
Maison >développement back-end >Tutoriel Python >Exemple de données audio du robot Python
Exemple de données audio du robot Python

- PHP中文网original
- 2017-06-21 17:16:242300parcourir
1 : Avant-propos
Cette fois, nous avons exploré les informations de chaque chaîne de toutes les stations de radio sous la colonne populaire de l'Himalaya et diverses informations de chaque donnée audio de la chaîne, puis avons mis les données analysées Enregistrer dans mongodb pour une utilisation ultérieure. Cette fois, la quantité de données est d'environ 700 000. Les données audio incluent l'adresse de téléchargement audio, les informations sur la chaîne, l'introduction, etc., il y en a beaucoup.
J'ai eu mon premier entretien hier. L'autre partie était une entreprise de big data d'intelligence artificielle. J'allais faire un stage pendant les vacances d'été de ma deuxième année. Ils m'ont demandé d'explorer des données audio, alors je suis venu. analyser l'Himalaya. Les données audio descendent. Actuellement, j'attends toujours trois interviews, ou d'être informé de la nouvelle finale de l'interview. (Parce que je peux obtenir une certaine reconnaissance, je suis très heureux quel que soit le succès ou l'échec)
2 : Environnement d'exécution
-
IDE : Pycharm 2017
Python3.6
pymongo 3.4.0
requêtes 2.14.2
-
lxml 3.7.2
BeautifulSoup 4.5.3
Trois : exemple d'analyse
1. Entrez d'abord dans la page principale de cette exploration. Vous pouvez voir 12 chaînes sur chaque page. Il y a beaucoup d'audios sous chaque chaîne, et il y a de nombreuses paginations dans certaines chaînes. Plan d'exploration : parcourez 84 pages, analysez chaque page, récupérez le nom de chaque chaîne, le lien de l'image et enregistrez le lien de la chaîne sur mongodb.
2. Ouvrez le mode développeur, analysez la page et obtenez rapidement l'emplacement des données souhaitées. Le code suivant permet de récupérer les informations de toutes les chaînes populaires et de les enregistrer sur mongodb.
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content)
3 Ce qui suit est de commencer à obtenir toutes les données audio de chaque canal, qui ont été obtenues via. la page d'analyse Voici le lien vers la chaîne US. Par exemple, nous analysons la structure de la page après avoir entré ce lien. On peut voir que chaque audio a un identifiant spécifique, qui peut être obtenu à partir des attributs d'un div. Utilisez split() et int() pour convertir en identifiants individuels.
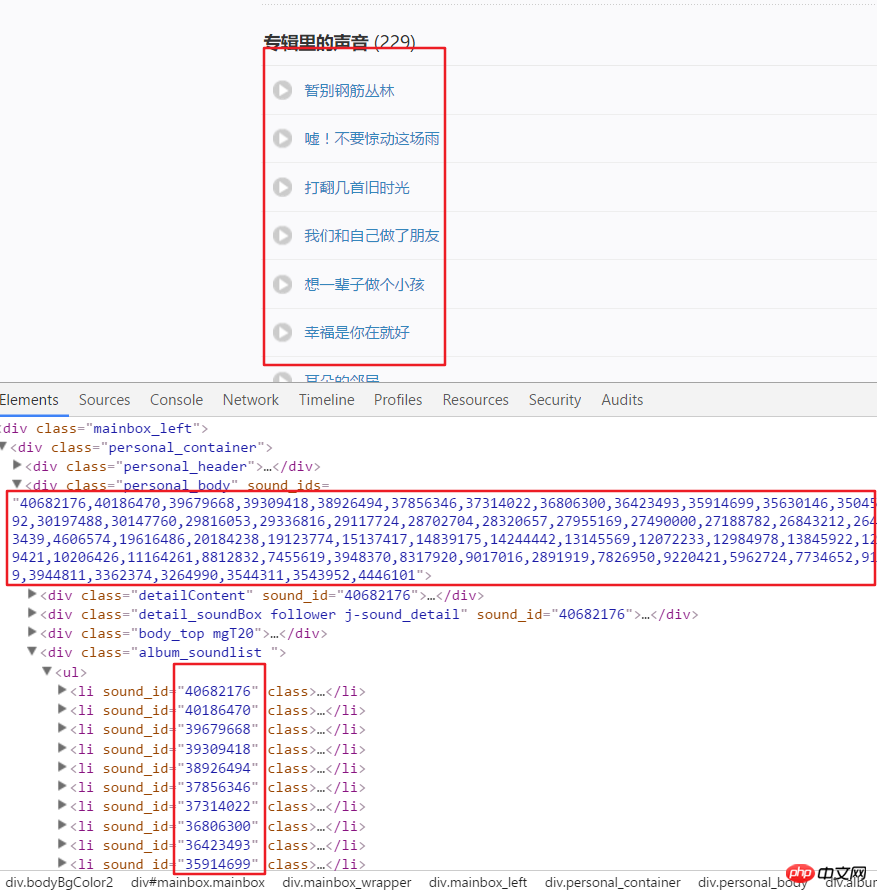
4. Cliquez ensuite sur un lien audio, entrez en mode développeur, actualisez la page et cliquez sur XHR, puis cliquez sur un json. Le lien pour voir cela inclut tous les détails de cet audio.
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
5 Ce qui précède analyse uniquement toutes les informations audio sur la page principale d'une chaîne. , mais en réalité Le lien audio sur la chaîne a de nombreuses paginations.
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明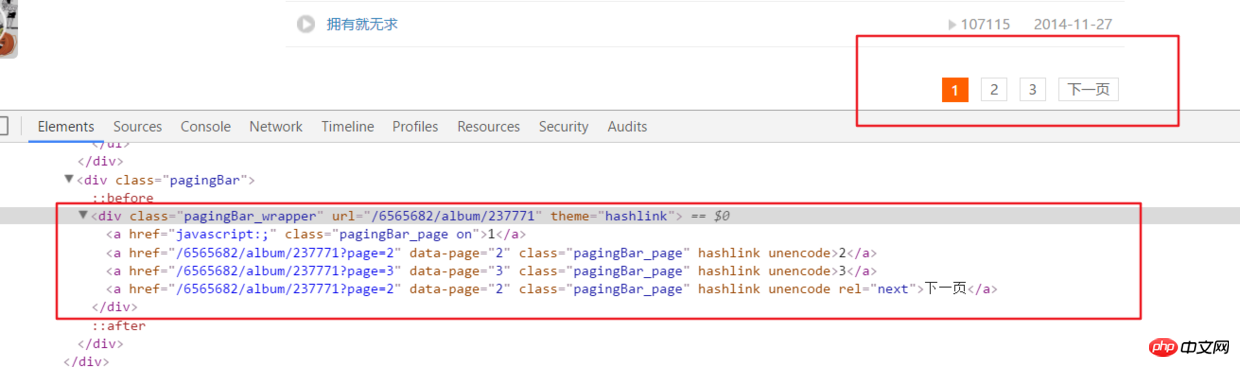
6. Tout le code
Adresse complète du code github.com/rieuse/learnPython
__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
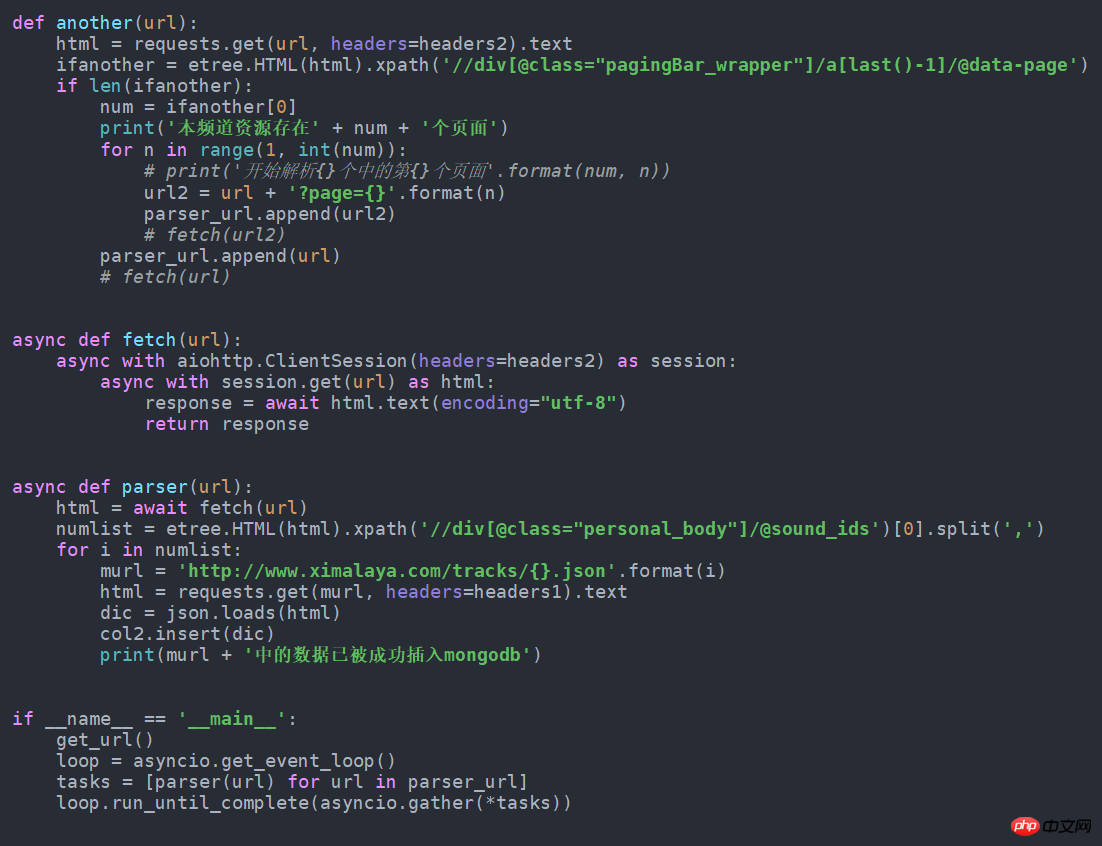
get_url()7. S'il est modifié en forme asynchrone, ce sera plus rapide. Changez-le simplement comme suit. J'ai essayé d'obtenir près de 100 données de plus par minute que la normale. Ce code source est également dans github.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!