
Maison >développement back-end >tutoriel php >Explication détaillée des tables de hachage en PHP
Explication détaillée des tables de hachage en PHP
- 巴扎黑original
- 2017-05-27 10:38:083943parcourir
Dans le noyau PHP, l'une des structures de données très importantes est HashTable. Les tableaux que nous utilisons couramment sont implémentés dans le noyau à l'aide de HashTable. Alors, comment HashTable de PHP est-il implémenté ? J'ai récemment lu la structure de données de HashTable, mais il n'y a pas d'algorithme d'implémentation spécifique dans les livres d'algorithmes. J'ai récemment lu le code source de PHP, j'en ai donc implémenté un en me référant à. l'implémentation de HashTable de PHP. La version simple de HashTable résume quelques expériences et sera partagée avec vous ci-dessous.
L'auteur a une version simple de l'implémentation de HashTable sur github : Implémentation de HashTable
De plus, j'ai une version plus détaillée du PHP code source sur l'annotation github. Si vous êtes intéressé, vous pouvez y jeter un œil et lui attribuer une étoile. Annotations du code source PHP5.4. Vous pouvez afficher les annotations ajoutées via l'enregistrement de validation.
Introduction à HashTable
La table de hachage est une structure de données efficace qui implémente des opérations de dictionnaire.
Définition
En termes simples, HashTable (table de hachage) est une structure de données de paires clé-valeur. Prend en charge les opérations telles que l'insertion, la recherche et la suppression. Sous certaines hypothèses raisonnables, la complexité temporelle de toutes les opérations dans la table de hachage est O(1) (ceux qui sont intéressés par la preuve pertinente peuvent la vérifier par eux-mêmes).
La clé pour implémenter une table de hachage
Dans une table de hachage, au lieu d'utiliser des mots-clés comme indices, vous utilisez des fonctions de hachage Calculer le hachage valeur de la clé en indice, puis calculez la valeur de hachage de la clé lors de la recherche/suppression, afin de localiser rapidement l'emplacement où l'élément est enregistré.
Dans une table de hachage, différentes clés peuvent calculer la même valeur de hachage. C'est ce qu'on appelle une « collision de hachage », qui consiste à traiter deux ou plusieurs clés de hachage. sont les mêmes. Il existe de nombreuses façons de résoudre les conflits de hachage, telles que l'adressage ouvert, la fermeture éclair, etc.
Par conséquent, la clé pour implémenter une bonne table de hachage est une bonne fonction de hachage et une méthode de gestion des conflits de hachage.
Fonction de hachage
Il existe quatre définitions pour juger de la qualité d'un algorithme de hachage : > valeurs > * Efficace et facile à calculer ; Uniformité, hache toutes les clés de manière uniforme.
La fonction de hachage établit la relation correspondante entre la valeur clé et la valeur de hachage, c'est-à-dire : h = hash_func(key). La relation correspondante est illustrée dans la figure ci-dessous :

Laissons aux experts le soin de concevoir une fonction de hachage parfaite . Utilisez simplement une fonction de hachage existante plus mature. La fonction de hachage utilisée par le noyau PHP est la fonction time33, également appelée DJBX33A. Son implémentation est la suivante :
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength)
{
register ulong hash = 5381;
/* variant with the hash unrolled eight times */
for (; nKeyLength >= 8; nKeyLength -= 8) {
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
}
switch (nKeyLength) {
case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 1: hash = ((hash << 5) + hash) + *arKey++; break;
case 0: break;
EMPTY_SWITCH_DEFAULT_CASE()
}
return hash;
}
. Remarque : Utilisation de la fonction Une boucle + commutateur 8 fois est implémentée pour optimiser la boucle for, réduire le nombre d'exécutions de boucle, puis exécuter les éléments restants qui n'ont pas été traversés dans le commutateur.
Méthode Zipper
La méthode de sauvegarde de tous les éléments avec la même valeur de hachage dans une liste chaînée est appelée la méthode Zipper. Lors de la recherche, calculez d'abord la valeur de hachage correspondant à la clé, puis recherchez la liste chaînée correspondante en fonction de la valeur de hachage, et enfin recherchez la valeur correspondante séquentiellement le long de la liste chaînée. Le diagramme de structure spécifique enregistré est le suivant :
Structure HashTable de PHP
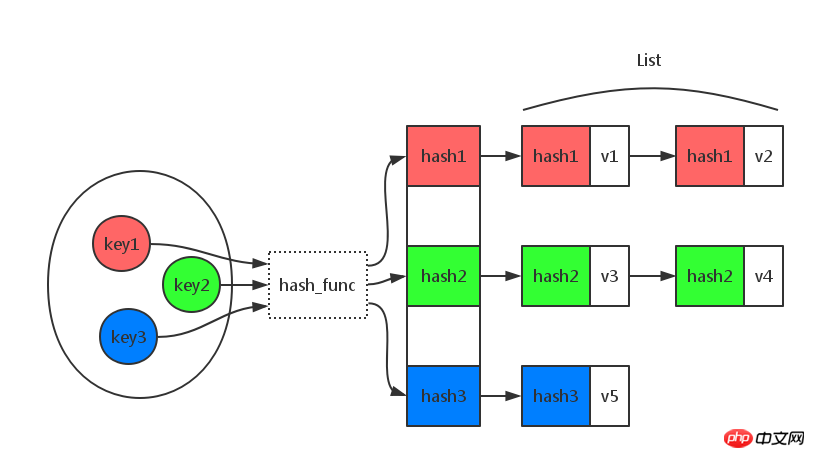
Après avoir brièvement présenté la structure des données de la table de hachage, continuez à examiner comment la table de hachage est implémentée en PHP.
(Les photos proviennent d'Internet, toute infraction sera supprimée)
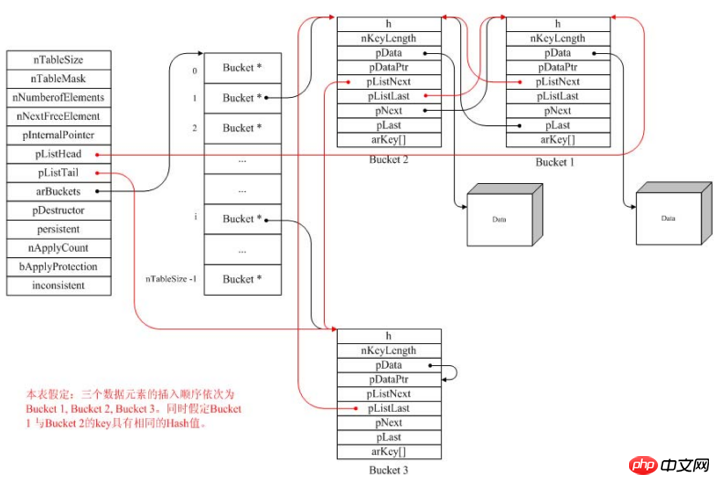
Définition de la table de hachage du noyau PHP :
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer;
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets;
dtor_func_t pDestructor;
zend_bool persistent;
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;nTableSize, la taille du HashTable, augmente d'un multiple de 2
nTableMask, utilisé pour effectuer une opération AND avec la valeur de hachage pour obtenir l'index valeur de la valeur de hachage, arBuckets Après initialisation, ce sera toujours nTableSize-1
nNumOfElements, le nombre d'éléments actuellement détenus par HashTable. La fonction count renvoie directement cette valeur
nNextFreeElement, ce qui signifie La position du prochain index numérique dans le tableau de valeurs de clé numérique
pInternalPointer, pointeur interne, pointant vers le membre actuel, utilisé pour parcourir les éléments
pListHead, Pointe vers le premier élément de la HashTable et le premier élément du tableau
pListTail,指向HashTable的最后一个元素,也是数组的最后一个元素。与上面的指针结合,在遍历数组时非常方便,比如reset和endAPI
arBuckets,包含bucket组成的双向链表的数组,索引用key的哈希值和nTableMask做与运算生成
pDestructor,删除哈希表中的元素使用的析构函数
persistent,标识内存分配函数,如果是TRUE,则使用操作系统本身的内存分配函数,否则使用PHP的内存分配函数
nApplyCount,保存当前bucket被递归访问的次数,防止多次递归
bApplyProtection,标识哈希表是否要使用递归保护,默认是1,要使用
举一个哈希与mask结合的例子:
例如,”foo”真正的哈希值(使用DJBX33A哈希函数)是193491849。如果我们现在有64容量的哈希表,我们明显不能使用它作为数组的下标。取而代之的是通过应用哈希表的mask,然后只取哈希表的低位。
hash | 193491849 | 0b1011100010000111001110001001 & mask | & 63 | & 0b0000000000000000000000111111 ---------------------------------------------------------------------- = index | = 9 | = 0b0000000000000000000000001001
因此,在哈希表中,foo是保存在arBuckets中下标为9的bucket向量中。
bucket结构体的定义
typedef struct bucket {
ulong h;
uint nKeyLength;
void *pData;
void *pDataPtr;
struct bucket *pListNext;
struct bucket *pListLast;
struct bucket *pNext;
struct bucket *pLast;
const char *arKey;
} Bucket;h,哈希值(或数字键值的key
nKeyLength,key的长度
pData,指向数据的指针
pDataPtr,指针数据
pListNext,指向HashTable中的arBuckets链表中的下一个元素
pListLast,指向HashTable中的arBuckets链表中的上一个元素
pNext,指向具有相同hash值的bucket链表中的下一个元素
pLast,指向具有相同hash值的bucket链表中的上一个元素
arKey,key的名称
PHP中的HashTable是采用了向量加双向链表的实现方式,向量在arBuckets变量保存,向量包含多个bucket的指针,每个指针指向由多个bucket组成的双向链表,新元素的加入使用前插法,即新元素总是在bucket的第一个位置。由上面可以看到,PHP的哈希表实现相当复杂。这是它使用超灵活的数组类型要付出的代价。
一个PHP中的HashTable的示例图如下所示:
HashTable相关API
zend_hash_init
zend_hash_add_or_update
zend_hash_find
zend_hash_del_key_or_index
zend_hash_init
函数执行步骤
设置哈希表大小
设置结构体其他成员变量的初始值 (包括释放内存用的析构函数pDescructor)
详细代码注解点击:zend_hash_init源码
注:
1、pHashFunction在此处并没有用到,php的哈希函数使用的是内部的zend_inline_hash_func
2、zend_hash_init执行之后并没有真正地为arBuckets分配内存和计算出nTableMask的大小,真正分配内存和计算nTableMask是在插入元素时进行CHECK_INIT检查初始化时进行。
zend_hash_add_or_update
函数执行步骤
检查键的长度
检查初始化
计算哈希值和下标
遍历哈希值所在的bucket,如果找到相同的key且值需要更新,则更新数据,否则继续指向bucket的下一个元素,直到指向bucket的最后一个位置
为新加入的元素分配bucket,设置新的bucket的属性值,然后添加到哈希表中
如果哈希表空间满了,则重新调整哈希表的大小
函数执行流程图
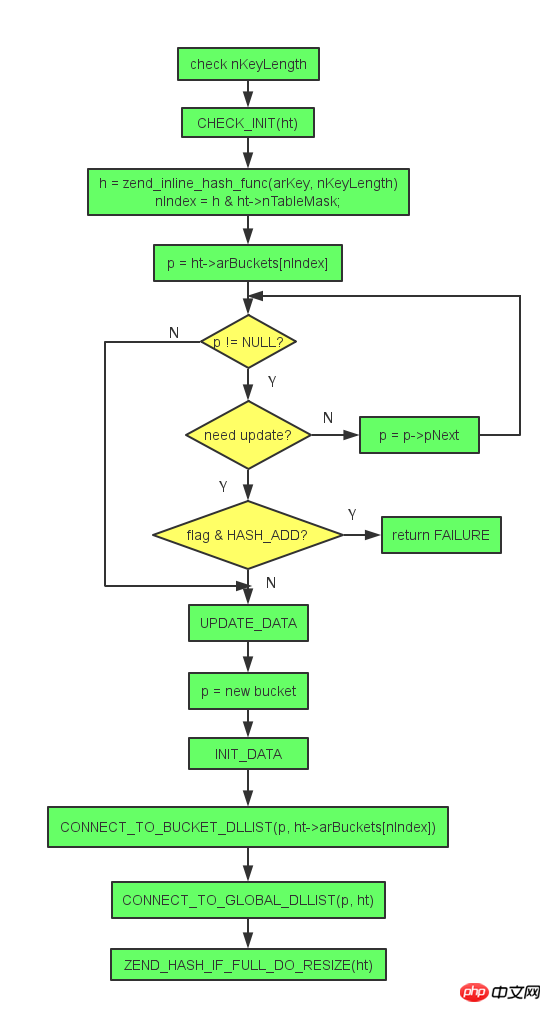
CONNECT_TO_BUCKET_DLLIST是将新元素添加到具有相同hash值的bucket链表。
CONNECT_TO_GLOBAL_DLLIST是将新元素添加到HashTable的双向链表。
详细代码和注解请点击:zend_hash_add_or_update代码注解。
zend_hash_find
函数执行步骤
计算哈希值和下标
遍历哈希值所在的bucket,如果找到key所在的bucket,则返回值,否则,指向下一个bucket,直到指向bucket链表中的最后一个位置
详细代码和注解请点击:zend_hash_find代码注解。
zend_hash_del_key_or_index
函数执行步骤
计算key的哈希值和下标
遍历哈希值所在的bucket,如果找到key所在的bucket,则进行第三步,否则,指向下一个bucket,直到指向bucket链表中的最后一个位置
如果要删除的是第一个元素,直接将arBucket[nIndex]指向第二个元素;其余的操作是将当前指针的last的next执行当前的next
调整相关指针
释放数据内存和bucket结构体内存
详细代码和注解请点击:zend_hash_del_key_or_index代码注解。
性能分析
PHP的哈希表的优点:PHP的HashTable为数组的操作提供了很大的方便,无论是数组的创建和新增元素或删除元素等操作,哈希表都提供了很好的性能,但其不足在数据量大的时候比较明显,从时间复杂度和空间复杂度看看其不足。
不足如下:
保存数据的结构体zval需要单独分配内存,需要管理这个额外的内存,每个zval占用了16bytes的内存;
在新增bucket时,bucket也是额外分配,也需要16bytes的内存;
为了能进行顺序遍历,使用双向链表连接整个HashTable,多出了很多的指针,每个指针也要16bytes的内存;
在遍历时,如果元素位于bucket链表的尾部,也需要遍历完整个bucket链表才能找到所要查找的值
PHP的HashTable的不足主要是其双向链表多出的指针及zval和bucket需要额外分配内存,因此导致占用了很多内存空间及查找时多出了不少时间的消耗。
后续
上面提到的不足,在PHP7中都很好地解决了,PHP7对内核中的数据结构做了一个大改造,使得PHP的效率高了很多,因此,推荐PHP开发者都将开发和部署版本更新吧。看看下面这段PHP代码:
<?php
$size = pow(2, 16);
$startTime = microtime(true);
$array = array();
for ($key = 0, $maxKey = ($size - 1) * $size; $key <= $maxKey; $key += $size) {
$array[$key] = 0;
}
$endTime = microtime(true);
echo '插入 ', $size, ' 个恶意的元素需要 ', $endTime - $startTime, ' 秒', "\n";
$startTime = microtime(true);
$array = array();
for ($key = 0, $maxKey = $size - 1; $key <= $maxKey; ++$key) {
$array[$key] = 0;
}
$endTime = microtime(true);
echo '插入 ', $size, ' 个普通元素需要 ', $endTime - $startTime, ' 秒', "\n";上面这个demo是有多个hash冲突时和无冲突时的时间消耗比较。笔者在PHP5.4下运行这段代码,结果如下
插入 65536 个恶意的元素需要 43.72204709053 秒
插入 65536 个普通元素需要 0.009843111038208 秒
而在PHP7上运行的结果:
插入 65536 个恶意的元素需要 4.4028408527374 秒
插入 65536 个普通元素需要 0.0018510818481445 秒
可见不论在有冲突和无冲突的数组操作,PHP7的性能都提升了不少,当然,有冲突的性能提升更为明显。至于为什么PHP7的性能提高了这么多,值得继续深究。
最后,笔者github上有一个简易版的HashTable的实现:HashTable实现
另外,我在github有对PHP源码更详细的注解。感兴趣的可以围观一下,给个star。PHP5.4源码注解。可以通过commit记录查看已添加的注解。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)