
Maison >base de données >tutoriel mysql >Principes d'optimisation MySQL
Principes d'optimisation MySQL

- 大家讲道理original
- 2017-05-28 11:24:141421parcourir
En parlant d'optimisation des requêtes de MySQL, je crois que tout le monde a accumulé beaucoup de compétences : n'utilisez pas SELECT *, n'utilisez pas de champs NULL , et créer raisonnablement une Indexation , en choisissant le type de données approprié pour le champ ... Comprenez-vous vraiment ces techniques d'optimisation ? Comprenez-vous comment ça marche ? Les performances sont-elles vraiment améliorées dans les scénarios réels ? Je ne pense pas. Par conséquent, il est particulièrement important de comprendre les principes qui sous-tendent ces suggestions d’optimisation. J’espère que cet article vous permettra de réexaminer ces suggestions d’optimisation et de les appliquer raisonnablement dans des scénarios commerciaux réels.
Logique MySQLArchitecture
Si vous pouvez vous faire une idée du fonctionnement des différents composants de MySQL Le diagramme d'architecture ensemble aide à comprendre le serveur MySQL en profondeur. La figure suivante montre le diagramme d'architecture logique de MySQL.
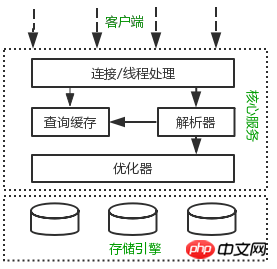
Architecture logique MySQL, de : MySQL hautes performances
L'architecture logique MySQL est divisée en trois couches. La couche supérieure est la couche client, qui n'est pas propre à MySQL. Des fonctions telles que : traitement des connexions, authentification des autorisations, sécurité<.> et d'autres fonctions sont toutes traitées à ce niveau.
La plupart des services de base de MySQL se trouvent dans la couche intermédiaire, y compris l'analyse des requêtes, l'analyse, l'optimisation, lamise en cache, les fonctions intégrées ( telles que : temps, mathématiques, cryptage et autres fonctions). Toutes les fonctions du moteur de stockage cross-storage sont également implémentées dans cette couche : procédures stockées, déclencheurs, vues, etc.
La couche inférieure est le moteur de stockage, qui est responsable du stockage et de la récupération des données dans MySQL. Semblable auSystème de fichiers sous Linux, chaque moteur de stockage a ses avantages et ses inconvénients. La couche de service intermédiaire communique avec le moteur de stockage via des API Ces interfaces API protègent les différences entre les différents moteurs de stockage.
Processus de requête MySQL Nous espérons toujours que MySQL pourra obtenir des performances de requête plus élevées. Le meilleur moyen est de comprendre comment MySQL optimise et exécute les requêtes. Une fois que vous aurez compris cela, vous constaterez qu'une grande partie du travail d'optimisation des requêtes ne fait que suivre certains principes afin que l'optimiseur MySQL puisse fonctionner de la manière attendue et raisonnable. Lors de l'envoi d'une requête à MySQL, que fait exactement MySQL ?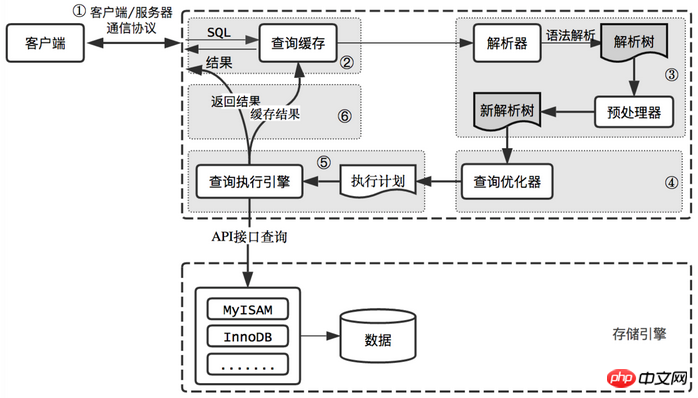
Le protocole de communication client/serveur MySQL est "half-duplex" : à tout moment, soit le serveur envoie des données au client, soit le client envoie des données au serveur, ces deux actions ne peuvent pas se produire en même temps. Une fois qu'une extrémité commence à Le client envoie la demande de requête au serveur dans un paquet de données séparé, donc lorsque l'instruction de requête est très longue, vous devez définir le max_
allowed_packet paramètre. Cependant, il convient de noter que si la requête est trop volumineuse, le serveur refusera de recevoir plus de données et lèvera une exception.
Au contraire, le serveur répond à l'utilisateur avec généralement beaucoup de données, constituées de plusieurs paquets de données. Mais lorsque le serveur répond à la demande du client, celui-ci doit recevoir l'intégralité du résultat renvoyé, au lieu de simplement prendre les premiers résultats et demander ensuite au serveur d'arrêter l'envoi. Par conséquent, dans le développement actuel, c'est une très bonne habitude de garder les requêtes aussi simples que possible et de ne renvoyer que les données nécessaires, et de réduire la taille et le nombre de paquets de données pendant la communication. C'est aussi la raison pour laquelle nous essayons d'éviter d'utiliser SELECT. * et ajout de restrictions LIMIT dans la première requête. Cache de requêtesAvant d'analyser une instruction de requête, si le cache de requêtes est activé, MySQL vérifiera si l'instruction de requête atteint les données dans le cache de requêtes. Si la requête en cours atteint le cache de requêtes, les résultats dans le cache seront renvoyés directement après avoir vérifié une fois les autorisations de l'utilisateur. Dans ce cas, la requête ne sera pas analysée, aucun plan d’exécution ne sera généré et elle ne sera pas exécutée.
MySQL stocke le cache dans une table référence (ne la comprenez pas comme une table, elle peut être considérée comme similaire à Hash Map structure de données), indexé par une valeur de hachage, qui est calculée à partir de la requête elle-même, de la base de données en cours d'interrogation, du numéro de version du protocole client et d'autres informations pouvant affecter les résultats. Par conséquent, toute différence de caractères entre les deux requêtes (par exemple : espaces, commentaires ) entraînera une perte du cache.
Si la requête contient un utilisateurfonction personnalisée, une fonction stockée, une variable utilisateur, une table temporaire, une table système dans la bibliothèque MySQL, les résultats de la requête
ne seront pas mis en cache. Par exemple, la fonction NOW() ou CURRENT_DATE() renverra des résultats de requête différents en raison de temps de requête différents. Un autre exemple est que l'instruction de requête contient CURRENT_USER ou CONNECION_ID(). renverra des résultats de requête différents en raison de temps de requête différents. Différents résultats sont renvoyés pour différents utilisateurs, et cela n'a aucun sens de mettre en cache ces résultats de requête.
Puisqu'il s'agit d'un cache, il expirera Quand le cache des requêtes expirera-t-il ? Le système de mise en cache de requête MySQL suivra chaque table impliquée dans la requête. Si ces tables (données ou structure) changent, toutes les données mises en cache liées à cette table seront invalides. Pour cette raison, MySQL doit invalider tous les caches de la table correspondante lors de toute opération d'écriture. Si le cache de requêtes est très volumineux ou fragmenté, cette opération peut entraîner une consommation importante du système et même provoquer un blocage du système pendant un certain temps. De plus, la consommation supplémentaire du cache de requêtes sur le système ne concerne pas seulement les opérations d'écriture, mais aussi les opérations de lecture :
Toute instruction de requête doit être vérifiée avant de démarrer, même cette instruction SQL Le cache ne sera jamais atteint
Si les résultats de la requête peuvent être mis en cache, une fois l'exécution terminée, les résultats seront stockés dans le cache, ce qui entraînera également une consommation supplémentaire du système
Sur cette base, nous devons savoir que la mise en cache des requêtes n'améliorera pas les performances du système dans toutes les circonstances. La mise en cache et l'invalidation entraîneront une consommation supplémentaire uniquement lorsque les économies de ressources apportées par la mise en cache sont supérieures. les ressources consommées par elles-mêmes peuvent améliorer les performances du système. Cependant, il est très difficile d’évaluer si l’activation du cache peut apporter des améliorations de performances, et cela dépasse le cadre de cet article. Si le système rencontre des problèmes de performances, vous pouvez essayer d'activer le cache de requêtes et d'effectuer quelques optimisations dans la conception de la base de données, telles que :
Remplacer une grande table par plusieurs petites tables. , veillez à ne pas en faire trop. Concevez une
insertion par lots au lieu d'une boucle insertion unique
pour contrôler raisonnablement le. taille de l'espace de cache. De manière générale, la taille est définie sur Plusieurs dizaines de mégaoctets sont plus appropriés
Vous pouvez utiliser SQL_CACHE et SQL_NO_CACHE pour contrôler si un certain L'instruction de requête doit être mise en cache
Le dernier conseil est de ne pas activer facilement le cache de requêtes, en particulier pour les applications gourmandes en écriture. Si vous ne pouvez vraiment pas vous en empêcher, vous pouvez définir query_cache_type sur DEMAND. Pour le moment, seules les requêtes qui ajoutent SQL_CACHE seront mises en cache, et les autres requêtes ne le seront pas. Cela vous permet de contrôler librement quelles requêtes doivent être mises en cache.
Bien sûr, le système de cache de requêtes lui-même est très complexe, et ce qui est abordé ici n'est qu'une petite partie d'autres sujets plus approfondis, tels que : Comment le cache utilise-t-il la mémoire. ? Comment contrôler la fragmentation de la mémoire ? Les lecteurs peuvent lire eux-mêmes les informations pertinentes concernant l’impact des transactions sur le cache de requêtes, etc. C’est par là qu’il faut commencer.
Analyse grammaticale et prétraitement
MySQL analyse l'instruction SQL à l'aide de mots-clés et génère un arbre d'analyse correspondant. Cet analyseur de processus vérifie et analyse principalement les règles de grammaire. Par exemple, si les mauvais mots-clés sont utilisés dans SQL ou si l'ordre des mots-clés est correct, etc. Le prétraitement vérifiera en outre si l'arbre d'analyse est légal selon les règles MySQL. Par exemple, vérifiez si la table de données et la colonne de données à interroger existent, etc.
Optimisation des requêtes
L'arbre syntaxique généré par les étapes précédentes est considéré comme légal et est converti en plan de requête par l'optimiseur. Dans la plupart des cas, une requête peut être exécutée de plusieurs manières, et toutes renverront les résultats correspondants. Le rôle de l’optimiseur est de trouver parmi eux le meilleur plan d’exécution.
MySQL utilise un optimiseur basé sur les coûts, qui tente de prédire le coût d'une requête en utilisant un certain plan d'exécution et sélectionne celui avec le coût le plus bas. Dans MySQL, vous pouvez obtenir le coût de calcul de la requête en cours en interrogeant la valeur de last_query_cost de la session en cours.
Code MySQL
mysql> sélectionnez * dans la limite t_message 10
-
... Omettre l'ensemble de résultats
mysql> affiche le statut comme 'last_query_cost'
+---- -------------+------------+
| Nom de la variable | 🎜>
+-----------------+-------------+ - | Coût_dernière_requête | 6391.799000
- +----------------+------------ -+
Les résultats de l'exemple indiquent que l'optimiseur estime qu'il faut environ 6391 recherches aléatoires de pages de données pour terminer la requête ci-dessus. Ce résultat est calculé sur la base de certaines statistiques de colonnes, qui incluent : le nombre de pages dans chaque table ou index, la cardinalité de l'index, la longueur de l'index et des lignes de données, la distribution de l'index, etc.
Il existe de nombreuses raisons pour lesquelles MySQL peut choisir le mauvais plan d'exécution, telles que des informations statistiques inexactes et l'incapacité de prendre en compte les coûts d'exploitation indépendants de sa volonté (fonctions définies par l'utilisateur, procédures stockées), ce MySQL pense que ce qui est optimal est différent de ce que nous pensons (nous voulons que le temps d'exécution soit aussi court que possible, mais MySQL choisit la valeur, il pense que le coût est faible, mais un petit coût ne signifie pas un temps d'exécution court) et ainsi de suite.
L'optimiseur de requêtes MySQL est un composant très complexe qui utilise de nombreuses stratégies d'optimisation pour générer un plan d'exécution optimal :
- Redéfinir l'ordre d'association de tables (lorsque plusieurs tables sont associées à des requêtes, elles ne suivent pas nécessairement l'ordre spécifié en SQL, mais il existe quelques techniques pour spécifier l'ordre d'association)
- Optimisation MIN() et Fonctions MAX() (trouver la valeur minimale d'une certaine colonne. Si la colonne a un index, il vous suffit de trouver l'extrémité la plus à gauche de l'index B+Tree. Sinon, vous pouvez trouver la valeur maximale. Voir ci-dessous pour les fonctions spécifiques. principe)
- Optimiser le tri (utilisé dans les anciennes versions de MySQL Tri à deux transmissions, c'est-à-dire lire d'abord le pointeur de ligne et les champs qui doivent être triés, les trier en mémoire, puis lire les lignes de données en fonction des résultats du tri , tandis que la nouvelle version utilise le tri à transmission unique, qui est une lecture. Toutes les lignes de données sont ensuite triées en fonction de la colonne donnée. Pour les applications gourmandes en E/S, l'efficacité sera beaucoup plus élevée)
- À mesure que MySQL continue de se développer, l'optimiseur utilise des stratégies d'optimisation en constante évolution. Voici quelques stratégies d'optimisation très couramment utilisées et faciles à comprendre. Pour d'autres stratégies d'optimisation, vous pouvez les consulter par vous-même.
dl
erAPI. Chaque table du processus de requête est représentée par une instance de gestionnaire. En fait, MySQL crée une instance de gestionnaire pour chaque table pendant la phase d'optimisation des requêtes. L'optimiseur peut obtenir des informations relatives aux tables en fonction des interfaces de ces instances, y compris tous les noms de colonnes de la table, les statistiques d'index, etc. L'interface du moteur de stockage fournit des fonctions très riches, mais il n'y a que des dizaines d'interfaces dans la couche inférieure. Ces interfaces sont comme des éléments de base pour effectuer la plupart des opérations d'une requête. Renvoyer les résultats au client La dernière étape de l'exécution d'une requête consiste à renvoyer les résultats au client. Même si aucune donnée ne peut être interrogée, MySQL renverra toujours des informations pertinentes sur la requête, telles que le nombre de lignes affectées par la requête et le temps d'exécution, etc. Si le cache de requêtes est activé et que la requête peut être mise en cache, MySQL stockera également les résultats dans le cache. Le renvoi de l'ensemble de résultats au client est un processus de retour incrémentiel et progressif. Il est possible que MySQL commence à renvoyer progressivement l'ensemble de résultats au client lorsqu'il génère le premier résultat. De cette façon, le serveur n'a pas besoin de stocker trop de résultats et de consommer trop de mémoire, et le client peut également obtenir les résultats renvoyés dès que possible. Il convient de noter que chaque ligne de l'ensemble de résultats sera envoyée sous forme de paquet de données répondant au protocole de communication décrit dans ①, puis transmis via le protocole TCP. Pendant le processus de transmission, les paquets de données MySQL peuvent être mis en cache puis envoyés. lots.Revenons en arrière et résumons l'ensemble du processus d'exécution de requête de MySQL De manière générale, il est divisé en 6 étapes :
Le client envoie une requête de requête au serveur MySQL
- Le serveur vérifie d'abord le cache des requêtes, et s'il atteint le cache, il renvoie immédiatement les résultats stockés dans le cache. Sinon, passez à l'étape suivante
- Le serveur effectue l'analyse et le prétraitement SQL, puis l'optimiseur génère le plan d'exécution correspondant
- MySQL exécute le planifier selon , appeler l'API du moteur de stockage pour exécuter la requête
- et renvoyer les résultats au client, tout en mettant en cache les résultats de la requête
Optimisation des performancesSuggestions
Après avoir autant lu, vous pouvez vous attendre à quelques méthodes d'optimisation. Oui, quelques suggestions d'optimisation seront données ci-dessous sous 3 aspects différents. Mais attendez, il y a un autre conseil que je veux d'abord vous donner : ne croyez pas la « vérité absolue » que vous voyez sur l'optimisation, y compris ce qui est discuté dans cet article, mais vérifiez-la en testant des hypothèses commerciales réelles. sur les plans d’exécution et les délais de réponse. Conception du schéma et optimisation des types de donnéesSuivez simplement le principe du petit et du simple lors du choix des types de données. Les types de données plus petits sont généralement plus rapides et occupent moins d'espace disque. , de la mémoire et nécessite moins de cycles CPU pour le traitement. Les types de données plus simples nécessitent moins de cycles CPU lors des calculs. Par exemple, les entiers sont moins chers que les opérations sur les caractères, donc les entiers sont utilisés pour stocker les adresses IP, DATETIME est utilisé pour stocker l'heure et au lieu d'utiliser . Chaîne.
Voici quelques conseils qui peuvent être faciles à comprendre et à commettre des erreurs :- De manière générale, changer une colonne NULL en NOT NULL ne sera pas Dans quelle mesure cela améliore-t-il les performances, sauf que si vous envisagez de créer un index sur une colonne, vous devez définir la colonne sur NOT NULL.
- Spécifier la largeur pour le
- UNSIGNED signifie que les valeurs négatives ne sont pas autorisées, ce qui peut environ doubler la limite supérieure des nombres positifs. Par exemple, la plage de stockage de TINYINT est généralement parlant et il n'est pas nécessaire d'utiliser le type de données DECIMAL. Même lorsque vous devez stocker des données financières, vous pouvez toujours utiliser BIGINT. Par exemple, si vous devez être précis au dix millième près, vous pouvez multiplier les données par un million et utiliser TIMESTAMP pour utiliser 4 octets d'espace de stockage et DATETIME pour utiliser 8 octets d'espace de stockage. Par conséquent, TIMESTAMP ne peut représenter que 1970 à 2038, ce qui est une plage beaucoup plus petite que DATETIME, et la valeur de TIMESTAMP varie en fonction du fuseau horaire.
- Dans la plupart des cas, il n'est pas nécessaire d'utiliser des types énumérés. L'un des inconvénients est que la liste des chaînes énumérées est fixe, ajoutant et
- N'ayez pas trop de colonnes de schéma. La raison en est que lorsque l'API du moteur de stockage fonctionne, elle doit copier les données entre la couche serveur et la couche moteur de stockage via le format de tampon de ligne, puis décoder le contenu du tampon dans chaque colonne de la couche serveur. le processus est très élevé. S'il y a trop de colonnes et que peu de colonnes sont réellement utilisées, cela peut entraîner une utilisation élevée du processeur.
- ALTER TABLE d'une grande table prend beaucoup de temps. La façon dont MySQL effectue la plupart des opérations de résultat
Habituellement, l'index auquel nous faisons référence fait référence à l'index B-Tree, qui est actuellement l'index le plus couramment utilisé et le plus efficace pour rechercher des données dans les bases de données relationnelles. Le terme B-Tree est utilisé parce que MySQL utilise ce mot-clé dans CREATE TABLE ou d'autres instructions , mais en fait différents moteurs de stockage peuvent utiliser différentes structures de données. Par exemple, InnoDB utilise B+ Tree.
Le B dans B+Tree fait référence à l'équilibre, ce qui signifie équilibre. Il convient de noter que l'index de l'arborescence B+ ne peut pas trouver une ligne spécifique avec une valeur de clé donnée. Il trouve uniquement la page où se trouve la ligne de données recherchée. Ensuite, la base de données lira la page dans la mémoire, puis recherchera dans la mémoire. , et enfin Obtenez les données que vous recherchez. Avant d'introduire B+Tree, comprenons d'abord l'arbre de recherche binaire. Il s'agit d'une structure de données classique. La valeur de son sous-arbre gauche est toujours inférieure à la valeur de la racine. La valeur du sous-arbre est toujours supérieure à la valeur de la racine, comme le montre la figure ci-dessous ①. Si vous souhaitez trouver un enregistrement avec une valeur de 5 dans cet arbre de cours, le processus général est le suivant : trouvez d'abord la racine, dont la valeur est 6, qui est supérieure à 5, donc recherchez dans le sous-arbre de gauche et trouvez 3, et 5 est supérieur à 3, puis trouvez le bon sous-arbre de 3 Tree, je l'ai trouvé 3 fois au total. De la même manière, si vous recherchez un enregistrement avec une valeur de 8, vous devez également rechercher 3 fois. Par conséquent, le nombre moyen de recherches dans l'arbre de recherche binaire est de (3 + 3 + 3 + 2 + 2 + 1) / 6 = 2,3 fois. Si vous effectuez une recherche séquentielle, vous n'avez besoin que d'une seule fois pour trouver l'enregistrement avec la valeur 2. mais la valeur de recherche est de 8, les enregistrements nécessitent 6 fois, donc le nombre moyen de recherches pour la recherche séquentielle est : (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3,3 fois, car dans la plupart des cas, la vitesse de recherche moyenne de l'arbre de recherche binaire est La recherche séquentielle est plus rapide.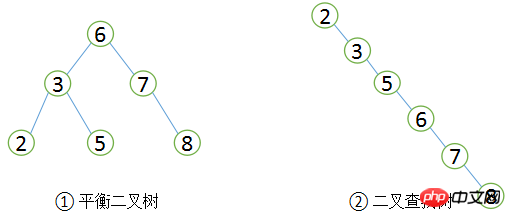
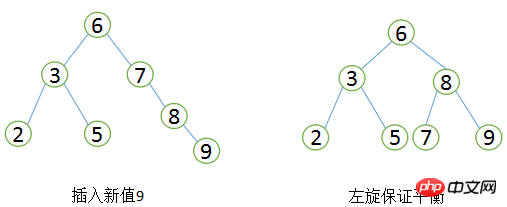
MySQL Index n'utilise-t-il pas directement des binaires équilibrés. des arbres ?
À mesure que les données dans la base de données augmentent, la taille de l'index lui-même augmente et il est impossible de tout stocker en mémoire, donc l'index est souvent stocké sur disque sous la forme d'un fichier d'index. Dans ce cas, la consommation d'E/S disque sera engagée pendant le processus de recherche d'index. Par rapport à l'accès à la mémoire, la consommation d'accès aux E/S est plusieurs ordres de grandeur plus élevée. Pouvez-vous imaginer la profondeur d’un arbre binaire avec des millions de nœuds ? Si un arbre binaire d'une telle profondeur est placé sur un disque, chaque fois qu'un nœud est lu, une lecture d'E/S à partir du disque est requise, et le temps de recherche complet est évidemment inacceptable. Alors, comment réduire le nombre d’accès E/S pendant le processus de recherche ? Une solution efficace consiste à réduire la profondeur de l'arbre et à changer l'arbre binaire en un arbre m-aire (arbre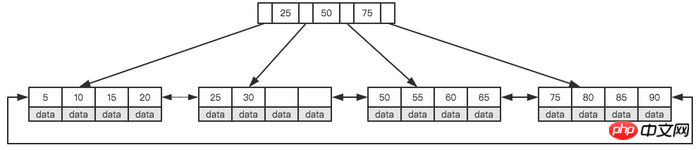
Comment comprendre ces deux caractéristiques ? MySQL définit la taille de chaque nœud sur un multiple entier d'une page (les raisons seront présentées ci-dessous), c'est-à-dire que lorsque la taille de l'espace du nœud est certaine, chaque nœud peut stocker plus de nœuds internes, de sorte que chaque nœud puisse La plage de l'index est plus grand et plus précis. L'avantage d'utiliser des liens de pointeur pour tous les nœuds feuilles est que l'accès par intervalle est possible. Par exemple, dans la figure ci-dessus, si vous recherchez des enregistrements supérieurs à 20 et inférieurs à 30, il vous suffit de trouver le nœud 20 et vous pouvez le faire. parcourez les pointeurs pour trouver 25 et 30 dans l’ordre. S'il n'y a pas de pointeur de lien, la recherche par intervalle ne peut pas être effectuée. C'est également une raison importante pour laquelle MySQL utilise B+Tree comme structure de stockage d'index.
Pourquoi MySQL fixe la taille du nœud à un multiple entier de la page, cela nécessite de comprendre le principe de stockage du disque. La vitesse d'accès du disque lui-même est beaucoup plus lente que celle de la mémoire principale. En plus de la perte de mouvement mécanique (en particulier les disques durs mécaniques ordinaires), la vitesse d'accès du disque est souvent un millionième de celle de la mémoire principale. Afin de minimiser les E/S du disque, le disque n'est souvent pas lu strictement à la demande, mais sera lu à l'avance à chaque fois. Même si un seul octet est nécessaire, le disque démarrera à partir de cette position et lira séquentiellement une certaine longueur de données. en arrière et le mettre en mémoire. La longueur de la pré-lecture Généralement un multiple entier de pages.
Citation
Une page est un bloc logique de mémoire gérée par l'ordinateur. Le matériel et le système d'exploitation divisent souvent la mémoire principale et les zones de stockage sur disque en blocs consécutifs de taille égale. . (Dans de nombreux systèmes d'exploitation, la taille de la page est généralement de 4K). La mémoire principale et le disque échangent des données en unités de pages. Lorsque les données à lire par le programme ne sont pas dans la mémoire principale, une exception de défaut de page sera déclenchée. À ce moment, le système enverra un signal de lecture au disque et le disque trouvera la position de départ des données. et lisez une ou plusieurs pages à l'envers. Chargez-les en mémoire, puis revenez anormalement et le programme continue de s'exécuter.
MySQL utilise intelligemment le principe de lecture anticipée du disque pour définir la taille d'un nœud égale à une page, afin que chaque nœud n'ait besoin que d'une seule E/S pour être complètement chargé. Afin d'atteindre cet objectif, chaque fois qu'un nouveau nœud est créé, une page d'espace est directement demandée. Cela garantit qu'un nœud est physiquement stocké dans une page. De plus, l'allocation de stockage informatique est alignée sur la page, réalisant ainsi. la lecture d'un nœud. Une seule E/S est nécessaire. En supposant que la hauteur de B+Tree est h, une récupération nécessite au plus h-1E/S (mémoire résidente du nœud racine) et la complexité $O(h) = O(log_{M}N)$. Dans les scénarios d'application réels, M est généralement grand, dépassant souvent 100, de sorte que la hauteur de l'arbre est généralement petite, généralement pas supérieure à 3.
Enfin, comprenons brièvement le fonctionnement du nœud B+Tree et ayons une compréhension générale de la maintenance de l'index. Bien que l'index puisse grandement améliorer l'efficacité des requêtes, il reste quand même. Cela coûte de l'argent pour maintenir l'index. Le coût est très élevé, il est donc particulièrement important de créer des index de manière raisonnable.
Toujours en prenant l'arbre ci-dessus comme exemple, nous supposons que chaque nœud ne peut stocker que 4 nœuds internes. Tout d'abord, insérez le premier nœud 28, comme indiqué dans la figure ci-dessous.
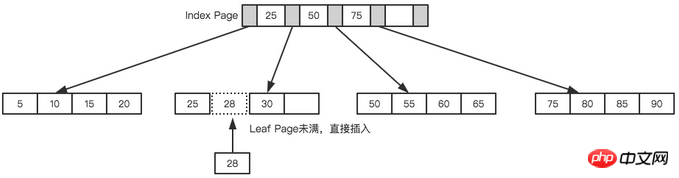
Ni la page feuille ni la page index ne sont pleines
Alors Insérer le prochain Pour un nœud 70, après avoir interrogé la page d'index, nous avons appris qu'il doit être inséré dans un nœud feuille entre 50 et 70, mais le nœud feuille est plein à ce stade, nous devons effectuer une opération de fractionnement. Le point de départ actuel du nœud feuille est 50, donc selon La valeur intermédiaire est utilisée pour diviser les nœuds feuilles, comme le montre la figure ci-dessous.
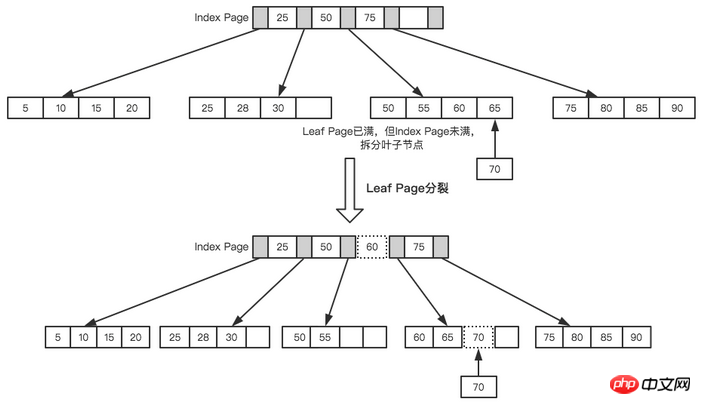
Feuille de page
Enfin insérez un nœud 95, ce Quand la page d'index et la page feuille sont pleines, deux divisions sont nécessaires, comme le montre la figure ci-dessous.
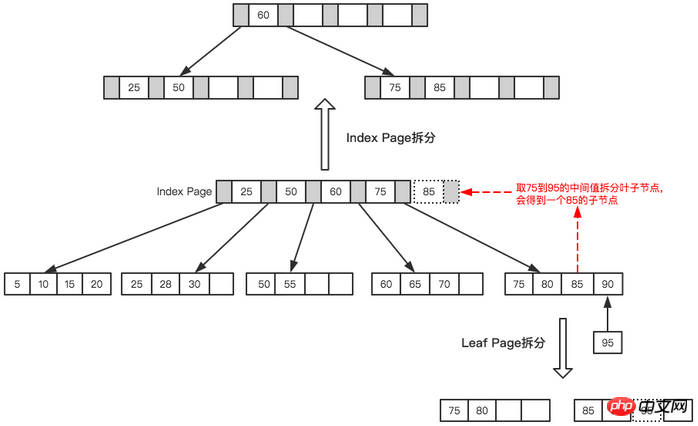
Page feuille et page d'index divisées
Finale après division Un tel l'arbre s'est formé.
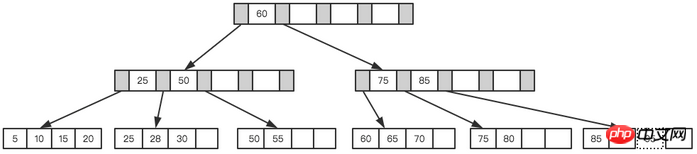
Arbre final
B+Arbre Afin de maintenir l'équilibre, pour les nouvelles valeurs insérées nécessitent un grand nombre d'opérations de fractionnement pagination , et le fractionnement de page nécessite des opérations d'E/S Afin de réduire autant que possible les opérations de fractionnement de page, B+Tree fournit également un équilibre. arbre binaire. Fonction de rotation. Lorsque LeafPage est pleine mais que ses nœuds frères gauche et droit ne sont pas pleins, B+Tree n'est pas désireux d'effectuer l'opération de fractionnement, mais déplace l'enregistrement vers les nœuds frères de la page actuelle. Normalement, le frère gauche est vérifié en premier pour les opérations de rotation. Par exemple, dans le deuxième exemple ci-dessus, lorsque 70 est inséré, le fractionnement de page n'est pas effectué, mais une opération de virage à gauche est effectuée.
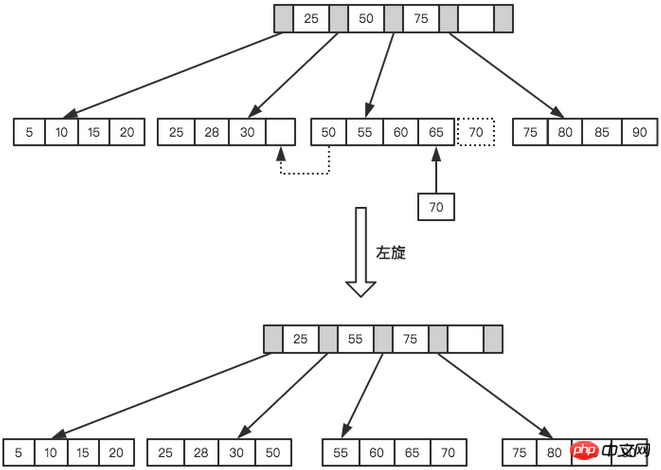
Opération de virage à gauche
L'opération de rotation peut minimiser le nombre de pages divisées, réduisant ainsi les opérations d'E/S de disque pendant la maintenance de l'index et améliorant l'efficacité de la maintenance de l'index. Il convient de noter que la suppression de nœuds et l'insertion de types de nœuds nécessitent toujours des opérations de rotation et de fractionnement, qui ne seront pas expliquées ici.
Stratégie haute performance
Grâce à ce qui précède, je pense que vous avez déjà une compréhension générale de la structure des données de B+Tree, mais comment l'index dans MySQL organise-t-il le stockage des données ? Pour illustrer avec un exemple simple, s'il existe la table de données suivante :
Code MySQL
CREATE TABLE People(
nom de famille varchar(50) non nul,
prénom varchar(50) non nul,
date de naissance non nulle,
genre enum(`m`,`f`) non nul,
-
clé(nom, prénom, dob)
);
Pour chaque ligne de données du tableau, l'index contient les valeurs du nom, colonnes first_name et dob, comme suit. Le diagramme montre comment les index organisent le stockage des données.

Comment les index organisent le stockage des données, à partir de : MySQL haute performance
Comme vous pouvez le constater, l'index est d'abord trié selon le premier champ Lorsque les noms sont identiques, il est trié selon le troisième champ, qui est la date de naissance. C'est pour cette raison que le « principe le plus à gauche » est appliqué. de l’indice est établi.
1. MySQL n'utilise pas d'index : colonnes non indépendantes
"Colonnes indépendantes" signifie que les colonnes d'index ne peuvent pas être des expressions partie, ni peut-il s'agir du paramètre de la fonction . Par exemple :
Code MySQL
sélectionner * d'où id + 1 = 5
us Il est facile de voir que cela équivaut à id = 4, mais MySQL ne peut pas analyser automatiquement cette expression L'utilisation de la fonction est la même raison.
2. Index de préfixe
Si la colonne est très longue, vous pouvez généralement indexer certains caractères au début, ce qui peut efficacement économiser de l'espace d'indexation et améliorer l'indexation. efficacité.
3. Index multi-colonnes et ordre des index
Dans la plupart des cas, l'établissement d'index indépendants sur plusieurs colonnes n'améliore pas les performances des requêtes. La raison est très simple. MySQL ne sait pas quel index choisir pour une meilleure efficacité des requêtes, donc dans les anciennes versions, comme avant MySQL 5.0, il sélectionnait aléatoirement un index pour une colonne, tandis que les nouvelles versions adopteraient une stratégie d'index fusionné. Pour donner un exemple simple, dans une liste de distribution de film, des index indépendants sont établis sur les colonnes Actor_id et film_id, puis il y a la requête suivante :
Code MySQL
sélectionnez film_id,actor_id depuis film_actor où acteur_id = 1 ou film_id = 1
L'ancienne version de MySQL sélectionnera un index au hasard, mais la nouvelle version le fait. optimisation suivante :
Code MySQL
sélectionnez film_id,actor_id de film_actor où acteur_id = 1
union tous
sélectionnez film_id,actor_id de film_actor où film_id = 1 et Actor_id <> 1
Lorsque plusieurs index se croisent (plusieurs conditions ET), de manière générale, un index contenant toutes les colonnes liées est meilleur que plusieurs index indépendants.
Lorsque plusieurs index sont utilisés pour des opérations conjointes (plusieurs conditions OU), des opérations telles que la fusion et le tri de l'ensemble de résultats nécessitent une grande quantité de ressources CPU et mémoire, en particulier lorsque certains index sont peu sélectif, et lorsqu'une grande quantité de données doit être renvoyée et fusionnée, le coût de la requête est plus élevé. Dans ce cas, il est préférable d’effectuer une analyse complète de la table.
Par conséquent, si vous constatez qu'il y a une fusion d'index (L'utilisation de l'union apparaît dans le champ Extra) lors de l'explication, vous devez vérifier si la structure de la requête et de la table n'est déjà optimale. la requête ni la table ne posent problème, cela montre seulement que l'index est très mal construit et vous devez soigneusement déterminer si l'index est adapté. Il est possible qu'un index multi-colonnes contenant toutes les colonnes pertinentes soit plus approprié.
Nous avons mentionné plus tôt comment les index organisent le stockage des données. Comme vous pouvez le voir sur la figure, lorsqu'un index multi-colonnes est utilisé, l'ordre de l'index est crucial pour la requête. Il est évident que cela devrait être le cas. Les champs les plus sélectifs sont placés au début de l'index, de sorte que la plupart des données qui ne remplissent pas les conditions puissent être filtrées à travers le premier champ.
Citation
La sélectivité de l'index fait référence au rapport entre les valeurs d'index uniques et le nombre total d'enregistrements dans la table de données. Plus la sélectivité est élevée, plus l'efficacité de la requête est élevée, car plus la sélectivité de l'index est élevée, plus il est sélectif. index peut permettre à MySQL de filtrer plus de données lors de l'interrogation OK. La sélectivité de l'index unique est de 1. À l'heure actuelle, la sélectivité de l'index est la meilleure et les performances sont les meilleures.
Après avoir compris le concept de sélectivité de l'index, il n'est pas difficile de déterminer quel champ a une sélectivité plus élevée. Vous le saurez simplement en vérifiant, par exemple :
Code MySQL- SELECT * FROM paiement où staff_id = 2 et customer_id = 584
- sélectionnez
count(distinct staff_id)/count(*) comme staff_id_selectivity,
- count(distinct customer_id)/count(*) as customer_id_selectivity,
- count(*) à partir du paiement
- sélectionnez user_id du commerce où user_group_id = 1 et trade_amount > 0
- sélectionnez l'utilisateur.* de l'utilisateur où login_time > '2017-04-01' et âge entre 18 et 30 ; >
Il y a un problème avec cette requête : elle a deux conditions de plage, la colonne login_time et la colonne age MySQL peut utiliser l'index de la colonne login_time ou l'index. de la colonne âge, mais ne peuvent pas les utiliser en même temps.
5. Index de couverture
Si un index contient ou couvre les valeurs de tous les champs qui doivent être interrogés, alors il n'est pas nécessaire de revenir en arrière. à la table à interroger. C'est ce qu'on appelle l'index de couverture. Les index de couverture sont des outils très utiles et peuvent grandement améliorer les performances, car les requêtes n'ont besoin que d'analyser l'index, ce qui apporte de nombreux avantages : Obtenez l'index, ce qui réduit considérablement la quantité d'accès aux données
- Le L'index est stocké dans l'ordre des valeurs de colonne. Pour les requêtes de plage gourmandes en E/S, il est préférable de lire aléatoirement chaque ligne de données du disque. Les E/S sont bien moindres
- . 6. Utiliser l'analyse d'index pour trier
MySQL a deux façons de produire des ensembles de résultats ordonnés. La première consiste à associer l'ensemble de résultats. La seconde consiste à effectuer l'opération de tri en fonction de l'ordre de l'index. sont naturellement ordonnés. Si la valeur de la colonne type dans le résultat d'explication est index, cela signifie qu'une analyse d'index est utilisée pour le tri.
L'analyse de l'index lui-même est rapide car il vous suffit de passer d'un enregistrement d'index à l'enregistrement adjacent suivant. Mais si l'index lui-même ne peut pas couvrir toutes les colonnes qui doivent être interrogées, vous devez alors revenir à la table pour interroger la ligne correspondante à chaque fois que vous analysez un enregistrement d'index. Cette opération de lecture est essentiellement une E/S aléatoire, donc la lecture des données dans l'ordre d'index est généralement plus lente qu'une analyse séquentielle de table complète.
Lors de la conception d'un index, il est préférable qu'un index puisse satisfaire à la fois le tri et l'interrogation.
Seulement lorsque l'ordre des colonnes de l'index est complètement cohérent avec l'ordre de la clause ORDER BY et que le sens de tri de toutes les colonnes est également le même, l'index peut être utilisé pour trier les résultats. Si la requête doit associer plusieurs tables, l'index ne peut être utilisé pour le tri que si tous les champs référencés par la clause ORDER BY proviennent de la première table. Les restrictions de la clause ORDER BY et de la requête sont les mêmes et elles doivent répondre aux exigences du préfixe le plus à gauche (il existe une exception, c'est-à-dire que la colonne la plus à gauche est spécifiée comme constante. Voici un exemple simple). Dans d'autres cas, il doit être exécuté des opérations de tri et le tri par index ne peut pas être utilisé.
Code MySQL
// La colonne la plus à gauche est une constante, index : (date, staff_id, customer_id)
sélectionnez staff_id,customer_id de la démo où date = '2015-06-01' commande par staff_id,customer_id
Index redondants et en double
Les index redondants font référence aux index du même type créés sur les mêmes colonnes dans le même ordre. De tels index doivent être évités autant que possible et supprimés immédiatement après leur découverte. Par exemple, s'il existe un index (A, B), alors la création d'un index (A) est un index redondant. Des index redondants se produisent souvent lors de l'ajout de nouveaux index à une table. Par exemple, quelqu'un crée un nouvel index (A, B), mais cet index n'étend pas l'index existant (A).
Dans la plupart des cas, vous devriez essayer d'étendre les index existants plutôt que d'en créer de nouveaux. Cependant, il existe de rares cas où des considérations de performances nécessitent des index redondants, par exemple l'extension d'un index existant de sorte qu'il devienne trop volumineux, affectant ainsi d'autres requêtes qui utilisent l'index.
8. Supprimer les index qui n'ont pas été utilisés depuis longtemps
C'est une très bonne habitude de supprimer régulièrement certains index qui n'ont pas été utilisés depuis longtemps temps.
Je vais m'arrêter ici sur le sujet de l'indexation. Enfin, je tiens à dire que l'indexation n'est pas toujours le meilleur outil. Seulement lorsque l'index contribue à améliorer la vitesse des requêtes. les avantages l'emportent sur ses conséquences. Les index ne sont efficaces que s'ils nécessitent un travail supplémentaire. Pour les très petites tables, une simple analyse complète de la table est plus efficace. Pour les tables moyennes à grandes, les index sont très efficaces. Pour les très grandes tables, le coût de création et de maintenance des index augmente et d'autres techniques peuvent s'avérer plus efficaces, telles que les tables partitionnées. Enfin, c'est une vertu à expliquer avant de passer le test.
Optimisation des requêtes de type spécifique
Optimisation de la requête COUNT()
COUNT() est peut-être la fonction la plus mal comprise. Elle a deux types de fonctions différentes, l'une consiste à compter le nombre de valeurs dans une certaine colonne et l'autre à compter le nombre de lignes. Lors du comptage des valeurs de colonne, la valeur de la colonne doit être non nulle et NULL ne sera pas compté. Si vous confirmez que l’expression entre parenthèses ne peut pas être vide, vous comptez en réalité le nombre de lignes. Le plus simple est que lors de l'utilisation de COUNT(*), il ne s'étend pas à toutes les colonnes comme nous l'imaginions. En fait, il ignore toutes les colonnes et compte directement toutes les lignes.
C'est notre malentendu le plus courant. Nous spécifions une colonne entre parenthèses mais nous attendons à ce que le résultat statistique soit le nombre de lignes. Nous croyons aussi souvent à tort que la performance de la première sera. mieux. Mais ce n'est pas réellement le cas. Si vous souhaitez compter le nombre de lignes, utilisez directement COUNT(*), ce qui a une signification claire et de meilleures performances.
Parfois, certains scénarios commerciaux ne nécessitent pas une valeur COUNT complètement précise et peuvent être remplacés par une valeur approximative. Le nombre de lignes obtenu par EXPLAIN est une bonne approximation, et il n'est pas obligatoire. pour exécuter EXPLAIN. Exécutez réellement la requête, le coût est donc très faible. D'une manière générale, l'exécution de COUNT() nécessite d'analyser un grand nombre de lignes pour obtenir des données précises, il est donc difficile à optimiser. La seule chose qui peut être faite au niveau MySQL est de couvrir l'index. Si le problème ne peut pas être résolu, il ne peut être résolu qu'au niveau architectural, par exemple en ajoutant un tableau récapitulatif ou en utilisant un système de cache externe comme redis.
Optimisez les requêtes associées
Dans les scénarios Big Data, les tables sont liées via un champ redondant, qui offre de meilleures performances que l'utilisation directe de JOIN. Si vous avez vraiment besoin d'utiliser des requêtes associées, vous devez accorder une attention particulière à :
Assurez-vous qu'il y a des index sur les colonnes dans les clauses ON et USING. L'ordre des associations doit être pris en compte lors de la création d'un index. Lorsque la table A et la table B sont associées à l'aide de la colonne c, si l'ordre d'association de l'optimiseur est A, B, alors il n'est pas nécessaire de créer un index sur la colonne correspondante de la table A. Les index inutilisés entraîneront une charge supplémentaire. De manière générale, sauf autres raisons, il vous suffit de créer un index sur la colonne correspondante de la deuxième table de la séquence d'association (les raisons spécifiques sont analysées ci-dessous).
Assurez-vous que toutes les expressions dans GROUP BY et ORDER BY n'impliquent que des colonnes dans une seule table, afin que MySQL puisse utiliser des index pour l'optimisation.
Pour comprendre le premier conseil d'optimisation des requêtes associées, vous devez comprendre comment MySQL exécute les requêtes associées. La stratégie actuelle d'exécution des associations MySQL est très simple. Elle effectue des opérations d'association de boucles imbriquées pour n'importe quelle association, c'est-à-dire qu'elle boucle d'abord une seule donnée dans une table, puis recherche les lignes correspondantes dans la table suivante dans la boucle imbriquée. , et ainsi de suite, jusqu'à ce que le comportement correspondant soit trouvé dans toutes les tables. Ensuite, en fonction des lignes correspondantes de chaque table, les colonnes requises dans la requête sont renvoyées.
Trop abstrait ? Prenons l'exemple ci-dessus pour illustrer, par exemple, il existe une telle requête :
Code MySQL
SELECT A.xx,B.yy
D'UN BUS INNER JOIN EN UTILISANT(c)
WHERE A.xx IN (5,6)
En supposant que MySQL effectue des opérations d'association selon l'ordre d'association A et B dans la requête, alors le pseudo-code suivant peut être utilisé pour représenter comment MySQL termine cette requête :
Code MySQL
-
outer_iterator = SELECT A.xx,A.c FROM A WHERE A.xx IN (5,6);
outer_row = external_iterator.suivant; ;
while(outer_row) {
inner_iterator = SELECT B.yy FROM B WHERE B.c = external_row.c;
inner_row = inner_iterator.next;
while(inner_row) {
sortie[inner_row.yy ,outer_row.xx];
inner_row = inner_iterator.next;
} er_row = external_iterator.next; 🎜>
- }
- Comme vous pouvez le voir, la requête la plus externe est basée sur la colonne A.xx utilisée pour interroger. S'il existe un index sur A.c, l'intégralité de la requête associée ne sera pas utilisée. En regardant la requête interne, il est évident que s'il y a un index sur B.c, la requête peut être accélérée, il suffit donc de créer un index sur la colonne correspondante de la deuxième table dans la séquence d'association.
002
0 enregistrements, puis Seuls 20 enregistrements sont renvoyés et les 10 000 premiers enregistrements seront supprimés. Ce coût est très élevé. Code MySQL SELECT film_id,description FROM film ORDER BY title LIMIT 50,5; > Si cette table est très grande, il est préférable de modifier cette requête comme suit :- Code MySQL
- SELECT film_id FROM film ORDER BY title LIMITE 50,5
- ) AS tmp USING(film_id);
- L'association retardée ici améliorera considérablement l'efficacité des requêtes, permettant à MySQL d'analyser le moins de pages possible, Après avoir obtenu les enregistrements auxquels il faut accéder, remettez les colonnes requises dans la table d'origine en fonction des colonnes associées.
- Parfois, si vous pouvez utiliser un signet pour enregistrer l'emplacement où les données ont été récupérées pour la dernière fois, vous pouvez alors commencer à numériser directement à partir de l'emplacement enregistré par le signet la prochaine fois, afin d'éviter en utilisant OFF SET
D'autres méthodes d'optimisation incluent l'utilisation de tableaux récapitulatifs pré-calculés ou la création d'un lien vers une table redondante qui contient uniquement les colonnes de clé primaire et les colonnes qui doivent être triées.
Optimisation de UNION
La stratégie de MySQL pour le traitement de UNION consiste à d'abord créer une table temporaire, puis à insérer chaque résultat de requête dans la table temporaire et enfin à exécuter la requête. Par conséquent, de nombreuses stratégies d'optimisation ne fonctionnent pas bien dans la requête UNION. Il est souvent nécessaire d'insérer manuellement les clauses WHERE, LIMIT, ORDER BY et d'autres dans chaque sous-requête afin que l'optimiseur puisse utiliser pleinement ces conditions pour optimiser en premier.
À moins que vous n'ayez vraiment besoin que le serveur effectue une déduplication, vous devez utiliser UNION ALL S'il n'y a pas de mot-clé ALL, MySQL ajoutera l'option DISTINCT à la table temporaire, ce qui provoquera l'intégralité. table temporaire à dédupliquer. L'unicité des données est vérifiée, ce qui coûte très cher. Bien entendu, même si le mot-clé ALL est utilisé, MySQL place toujours les résultats dans une table temporaire, puis les lit, puis les renvoie au client. Bien que cela ne soit pas nécessaire dans de nombreux cas, par exemple, les résultats de chaque sous-requête peuvent parfois être renvoyés directement au client.
Conclusion
Comprendre comment les requêtes sont exécutées et où le temps est passé, associé à une certaine connaissance du processus d'optimisation, peut aider tout le monde à mieux comprendre MySQL. techniques d'optimisation courantes. J'espère que les principes et les exemples de cet article pourront vous aider à mieux relier la théorie et la pratique et à appliquer davantage de connaissances théoriques dans la pratique.
Il n'y a pas grand chose d'autre à dire. Je vais vous laisser avec deux questions auxquelles réfléchir. Vous pouvez penser aux réponses dans votre tête. C'est quelque chose dont tout le monde parle souvent. mais rarement. Quelqu'un se demande pourquoi ?
De nombreux programmeurs partageront ce point de vue : essayez de ne pas utiliser des procédures stockées Les procédures stockées sont très difficiles à maintenir et augmenteront les coûts d'utilisation, la logique métier. doit être placé du côté client. Puisque le client peut faire ces choses, pourquoi avons-nous besoin de procédures stockées ?
JOIN lui-même est également très pratique. Il suffit de l'interroger directement. Pourquoi avez-vous besoin d'une vue ?
Références
[1] Écrit par Jiang Chengyao ; MySQL Technology Insider-InnoDB Storage Engine Machinery Industry Press ; , 2013
[2] Baron Scbwartz et al. Traduit par Ninghai Yuanzhou Zhenxing et autres ; MySQL haute performance (troisième édition)
[3] Afficher l'index MySQL à partir de la structure arborescente B-/B+ ;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!