
Maison >Java >javaDidacticiel >Qu'est-ce que le cache de requêtes ? Introduction à l'utilisation du cache de requêtes MyBatis
Qu'est-ce que le cache de requêtes ? Introduction à l'utilisation du cache de requêtes MyBatis

- 零下一度original
- 2017-06-25 10:56:072461parcourir
Veuillez indiquer la source de la réimpression :
Comme mentionné précédemment : Spring+SpringMVC+MyBatis apprentissage et construction approfondis (7) - Chargement retardé de MyBatis
1.
mybatis fournit une mise en cache des requêtes pour réduire la pression sur la base de données et améliorer les performances de la base de données.
mybatis fournit un cache de premier niveau et un cache de deuxième niveau.

Le cache de premier niveau est le cache de niveau SqlSession. Lors de l'exploitation de la base de données, vous devez construire un objet sqlSession. Il existe une structure de données (HashMap) dans l'objet pour stocker les données du cache. Les zones de données de cache (HashMap) entre différentes sqlSession ne s'affectent pas.
Le cache de deuxième niveau est un cache au niveau du mappeur. Plusieurs sqlSession exploitent la même instruction SQL du mappeur. Plusieurs sqlSession peuvent partager le cache de deuxième niveau. Le cache de deuxième niveau s'étend sur sqlSession.
Pourquoi utiliser la mise en cache ?
S'il y a des données dans le cache, il n'est pas nécessaire de les obtenir à partir de la base de données, ce qui améliore considérablement les performances du système.
2. Cache de niveau 1
2.1 Principe de fonctionnement du cache de niveau 1
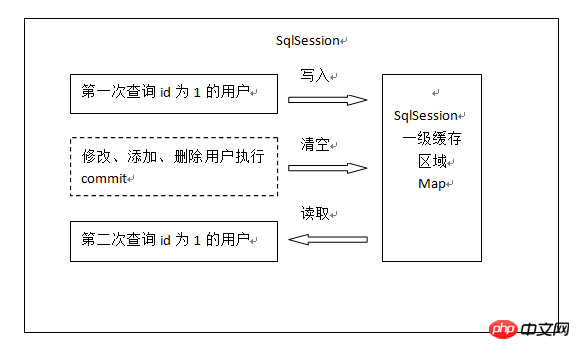
Lancer une requête d'informations utilisateur avec l'ID utilisateur 1 pour le la première fois, découvrez d'abord s'il y a des informations utilisateur avec l'identifiant 1 dans le cache. Sinon, interrogez les informations utilisateur dans la base de données.
Obtenez des informations utilisateur et stockez les informations utilisateur dans le cache de premier niveau.
Si sqlSession effectue une opération de validation (en effectuant une insertion, une mise à jour, une suppression), videz le cache de premier niveau dans sqlSession. Le but est de stocker les dernières informations dans le cache et d'éviter les lectures sales.
La deuxième fois qu'il est envoyé pour interroger les informations utilisateur avec l'ID utilisateur 1, découvrez d'abord s'il y a des informations utilisateur avec l'ID 1 dans le cache. S'il y en a dans le cache, obtenez les informations utilisateur directement depuis. la cache.
2.2 Test du cache niveau 1
Mybatis prend en charge le cache niveau 1 par défaut et n'a pas besoin d'être configuré dans le fichier de configuration.
Suivez les étapes du principe du cache de premier niveau ci-dessus pour tester.
@Testpublic void testCache1() throws Exception{
SqlSession sqlSession=sqlSessionFactory.openSession();
UserMapper userMapper=sqlSession.getMapper(UserMapper.class);//下边查询使用一个SqlSession//第一次发起请求,查询id为1的用户User user1=userMapper.findUserById(1);
System.out.println(user1); //如果sqlSession去执行commit操作(执行插入、更新、删除),清空sqlSession中的一级缓存,//这样做的目的是为了让缓存中存储的是最新的信息,避免脏读。//更新user1的信息user1.setUsername("测试用户22");
userMapper.updateUser(user1);//执行commit操作去清空缓存 sqlSession.commit(); //第二次发起请求,查询id为1的用户User user2=userMapper.findUserById(1);
System.out.println(user2);
sqlSession.close();
}2.3 L'application de cache de niveau 1
est officiellement développée en intégrant mybatis et spring, et le contrôle des transactions est en service.
Une méthode de service comprend de nombreux appels de méthode Mapper.
service{
// Au démarrage de l'exécution, démarrez une transaction et créez un objet SqlSession
// Appelez la méthode mapper findUserById(1) pour la première fois
// Appelez la méthode du mappeur findUserById(1) pour la deuxième fois pour obtenir les données du cache de premier niveau
// La méthode se termine et sqlSession est fermée
>
Si vous exécutez deux appels de service pour interroger les mêmes informations utilisateur, le cache de premier niveau ne sera pas utilisé. Parce que la méthode de session se termine, la sqlSession sera fermée et le cache de premier niveau. le cache sera vidé.
3. Cache de deuxième niveau
3.1 Principe du cache de deuxième niveau

Activez d'abord le cache de deuxième niveau de mybatis.
sqlSession1 interroge les informations utilisateur avec l'ID utilisateur 1. Après avoir interrogé les informations utilisateur, il regrette que les données de la requête soient stockées dans le cache de deuxième niveau.
Si sqlSession3 exécute SQL sous le même mappeur et exécute la soumission de validation, les données dans la zone de cache de deuxième niveau sous le mappeur seront effacées.
sqlSession2 interroge les informations utilisateur avec l'ID utilisateur 1, vérifie si des données existent dans le cache et, si c'est le cas, récupère directement les données du cache.
La différence entre le cache de deuxième niveau et le cache de premier niveau : la portée du cache de deuxième niveau est plus grande et plusieurs sqlSession peuvent partager la zone de cache de deuxième niveau d'un UserMapper. UserMapper possède une zone de cache de deuxième niveau (divisée par espace de noms), et d'autres mappeurs ont également leurs propres zones de cache de deuxième niveau (divisées par espace de noms).
Chaque mappeur d'espace de noms possède une zone de cache de deuxième niveau. Si les espaces de noms de deux mappeurs sont identiques, les données obtenues par les deux mappeurs exécutant des requêtes SQL seront stockées dans la même zone de cache de deuxième niveau.
3.2 Activer le cache de deuxième niveau
Le cache de deuxième niveau de Mybatis est au niveau de la portée du mappeur En plus de définir le commutateur principal du cache de deuxième niveau dans SqlMapConfig.xml, il doit être activé. également être activé dans le cache spécifique mapper.xml niveau 2.
Ajouter le fichier de configuration principal SqlMapConfig.xml :
<setting name="cacheEnabled" value="true"/>
|
Description
|
Valeurs autorisées |
Valeur par défaut |
|||||||||
cacheEnabled |
Définissez les paramètres d'activation/désactivation globaux pour tous les caches sous ce fichier de configuration. |
vrai faux |
true |

在UserMapper.xml中开启二级缓存,UserMapper.xml下的sql执行完成后存储在它的缓存区域(HashMap)。

3.3调用pojo类实现序列化接口

为了将缓存数据取出执行反序列划操作,因为二级缓存数据存储介质多种多样,不一定在内存。可能在硬盘、远程等。
3.4测试方法
@Testpublic void testCache2() throws Exception{
SqlSession sqlSession1=sqlSessionFactory.openSession();
SqlSession sqlSession2=sqlSessionFactory.openSession();
SqlSession sqlSession3=sqlSessionFactory.openSession();
UserMapper userMapper1=sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2=sqlSession2.getMapper(UserMapper.class);
UserMapper userMapper3=sqlSession3.getMapper(UserMapper.class); //第一次发起请求,查询id为1的用户User user1=userMapper1.findUserById(1);
System.out.println(user1);//这里执行关闭操作,将sqlSession中的数据写到二级缓存区域 sqlSession1.close(); //使用sqlSession3执行commit()操作User user=userMapper3.findUserById(1);
user1.setUsername("Joanna");
userMapper3.updateUser(user);//执行提交,清空UserMapper下边的二级缓存 sqlSession3.commit();
sqlSession3.close(); //第二次发起请求,查询id为1的用户User user2=userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}3.5禁用二级缓存
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql,默认情况是true,即该sql使用二级缓存。
3.6刷新缓存(就是清空缓存)
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache="true"属性,默认情况下为true即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
总结:一般情况下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。
3.7 Mybatis Cache参数
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间端。默认情况是不设置,也局势没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
如下例子:
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:
LRU – 最近最少使用的:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
4.mybatis整合ehcache
ehcache是一个纯Java的进程内缓存框架,是一种广泛使用的开源Java分布式缓存,具有快速、精干等特点,是Hibernate中默认的CacheProvider。
4.1分布式缓存
为了提高系统并发、性能,一般会系统进行分布式部署(集群部署方式)

不使用分布式缓存,缓存的数据在各个服务单独存储,不方便系统开发。所以要使用分布式缓存对缓存数据进行集中管理。
mybatis的特长是sql操作,缓存数据的管理不是mybatis的特长。mybatis无法实现分布式缓存,需要和其它分布式缓存框架进行整合,如:redis、memcached、ehcache等。
4.2整合方法(掌握)
mybatis提供了一个cache接口,如果要实现自己的缓存逻辑,实现cache接口开发即可。
mybatis和ehcache整合,mybatis和ehcache整合包中提供了一个cache接口的实现类。

mybatis默认的cache实现类是:

4.3加入ehcache包

4.4整合ehcache
配置mapper中cache中的type为ehcache对cache接口的实现类型。


4.5加入ehcache的配置文件
在classpath下配置ehcache.xml
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"><diskStore path="F:\develop\ehcache" /><defaultCache maxElementsInMemory="1000"
maxElementsOnDisk="10000000"eternal="false"
overflowToDisk="false"
timeToIdleSeconds="120"timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"memoryStoreEvictionPolicy="LRU"></defaultCache></ehcache>Description de l'attribut :
diskStore : Spécifiez l'emplacement de stockage des données sur le disque.
defaultCache : Lors de la création d'un Cache avec CacheManager.add ("demoCache"), EhCache adoptera la stratégie de gestion spécifiée par
Les propriétés suivantes sont requises :
maxElementsInMemory : Le nombre maximum d'éléments mis en cache en mémoire.
maxElementsOnDisk : Le nombre maximum d'éléments mis en cache sur le disque, si 0 signifie l'infini.
éternel : définissez si les éléments mis en cache n'expireront jamais. Si c'est vrai, les données mises en cache sont toujours valides. Si c'est faux, vous devez les juger en fonction de timeToIdleSeconds et timeToLiveSeconds.
overflowToDisk : définissez s'il faut mettre en cache les éléments expirés sur le disque lorsque le cache mémoire déborde.
Les attributs suivants sont facultatifs :
timeToIdleSeconds : Lorsque le temps entre deux accès aux données mises en cache dans EhCache dépasse la valeur de l'attribut timeToIdleSeconds, les données seront supprimées. Valeur par défaut C'est le cas. 0, ce qui signifie que le temps d'inactivité est infini.
timeToLiveSeconds : La durée de vie effective de l'élément de cache. La valeur par défaut est 0, ce qui signifie que le temps de survie de l'élément est infini.
diskSpoolBufferSizeMB : Ce paramètre définit la taille du tampon de DiskStore (cache disque). La valeur par défaut est de 30 Mo, chaque cache doit avoir son propre tampon.
diskPersistent : s'il faut activer le disque pour enregistrer les données dans EhCache lorsque la VM est redémarrée. La valeur par défaut est false.
diskExpiryThreadIntervalSeconds - intervalle d'exécution du thread de nettoyage du cache disque, la valeur par défaut est de 120 secondes. Toutes les 120 secondes, le thread correspondant nettoiera les données dans EhCache.
memoryStoreEvictionPolicy - Lorsque le cache mémoire atteint la taille maximale et qu'un nouvel élément est ajouté, la politique de suppression des éléments du cache est utilisée. La valeur par défaut est LRU (la moins récemment utilisée), les options sont LFU (la moins fréquemment utilisée) et FIFO (premier entré, premier sorti).
Programme de test 4.6
Identique à 3.4
4.7 Scénario d'application de cache de deuxième niveau
Pour les requêtes de requêtes avec de nombreux accès et les utilisateurs n'ont pas de réel- temps requis pour les résultats des requêtes Élevé, à l'heure actuelle, la technologie de mise en cache de deuxième niveau de mybatis peut être utilisée pour réduire l'accès à la base de données et améliorer la vitesse d'accès. Les scénarios commerciaux incluent : une analyse statistique fastidieuse SQL, une requête de facture téléphonique SQL, etc.
La méthode de mise en œuvre est la suivante : en définissant l'intervalle de rafraîchissement, mybatis efface automatiquement le cache à intervalles réguliers et définit l'intervalle de rafraîchissement du cache flushInterval en fonction de la fréquence des modifications de données, par exemple en le définissant sur 30 minutes, 60 minutes, 24 heures, etc., selon Dépend de la demande.
4.8 Limitations du cache de deuxième niveau
Le cache de deuxième niveau Mybatis n'est pas efficace pour la mise en cache au niveau des données à granularité fine, comme les exigences suivantes : mise en cache des informations sur le produit, en raison du nombre de produits la requête d'informations visite Large, mais les utilisateurs doivent interroger les dernières informations sur le produit à chaque fois. À l'heure actuelle, si vous utilisez le cache de deuxième niveau de mybatis, il ne sera pas possible d'actualiser uniquement les informations mises en cache du produit lorsqu'un produit change et. ne pas actualiser les informations des autres produits, car la zone de cache de deuxième niveau de mybatis est divisée en mappeurs. Lorsqu'une information sur un produit change, toutes les données mises en cache de toutes les informations sur le produit seront effacées. Pour résoudre de tels problèmes, la couche métier doit mettre en cache les données de manière ciblée en fonction des besoins.
Si cet article vous est utile, veuillez me donner un conseil sur WeChat~

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Sous-chaîne de fenêtre minimale
- Boostez Java avec le projet Lombok : simplifiez votre code et augmentez votre productivité
- Comment choisir la meilleure méthode de distribution pour votre application Java ?
- Pourquoi l'appel de « sleep() » sur le fil de répartition d'événements gèle-t-il l'interface graphique ?
- Énumérations en tant que singletons en Java : constructeur privé ou méthodes statiques – Quelle approche vous convient le mieux ?