans la bibliothèque Requêtes :

Deux objets importants dans la bibliothèque Requêtes : Request (requête) et Response (réponse). L'objet Request prend en charge plusieurs méthodes de requête ; l'objet Response contient toutes les informations renvoyées par le serveur, ainsi que les informations de requête demandées.
Attributs de l'objet Response :

Parmi eux, r.encoding signifie : si c'est le cas n'existe pas dans le jeu de caractères d'en-tête, le codage est considéré comme étant ISO-8859-1.
r.raise_for_status() peut savoir directement si r.status_code est égal à 200.
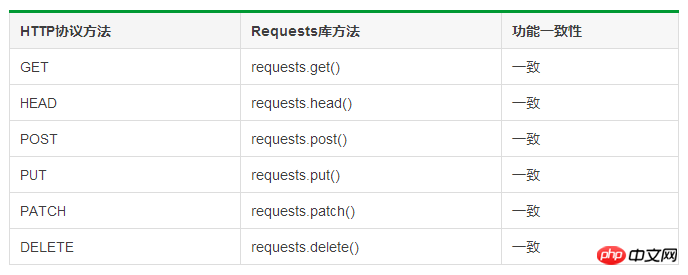
Comparaison du protocole HTTP et de la bibliothèque de requêtes :
Exploration des pages Web Framework de code commun :
1 try:2 r = requests.get(url,timeout = 30)3 r.raise_for_status()4 # 如果状态不是200,引发HTTPError异常5 r.encoding = r.apparent_encoding6 return r.text7 except:8 return '产生异常'
Par exemple, obtenez les informations sur la page d'accueil de PMCAFF :
1 import requests 2 3 def getHtmlText(url): 4 try: 5 r = requests.get(url,timeout = 30) 6 r.raise_for_status() 7 r.encoding = r.apparent_encoding 8 return r.text 9 except:10 return '产生异常'11 12 if __name__ == '__main__':13 url = ''14 print(getHtmlText(url))
Cadre de code général pour l'exploration de pages Web : environnement d'exploitation : Mac, Python 3.6, PyCharm 2016.2
Référence : cours MOOC de l'université chinoise "Python Web Crawler and Information Extraction"
----- Fin -----
Auteur : Du Wangdan, compte public WeChat : Du Wangdan, produit Internet directeur.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!