
Maison >développement back-end >Tutoriel XML/RSS >Qu'est-ce que XML ? Exemple d'explication de XML
Qu'est-ce que XML ? Exemple d'explication de XML

- PHP中文网original
- 2017-06-20 16:54:574742parcourir
Structure du répertoire :
1 Qu'est-ce que XML
XML (eXtensible markup Language) est un langage de balisage extensible. Des étiquettes peuvent être personnalisées.
2 Analyse XML
2.1 Deux façons d'analyser
L'analyse XML est divisée en deux manières, à savoir SAX et DOM.
DOM : (Document Object Model) est un moyen de traitement XML recommandé par l'organisation W3C. L'utilisation de cette méthode pour analyser des documents XML construira une structure arborescente en mémoire selon la relation hiérarchique entre tous les éléments du document. Par conséquent, il exerce beaucoup de pression sur la mémoire et est lent à analyser et à lire. L'avantage est qu'il peut parcourir et modifier le contenu des nœuds.
SAX : (Simple API for XML) est une alternative à l'analyse XML. Par rapport au DOM, la vitesse d'analyse est plus rapide et la pression sur la mémoire est moindre ; l'inconvénient est que le contenu du nœud ne peut pas être modifié.
2.2 Utilisez dom4j pour analyser XML
Avant d'utiliser dom4j pour analyser XML, vous devez importer des packages d'outils pertinents, tels que celui de l'auteur : dom4j-1.6.1.jar package
2.2.1 API dom4j
//创建SAXReader,是dom4j包提供的解析器SAXReader reader=new SAXReader();//读取指定的文件Document doc=reader.read(new File(filename)); Document Document getRootElement() 用于获取根元素 Element Element element(String name) 获取元素下指定名称的子元素 List<Element> elements() 获取元素下所有的子元素 String getName() 获取元素名 String getText() 获取元素文本内容 String elementText(String name) 获取子元素文本内容 Attribute attribute(String) 获取元素的属性 String attributeValue(String name) 获取元素的属性值 Attribute String getName() 获取属性的名字 String getValue() 获取属性的值
2.2.2 Imprimer l'intégralité du contenu d'un fichier XML
Le fichier pricties.xml est situé directement sous le projet


<?xml version="1.0" encoding="utf-8" ?><books id="a"> <book id="b"><name id="c_1" name="c_2">三国演绎</name><author id="d_1" name="d_2" >罗贯中</author><price id="e">58.8</price> </book> <book id="f_1" name="f_2"><name id="g">水浒传</name><author id="h">施耐庵</author><price id="i">49.8</price> </book> <book id="j_1" name="j_2"><name id="k">西游记</name><author id="l">吴承恩</author><price id="m">100.1</price><order>1</order> </book></books>


import java.io.File;import java.util.List;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class ParseXML {public static void main(String[] args) {//创建SAXReader对象SAXReader saxr=new SAXReader();
Document docu=null;try{//读取指定的文件,相对于项目路径docu=saxr.read(new File("pricties.xml"));//获得元素的文件的根节点Element e=docu.getRootElement();
searchAllElement(e);
}catch(Exception e){
e.printStackTrace();
}
} public static void searchAllElement(Element e){//获得当前元素下的所有子元素,并存储到集合中List<Element> elements=e.elements();
System.out.print("<"+e.getName());//打印开始标记List<Attribute> atrs=e.attributes();//打印该标记下的所有属性for(Attribute att:atrs){
System.out.print(" "+att.getName()+"=\""+att.getValue()+"\"");
}
System.out.println(">"); //如果集合的大小为0,表示该集合下没有子元素了if(elements.size()==0){
System.out.println(e.getText());//打印文本信息System.out.println("</"+e.getName()+">");//打印结束标记return;//退出当前层方法 } //递归每一个子元素for(Element ele:elements){
searchAllElement(ele);
}
System.out.println("</"+e.getName()+">");//打印结束标记 }
}2.3 Application de XPath pour analyser XML dans dom4j
Tout d'abord, vous devez introduire le package jar correspondant basé sur dom4j, comme celui du lecteur : jaxen- 1.1-beta-6.jar
2.3.1 API XPath
Document List<Node> selectNodes(String xpath) Node selectSingleNode(String xpath)
2.3.2 XPath的路径表达式
2.3.2.1 XPath的路径表达式规则
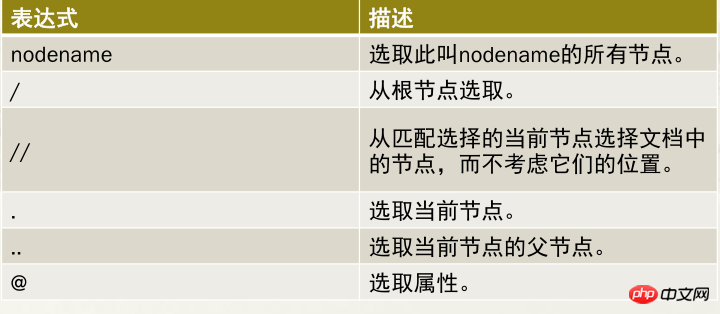
2.3.2.2 XPath的路径表达式应用案例
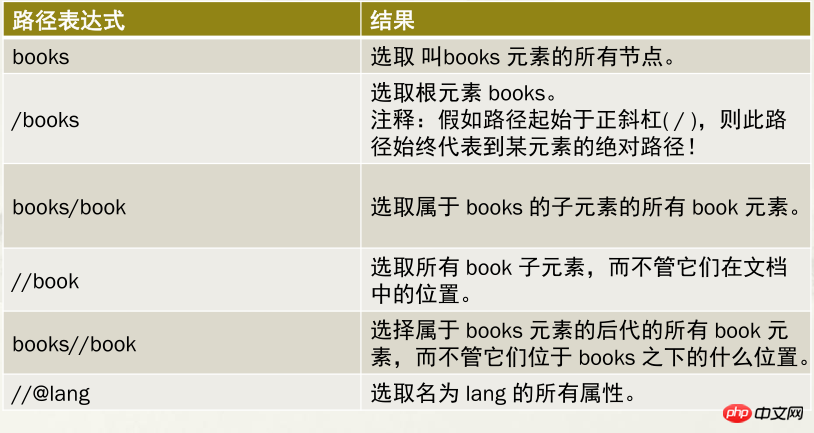
2.3.3 通配符
2.3.3.1 通配符规则

2.3.3.2 通配符应用案例

2.3.4 谓语
2.3.4.1 谓语规则
谓语是用来查找某个特定的节点或是包含某个指定的值的节点
谓语被嵌在方括号中
2.3.4.2 谓语应用案例
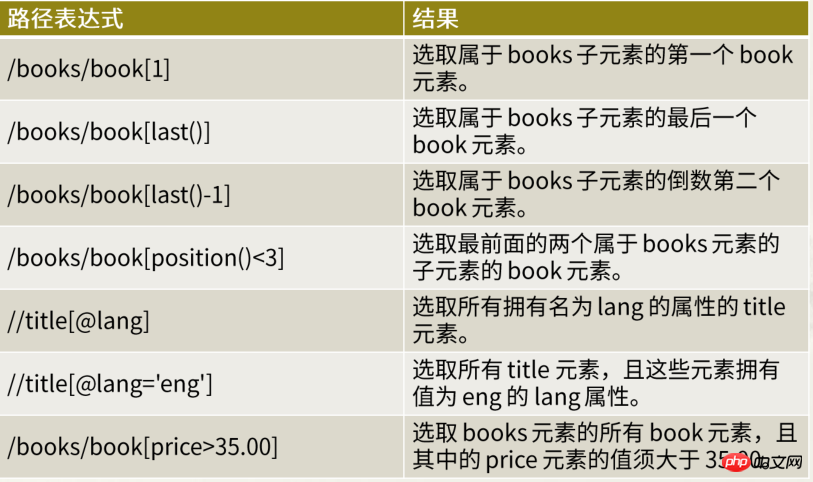
3 java写XML文件
3.1 将一个带有书籍信息的List集合解析为XML文件


package com.xdl.xml;public class Book {private String name;private String author;private String price;public Book() {super();
}public Book(String name, String author, String price) {super();
setName(name);
setAuthor(author);
setPrice(price);
}/** * @return the name */public String getName() {return name;
}/** * @param name the name to set */public void setName(String name) {this.name = name;
}/** * @return the author */public String getAuthor() {return author;
}/** * @param author the author to set */public void setAuthor(String author) {this.author = author;
}/** * @return the price */public String getPrice() {return price;
}/** * @param price the price to set */public void setPrice(String price) {this.price = price;
}
}

package com.xdl.xml;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.ArrayList;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;import org.dom4j.io.XMLWriter;public class WriteXML {public static void main(String[] args) {//创建一个Book集合用于存储书籍信息List<Book> list_books=new ArrayList<Book>();//插入书籍信息for(int i=0;i<6;i++){
Book book=new Book("jame"+i,"author"+i,""+i);
list_books.add(book);
} //创建一个文档对象Document doc=DocumentHelper.createDocument();//创建一个根节点Element books=DocumentHelper.createElement("books"); //获得书籍集合的大小int size=list_books.size();for(int i=0;i<size;i++){//创建一个book节点Element book=books.addElement("book");//创建一个name节点Element name=book.addElement("name");//创建一个author节点Element author=book.addElement("author");//创建一个price节点Element price=book.addElement("price");
name.setText(list_books.get(i).getName());
author.setText(list_books.get(i).getAuthor());
price.setText(list_books.get(i).getPrice());
}//设置文档根节点 doc.setRootElement(books); try {//如果文件不存在,会自动创建FileOutputStream fos = new FileOutputStream(new File("books.xml"));
XMLWriter xmlw = new XMLWriter(fos);
xmlw.write(doc);
xmlw.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}4 Schema和DTD的区别
Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。它们之间的区别有下面几点:
1、Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。
2、DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。
3、DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。
4、Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。
5、对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。
5 参考文章
Schema和DTD的区别
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!