
Maison >interface Web >js tutoriel >Exemple de tutoriel sur l'exploration des informations sur les cours MOOC
Exemple de tutoriel sur l'exploration des informations sur les cours MOOC

- 零下一度original
- 2017-06-26 10:36:502585parcourir
C'est la première fois que j'apprends le robot Node.js, il s'agit donc d'un robot simple. L'avantage de Node.js est qu'il peut être exécuté simultanément
Ceci. Le robot d'exploration consiste principalement à obtenir des informations sur les cours sur MOOC.com et à stocker les informations obtenues dans un fichier, qui utilise la bibliothèque cheerio, ce qui nous permet d'utiliser facilement le HTML, tout comme jQ
Avant de commencer, n'oubliez pas
npm install cheerio
Afin d'explorer simultanément, l'objet Promise
//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}
Dans MOOC.com, chaque cours a un identifiant Il faut écrire l'identifiant du cours que l'on souhaite entrer dans un tableau à l'avance, et l'adresse. de chaque cours est la même adresse plus l'identifiant, il suffit donc de concaténer l'adresse et l'identifiant pour obtenir l'adresse du cours
const baseUrl = 'http://www.imooc.com/learn/'; const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];
Afin d'obtenir le contenu de chaque cours simultanément, utilisez la méthode all dans Promise
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});
Dans le puis méthode, pages est la page HTML de chaque cours. Nous devons également en extraire les informations dont nous avons besoin. Nous devons utiliser la fonction suivante
//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}<.>Remarque : le nombre d'étudiants qui étudient le cours est fixé à 0 dans ce qui précède car le nombre d'étudiants qui étudient le cours est obtenu dynamiquement en utilisant Ajax, j'ai donc écrit une méthode plus tard pour obtenir spécifiquement le nombre d'étudiants qui étudient le cours, et la méthode Trim() utilisée est Supprimer les espaces dans le texte
Obtenir le nombre de personnes apprenant le cours :
//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}De cette façon, vous souhaiterez obtenir le cours. Le nombre d'étudiants qui étudient est ajouté au tableau courseMembers, et enfin le nombre d'étudiants qui étudient le cours est attribué au cours correspondant
//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}Après avoir obtenu les données, nous devons les enregistrer dans un fichier dans un certain format
//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
} Le dernier obtenu Données :
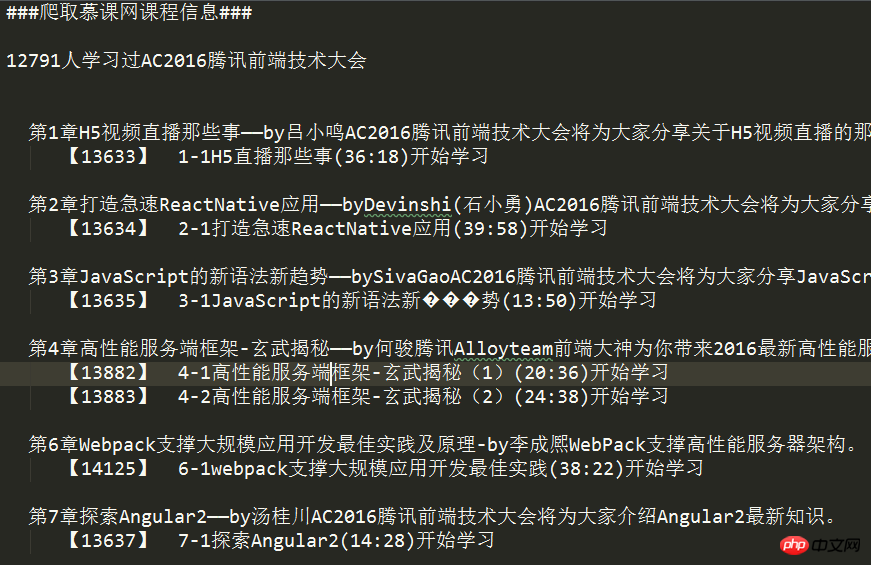
Code source :
/**
* Created by hp-pc on 2017/6/7 0007. */const http = require('http');
const fs = require('fs');
const cheerio = require('cheerio');
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];//输出的文件const outputFile = 'test.txt';//记录学习课程的人数let courseMembers = [];//去除字符串中的空格function Trim(str,is_global)
{
let result;
result = str.replace(/(^\s+)|(\s+$)/g,"");if(is_global.toLowerCase()=="g")
{
result = result.replace(/\s/g,"");
}return result;
}//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}//所有页面爬取完后返回的Promise数组let courseArray = [];//循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容videosId.forEach((id)=>{//将爬取网页完毕后返回的Promise对象加入数组courseArray.push(getPageAsync(baseUrl + id));//获取学习的人数getNumber(baseNuUrl + id);
});
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript