
Maison >Java >javaDidacticiel >Introduction au processus d'analyse des données hors ligne
Introduction au processus d'analyse des données hors ligne
- 巴扎黑original
- 2017-06-26 11:33:451865parcourir
3. Hors ligneAnalyse des donnéesIntroduction au processus
Remarque : ce lien se concentre principalement sur l'expérience du concept macro et du flux de traitement du système d'analyse de données, et sur la compréhension initiale des liens d'application de hadoop et d'autres frameworks. N'y prêtez pas trop attention. Détails du code
Un système d'analyse de données largement utilisé : "Webexploration de données de journaux"
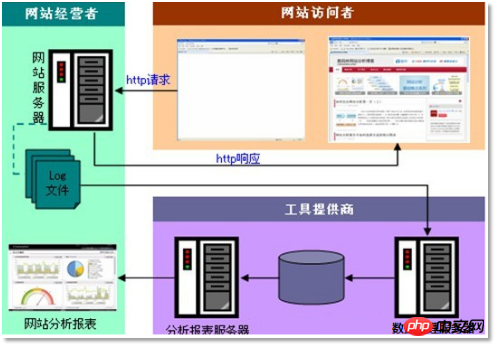
3.1 Analyse des exigences
3.1.1 Nom du cas
"Site Web ou APP Système d'exploration de données de journaux Clickstream".
3.1.2 Description des exigences du cas
«Web Le « journal Clickstream » contient des informations très importantes pour le fonctionnement du site Web. Grâce à l'analyse du journal, nous pouvons connaître le nombre de visites sur le site Web, quelle page Web a le plus de visiteurs, quelle page Web est la plus précieuse, le taux de conversion publicitaire, les informations sur la source des visiteurs et informations sur le terminal visiteur.
3.1.3 Source des données
Les données dans ce cas sont principalement fournies par Enregistrement du comportement de clic de l'utilisateur
Comment l'obtenir : Pré-intégrer un programme js sur la page du les éléments que vous souhaitez surveiller sur l'événement de liaison d'étiquette de la page, tant que l'utilisateur clique ou se déplace vers l'étiquette, cela peut déclencher la requête ajax en arrière-plan servlet, utilisez log4j enregistre les informations sur l'événement sur le serveur web (nginx, tomcat, etc.).
Forme :
58.215.204.118 - - [18/septembre/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens . me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
|
3.2 Flux de traitement des données
3.2.1 Analyse des organigrammes
Ce cas est très similaire au système BI typique, et le processus global est le suivant :

Cependant, puisque la prémisse de cette affaire
est traite des quantités massives de données. Par conséquent, les technologies utilisées dans chaque maillon du processus sont complètement différentes de la BI traditionnelle. Les cours suivants les expliqueront une par une : <.>1) Collecte de données : programme de collecte développé sur mesure, ou utilisez le framework open source
FLUME2) Prétraitement des données :
mapreducele programme fonctionne surhadoopCluster3) Technologie d'entrepôt de données :
Hivehadoop 🎜>4) Export de données : sqoop
outil d'importation et d'exportation de données basé sur hadoop 5) Visualisation des données : Développement personnalisé de programmes web ou utilisation de produits tels que
kettle 6) de l'ensemble du processus Planification des processus : hadoop
oozie outils ou autres produits open source similaires dans l'écosystème 3.2.2
Schéma de l'architecture technique du projet  3.2.3
3.2.3
a) MapreudceProgramme en cours d'exécution

Interroger des données dans
Hive

Importer les résultats statistiques dans
mysql| ./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export- dir /user/hive/warehouse/uv /dt=2014-08-03 |
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
3.3
Effet final du projet
Après une étude complète des données processus de traitement, diverses statistiques seront produites périodiquement. Rapports d'indicateurs, dans la pratique de production, ces données de rapport doivent finalement être affichées sous une forme visuelle. Dans ce cas, le programme web
est utilisé pour réaliser la visualisation des données <.>effet Comme indiqué ci-dessous :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment les assertions Java peuvent-elles améliorer la qualité du code et prévenir les erreurs ?
- La déclaration de chaînes comme « finales » en Java affecte-t-elle les comparaisons « == » ?
- Manipulation de chaînes en Java
- Comment mettre à jour en permanence JLabel avec les résultats d'une tâche de longue durée ?
- Comment convertir int[] en Integer[] pour l'utiliser comme clés de carte en Java ?