
Maison >Java >javaDidacticiel >implémentation du service de suivi spring-cloud-sleuth+zipkin (2)
implémentation du service de suivi spring-cloud-sleuth+zipkin (2)
- 巴扎黑original
- 2017-06-26 11:09:162187parcourir
1. Brève description
Dans la section précédente "implémentation du service de suivi spring-cloud-sleuth+zipkin (1)", nous avons utilisé microservice-zipkin-server, microservice-zipkin-client, microservice- Le trois programmes zipkin-client-backend implémentent le suivi des liens d'appel de service en utilisant http pour la communication et la persistance des données en mémoire.
Ici, nous apportons deux modifications. Premièrement, les données ne sont plus stockées en mémoire mais conservées dans la base de données. Deuxièmement, la communication http est modifiée en communication asynchrone mq.
Nous utilisons toujours les trois programmes de la section précédente pour apporter des modifications afin que chacun puisse voir les différences. Ici, un flux est ajouté à chaque nom de projet pour indiquer la différence.
2. microservice-zipkin-stream-server
Pour changer la méthode http en communication via MQ, nous devons remplacer la dépendance d'origine io.zipkin.java:zipkin-server Pour utiliser mysql persistance en même temps que spring-cloud-sleuth-zipkin-stream et spring-cloud-starter-stream-rabbit
, nous devons ajouter des dépendances liées à MySQL.
Toutes les dépendances maven sont les suivantes :
" <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--zipkin依赖--> <!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> "
Après avoir ajouté les dépendances maven ci-dessus, nous remplacerons l'annotation @EnableZipkinServer dans la classe de démarrage ZipkinServer par @EnableZipkinStreamServer,
Les détails sont les suivants :
package com.yangyang.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* Created by chenshunyang on 2017/5/24.
*/
@EnableZipkinStreamServer// //使用Stream方式启动ZipkinServer
@SpringBootApplication
public class ZipkinStreamServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinStreamServerApplication.class,args);
}
}
Cliquez sur le code source de l'annotation @EnableZipkinStreamServer et nous pouvons voir qu'il introduit également l'annotation @EnableZipkinServer et crée également un écouteur de file d'attente de messages lapin-mq. 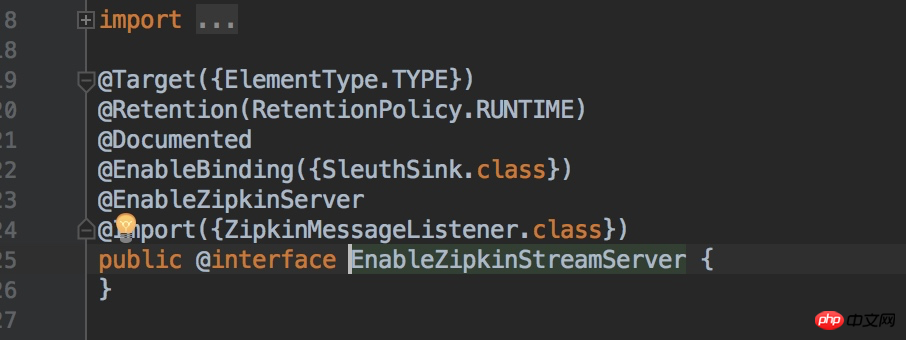
pour faciliter la réception des messages mq envoyés depuis le client de message.
Étant donné que le middleware de messages lapin mq et mysql sont utilisés, nous devons également ajouter les configurations pertinentes au fichier de configuration application.properties :
server.port=11020 spring.application.name=microservice-zipkin-stream-server #zipkin数据保存到数据库中需要进行如下配置 #表示当前程序不使用sleuth spring.sleuth.enabled=false #表示zipkin数据存储方式是mysql zipkin.storage.type=mysql #数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素 spring.datasource.schema[0]=classpath:/zipkin.sql #spring boot数据源配置 spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.initialize=true spring.datasource.continue-on-error=true #rabbitmq配置 spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
Parmi eux, zipkin.sql peut être copié directement sur le site officiel, vous pouvez également le copier à partir de cette démo
Afin d'éviter les interférences de la communication http, nous avons changé le port d'écoute d'origine de 11008 à 11020, démarré le programme, aucune erreur n'a été signalée et la connexion lapin Le journal peut être vu, indiquant que le programme a démarré avec succès.
3.microservice-zipkin-stream-client, microservice-zipkin-client-stream-backend
Identique à la configuration de la section précédente, la configuration du client est également très simple, et le dépendance maven uniquement Vous devez remplacer le spring-cloud-starter-zipkin d'origine par les deux dépendances suivantes
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
De plus, ajoutez la configuration pour vous connecter à MQ dans le fichier de configuration
server: port: 11021 spring: application: name: microservice-zipkin-stream-client #rabbitmq配置 rabbitmq: host: 127.0.0.1 port : 5672 username: guest password: guest
Bien entendu, afin de montrer la différence, le port a également été ajusté en conséquence
4 Test
Accès comme dans la section précédente : http://localhost:11021/. call/1, nous pouvons La section précédente explique que la fonction détective de la communication lapin-mq a pris effet.
Nous avons visité l'adresse du consommateur à plusieurs reprises et pouvons voir dans le journal que le délai de demande ne prendra pas soudainement beaucoup de temps.
Afin de bénéficier de la fonctionnalité d'absence de perte de données que nous offre la communication MQ, nous effaçons les données de la base de données, puis actualisons l'interface du serveur zipkin. Vous pouvez voir qu'il n'y a plus de données
Bientôt, nous voyons que le nom Span. L'option a des données pour sélectionner, et en même temps, les enregistrements dans la base de données Le nombre d'entrées n'est plus le précédent 0
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!