
Maison >base de données >tutoriel mysql >Comment trouver des instructions SQL lentes dans MySQL
Comment trouver des instructions SQL lentes dans MySQL

- 黄舟original
- 2017-05-21 09:15:101270parcourir
Cet article présente principalement la méthode pour trouver des instructions SQL lentes dans une requête dans MySQL Les amis dans le besoin peuvent se référer à
Comment trouver des instructions SQL lentes dans. mysql Qu'en est-il des instructions SQL ? Cela peut être un problème pour de nombreuses personnes. MySQL utilise des journaux de requêtes lents pour localiser les instructions SQL avec une faible efficacité d'exécution. Lors du démarrage avec l'option --log-slow-queries[=file_name], mysqld Un journal. Un fichier contenant toutes les instructions SQL dont le temps d'exécution dépasse long_query_time secondes sera écrit, et le SQL moins efficace peut être localisé en affichant ce fichier journal. Ce qui suit décrit comment interroger des instructions SQL lentes dans MySQL
1. La base de données MySQL dispose de plusieurs options de configuration qui peuvent nous aider à capturer des instructions SQL inefficaces à temps
1, slow_query_log
Ce paramètre est défini sur ON, ce qui peut capturer les instructions SQL dont le temps d'exécution dépasse une certaine valeur.
2, long_query_time
Lorsque le temps d'exécution de l'instruction SQL dépasse cette valeur, il sera enregistré dans le journal. Il est recommandé de le définir sur 1 ou moins.
3, slow_query_log_file
Le nom du fichier du journal.
4, log_queries_not_using_indexes
Ce paramètre est défini sur ON, ce qui peut capturer toutes les instructions SQL qui n'utilisent pas de index, bien que cette instruction SQL puisse s'exécuter très rapidement.
2. Méthodes pour détecter l'efficacité des instructions SQL dans MySQL
1 Grâce aux journaux de requêtes
(1), activez les requêtes lentes MySQL sous. Windows
Le fichier de configuration de MySQL dans le système Windows se trouve généralement dans my.ini [mysqld] et le
code est le suivant
log-slow -queries=F:/MySQL/log/mysqlslowquery. log
long_query_time = 2
(2), Activer la requête lente MySQL sous Linux
Le fichier de configuration de MySQL dans le système Windows se trouve généralement dans my.cnf [mysqld] Ajoutez
ci-dessous et le code est le suivant
log-slow-queries=/data/mysqldata/slowquery. log
long_query_time=2
Explication
log-slow-queries = F:/MySQL/log/mysqlslowquery.
est l'emplacement où le journal des requêtes lentes est stocké. Généralement, ce répertoire doit avoir des autorisations d'écriture pour le compte MySQL en cours d'exécution. Ce répertoire est généralement défini comme répertoire de stockage de données MySQL ; 2 Indique que la requête ne sera enregistrée que lorsque cela prendra plus de deux secondes ;
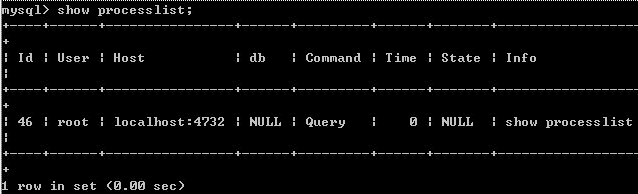
list commande
WSHOW PROCESSLIST affiche quels threads sont en cours d'exécution. Vous pouvez égalementutiliser l'instruction mysql admin processlist pour obtenir ces informations.
La signification et le but de chaque colonne :
Colonne ID Un identifiant C'est très utile lorsque vous souhaitez tuer une instruction. la commande pour le tuer. Cette requête /*/mysqladmin tue le numéro de processus. La colonne Utilisateur affiche l'utilisateur précédent. Si vous n'êtes pas root, cette commande affichera uniquement les instructions SQL relevant de votre autorité. Colonne Hôte indique quelle adresse IP et quel port cette déclaration est envoyée. Utilisé pour suivre l'utilisateur qui a émis la déclaration problématique. colonne db indique à quelle base de données ce processus est actuellement connecté. colonne de commande affiche la commande exécutée de la connexion actuelle, généralement dormir,requête et se connecter.
colonne tempsLa durée de cetétat, en secondes.
colonne d'état affiche l'état de l'instruction SQL utilisant la connexion actuelle. C'est une colonne très importante. Toutes les descriptions d'état seront décrites plus tard. Veuillez noter que l'état n'est qu'un certain état. lors de l'exécution de l'instruction. , une instruction SQL, prenant la requête comme exemple, peut devoir passer parcopiedans la table tmp, trirésultat, Sfin. ing des données et d'autres états avant qu'ils puissent être complétés.
la colonne d'informations affiche cette instruction SQL. Parce que la longueur est limitée, les instructions SQL longues ne sont pas entièrement affichées, mais elles le sont. une base importante pour juger les énoncés de problèmes.La chose la plus critique dans cette commande est la colonne d'état. Les états répertoriés par MySQL incluent principalement les éléments suivants :
Vérification du tableau
vérifie le tableau de données (c'est automatique).
Fermeture des tables
Les données modifiées dans la table sont vidées sur le disque et les tables qui ont été utilisées sont fermées. C'est une opération rapide, mais si ce n'est pas le cas, vous devez vérifier que l'espace disque est plein ou que le disque est sous forte charge.
Connect Out
Le serveur esclave de réplication se connecte au serveur maître.
Copie vers une table tmp sur le disque
Étant donné que l'ensemble de résultats temporaires est plus grand que tmp_table_size, la table temporaire est convertie du stockage mémoire en stockage disque pour économiser de la mémoire.
Création d'une table tmp
Une table temporaire est en cours de création pour stocker certains résultats de requête.
suppression de la table principale
Le serveur exécute la première partie de la suppression multi-tables, et la première table vient d'être supprimée.
suppression des tables de référence
Le serveur effectue la deuxième partie de la suppression multi-tables et supprime les enregistrements des autres tables.
Flushing tables
Exécution de FLUSH TABLES, en attendant que d'autres threads ferment la table de données.
Tué
Si une demande de mise à mort est envoyée à un thread, le fil vérifiera l'indicateur de mise à mort et abandonnera la prochaine demande de mise à mort. MySQL vérifiera l'indicateur kill dans chaque boucle principale , mais dans certains cas, le thread peut mourir après une courte période de temps. Si le thread est verrouillé par un autre thread, la demande d'arrêt prendra effet immédiatement lorsque le verrou sera libéré.
Locked
est verrouillé par d'autres requêtes. L'
Envoi de données
consiste à traiter les enregistrements de la requête SELECT et à envoyer les résultats au client.
Tri pour groupe
consiste à trier GROUP BY.
Le tri pour order
consiste à trier ORDER BY.
Ouverture des tables
Ce processus doit être rapide à moins qu'il ne soit perturbé par d'autres facteurs. Par exemple, la table de données ne peut pas être ouverte par d'autres threads avant l'exécution de l'instruction ALTER TABLE ou LOCK TABLE. J'essaie d'ouvrir une table.
Suppression des doublons
Une requête SELECT DISTINCT est en cours d'exécution, mais MySQL ne peut pas optimiser ces enregistrements en double à l'étape précédente. Par conséquent, MySQL doit à nouveau supprimer les enregistrements en double avant d'envoyer les résultats au client.
Rouvrir la table
Obtention d'un verrou sur une table, mais le verrou doit être obtenu après modification de la structure de la table. Le verrou a été libéré, la table de données a été fermée et une tentative de réouverture de la table de données a été effectuée.
Réparer par tri
La directive de réparation consiste à trier pour créer un index.
Réparer avec clécache
La directive de réparation utilise l'index cache pour créer de nouveaux index un par un. Ce sera plus lent que Réparer par tri.
Rechercher des lignes pour la mise à jourdate
consiste à trouver des enregistrements qui remplissent les conditions de mise à jour. Elle doit être complétée avant que UPDATE puisse modifier les enregistrements associés.
En veille
attend que le client envoie une nouvelle demande
Verrouillage système
attend d'obtenir un verrouillage système externe. Si vous n'exécutez pas actuellement plusieurs serveurs mysqld demandant la même table en même temps, vous pouvez désactiver les verrous système externes en ajoutant le paramètre --skip-external-locking.
Mise à niveau du verrouillage
INSERT DELAYED tente d'obtenir une table de verrouillage pour insérer de nouveaux enregistrements.
Mettre à jour
consiste à rechercher les enregistrements correspondants et à les modifier.
Verrouillage utilisateur
En attente de GET_LOCK().
En attente des tables
Le thread est informé que la structure de la table de données a été modifiée et que la table de données doit être rouverte pour obtenir la nouvelle structure. Ensuite, pour rouvrir la table de données, vous devez attendre que tous les autres threads ferment la table. Cette notification sera générée dans les situations suivantes : FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE ou OPTIMIZE TABLE.
en attente de handler insert
INSERT DELAYED a traité toutes les opérations d'insertion en attente et attend de nouvelles requêtes.
La plupart des états correspondent à des opérations très rapides. Tant qu'un thread reste dans le même état pendant plusieurs secondes, il peut y avoir un problème et il faut le vérifier.
Il existe d'autres statuts non répertoriés ci-dessus, mais la plupart d'entre eux ne sont utiles que pour vérifier s'il y a des erreurs sur le serveur.
Par exemple :
3. Expliquez pour comprendre l'état de l'exécution de SQL
explique comment MySQL utilise les index pour traiter les instructions de sélection et joindre les tables. Peut aider à choisir de meilleurs index et à écrire des instructions de requête plus optimisées.
Pour l'utiliser, ajoutez simplement expliquer avant l'instruction select :
Par exemple :
explain select surname,first_name form a,b where a.id=b.id
Le résultat est comme indiqué ci-dessous

Explication de la colonne EXPLAIN
table
Affiche de quelle table concerne cette ligne de données
type
C'est la colonne importante, indiquant le type utilisé pour la connexion. Les types de jointure, du meilleur au pire, sont const, eq_reg, ref, range, indexhe et ALL
possible_keys
affichant les applications possibles dans Index in ce tableau. S'il est vide, aucun index n'est possible. Une instruction appropriée peut être sélectionnée dans l'instruction WHERE pour le domaine concerné
clé
L'index réel utilisé. Si NULL, aucun index n'est utilisé. Rarement, MYSQL sélectionnera un index sous-optimisé. Dans ce cas, vous pouvez utiliser USE INDEX (nom d'index) dans l'instruction SELECT pour forcer l'utilisation d'un index ou utiliser IGNORE INDEX (nom d'index) pour forcer MYSQL à ignorer l'index utilisé par l'index
key_len
longueur. Plus la longueur est courte mieux c'est sans perdre en précision
ref
Affiche quelle colonne de l'index est utilisée, une constante si possible
lignes
Le nombre de lignes qui, selon MYSQL, doivent être vérifiées pour renvoyer les données demandées
Extra
Informations supplémentaires sur la façon dont MYSQL analyse la requête. Sera discuté dans le tableau 4.3, mais les mauvais exemples que l'on peut voir ici sont l'utilisation de fichiers temporaires et l'utilisation de fichiers, ce qui signifie que MYSQL ne peut pas du tout utiliser l'index, et le résultat est que la récupération sera très lente
Description renvoyée par colonne supplémentaire La signification de
Distinct
Une fois que MYSQL trouve une ligne qui correspond à l'union de lignes, il ne recherche plus
Pas existe
MYSQL optimisé LEFT JOIN, une fois qu'il trouve une ligne correspondant aux critères LEFT JOIN, il ne recherche plus
Plage vérifiée pour chacun Record(index map :#)
Aucun index idéal n'a été trouvé, donc pour chaque combinaison de lignes de la table précédente, MYSQL vérifie quel index a été utilisé et l'utilise pour renvoyer les lignes de le tableau. C'est l'une des connexions les plus lentes utilisant un index
Utilisation du tri de fichiers
Lorsque vous voyez cela, la requête doit être optimisée. MYSQL nécessite une étape supplémentaire pour découvrir comment trier les lignes renvoyées. Il trie toutes les lignes en fonction du type de connexion et des pointeurs de ligne de toutes les lignes qui stockent la valeur de la clé de tri et la condition de correspondance
En utilisant l'index Renvoyé par la table d'action réelle, cela se produit lorsque toutes les colonnes demandées du. table font partie du même index
Utilisation temporaire
Lorsque vous voyez cela, la requête doit être optimisée. Ici, MYSQL doit créer une table temporaire pour stocker les résultats. Cela se produit généralement lorsque ORDER BY est effectué sur différents ensembles de colonnes au lieu de
Where used
utilise la clause WHERE pour. Limitez les lignes qui correspondront au tableau suivant ou qui seront renvoyées à l'utilisateur. Cela se produira si vous ne souhaitez pas renvoyer toutes les lignes de la table et que le type de jointure est ALL ou index, ou s'il y a un problème avec la requête Explication des différents types de jointure (triés par ordre d'efficacité)
<.>constLa valeur maximale d'un enregistrement dans la table pouvant correspondre à cette requête (l'index peut être une clé primaire ou un index unique). Parce qu'il n'y a qu'une seule ligne, cette valeur est en fait une constante, car MYSQL lit d'abord cette valeur puis la traite comme une constante eq_refDans le cadre de la connexion, MYSQL lit la valeur du table précédente lors de l'interrogation, un enregistrement est lu dans la table pour chaque union d'enregistrements. Il est utilisé lors de l'interrogation de tous les index qui utilisent la clé primaire ou la clé unique ref Ce type de connexion est. utilisé uniquement lors d'une requête. Se produit lorsqu'une clé qui n'est pas une clé unique ou primaire est utilisée, ou fait partie de ces types (par exemple, en utilisant un préfixe le plus à gauche). Pour chaque jointure de ligne de la table précédente, tous les enregistrements seront lus à partir de la table. Ce type dépend fortement du nombre d'enregistrements correspondant en fonction de l'index - moins il y en a, mieux c'est plageCe type de jointure utilise l'index pour renvoyer des lignes dans une plage, par exemple en utilisant > ou 66aaddb7c6077de5754715835ce4dfb9 create index idx_sales_year on sales(year);Query OK, 12 rows affected (0.01 sec)
Records: 12 Duplicates: 0 Warnings: 0
创建索引后,这条语句的执行计划如下:
mysql> explain select sum(profit) from sales a,company b where a.company_id = b.id and a.year = 2006\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: a type: ref possible_keys: idx_sales_year key: idx_sales_year key_len: 4 ref: const rows: 3 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: b type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 12 Extra: Using where 2 rows in set (0.00 sec)
可以发现建立索引后对 a 表需要扫描的行数明显减少(从全表扫描减少到 3 行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显,使用索引优化 sql 是优化问题 sql 的一种常用基本方法,在后面的章节中我们会具体介绍如何使索引来优化 sql 。
本文主要介绍的是MySQL慢查询分析方法,前一段日子,我曾经设置了一次记录在MySQL数据库中对慢于1秒钟的SQL语句进行查询。想起来有几个十分设置的方法,有几个参数的名称死活回忆不起来了,于是重新整理一下,自己做个笔记。
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MySQL慢查询以及没有得用索引的查询。
OK,开始找出MySQL中执行起来不“爽”的SQL语句吧。
MySQL慢查询分析方法一:
这个方法我正在用,呵呵,比较喜欢这种即时性的。
MySQL5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
MySQL> show variables like 'long%';
注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) MySQL> set long_query_time=1; 注: 我设置了1, 也就是执行时间超过1秒的都算慢查询。 Query OK, 0 rows affected (0.00 sec) MySQL> show variables like 'slow%'; +---------------------+---------------+ | Variable_name | Value | +---------------------+---------------+ | slow_launch_time | 2 | | slow_query_log | ON | 注:是否打开日志记录 | slow_query_log_file | /tmp/slow.log | 注: 设置到什么位置 +---------------------+---------------+ 3 rows in set (0.00 sec) MySQL> set global slow_query_log='ON'
注:打开日志记录
一旦slow_query_log变量被设置为ON,MySQL会立即开始记录。
/etc/my.cnf 里面可以设置上面MySQL全局变量的初始值。
long_query_time=1 slow_query_log_file=/tmp/slow.log
MySQL慢查询分析方法二:
MySQLdumpslow命令
/path/MySQLdumpslow -s c -t 10 /tmp/slow-log
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如
/path/MySQLdumpslow -s r -t 10 /tmp/slow-log
得到返回记录集最多的10个查询。
/path/MySQLdumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照时间排序的前10条里面含有左连接的查询语句。
简单点的方法:
打开 my.ini ,找到 [mysqld] 在其下面添加 long_query_time = 2 log-slow-queries = D:/mysql/logs/slow.log #设置把日志写在那里,可以为空,系统会给一个缺省的文件 #log-slow-queries = /var/youpath/slow.log linux下host_name-slow.log log-queries-not-using-indexes long_query_time 是指执行超过多长时间(单位是秒)的sql会被记录下来,这里设置的是2秒。
以下是mysqldumpslow常用参数说明,详细的可应用mysqldumpslow -help查询。 -s,是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序(从大到小),ac、at、al、ar表示相应的倒叙。 -t,是top n的意思,即为返回前面多少条数据。 www.jb51.net -g,后边可以写一个正则匹配模式,大小写不敏感。 接下来就是用mysql自带的慢查询工具mysqldumpslow分析了(mysql的bin目录下 ),我这里的日志文件名字是host-slow.log。 列出记录次数最多的10个sql语句 mysqldumpslow -s c -t 10 host-slow.log 列出返回记录集最多的10个sql语句 mysqldumpslow -s r -t 10 host-slow.log 按照时间返回前10条里面含有左连接的sql语句 mysqldumpslow -s t -t 10 -g "left join" host-slow.log 使用mysqldumpslow命令可以非常明确的得到各种我们需要的查询语句,对MySQL查询语句的监控、分析、优化起到非常大的帮助
在日常开发当中,经常会遇到页面打开速度极慢的情况,通过排除,确定了,是数据库的影响,为了迅速查找具体的SQL,可以通过Mysql的日志记录方法。
-- 打开sql执行记录功能
set global log_output='TABLE'; -- 输出到表
set global log=ON; -- 打开所有命令执行记录功能general_log, 所有语句: 成功和未成功的.
set global log_slow_queries=ON; -- 打开慢查询sql记录slow_log, 执行成功的: 慢查询语句和未使用索引的语句
set global long_query_time=0.1; -- 慢查询时间限制(秒)
set global log_queries_not_using_indexes=ON; -- 记录未使用索引的sql语句
-- 查询sql执行记录
select * from mysql.slow_log order by 1; -- 执行成功的:慢查询语句,和未使用索引的语句
select * from mysql.general_log order by 1; -- 所有语句: 成功和未成功的.
-- 关闭sql执行记录
set global log=OFF;
set global log_slow_queries=OFF;
-- long_query_time参数说明
-- v4.0, 4.1, 5.0, v5.1 到 5.1.20(包括):不支持毫秒级别的慢查询分析(支持精度为1-10秒);
-- 5.1.21及以后版本 :支持毫秒级别的慢查询分析, 如0.1;
-- 6.0 到 6.0.3: 不支持毫秒级别的慢查询分析(支持精度为1-10秒);
-- 6.0.4及以后:支持毫秒级别的慢查询分析;
通过日志中记录的Sql,迅速定位到具体的文件,优化sql看一下,是否速度提升了呢?
本文针对MySQL数据库服务器查询逐渐变慢的问题, 进行分析,并提出相应的解决办法,具体的分析解决办法如下:会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影...
本文针对MySQL数据库服务器查询逐渐变慢的问题, 进行分析,并提出相应的解决办法,具体的分析解决办法如下:
会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影响,例如一个几千万条记录的大表要全部扫描,或者是不停的做filesort,对数据库和服务器造成io影响等。这是镜像库上面的情况。
而到了线上库,除了出现没有索引的语句,没有用limit的语句,还多了一个情况,mysql连接数过多的问题。说到这里,先来看看以前我们的监控做法
1. 部署zabbix等开源分布式监控系统,获取每天的数据库的io,cpu,连接数
2. 部署每周性能统计,包含数据增加量,iostat,vmstat,datasize的情况
3. Mysql slowlog收集,列出top 10
以前以为做了这些监控已经是很完美了,现在部署了mysql节点进程监控之后,才发现很多弊端
第一种做法的弊端: zabbix太庞大,而且不是在mysql内部做的监控,很多数据不是非常准备,现在一般都是用来查阅历史的数据情况
第二种做法的弊端:因为是每周只跑一次,很多情况没法发现和报警
第三种做法的弊端: 当节点的slowlog非常多的时候,top10就变得没意义了,而且很多时候会给出那些是一定要跑的定期任务语句给你。。参考的价值不大
那么我们怎么来解决和查询这些问题呢
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MYSQL的慢查询以及没有得用索引的查询。
OK,开始找出mysql中执行起来不“爽”的SQL语句吧。
方法一: 这个方法我正在用,呵呵,比较喜欢这种即时性的。
Mysql5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
mysql> show variables like 'long%'; 注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) mysql> set long_query_time=1; 注: 我设置了1, 也就是执行时间超过1秒的都算慢查询。 Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'slow%'; +---------------------+---------------+ | Variable_name | Value | +---------------------+---------------+ | slow_launch_time | 2 | | slow_query_log | ON | 注:是否打开日志记录 | slow_query_log_file | /tmp/slow.log | 注: 设置到什么位置 +---------------------+---------------+ 3 rows in set (0.00 sec)
mysql> set global slow_query_log='ON' 注:打开日志记录
一旦slow_query_log变量被设置为ON,mysql会立即开始记录。
/etc/my.cnf 里面可以设置上面MYSQL全局变量的初始值。
long_query_time=1
slow_query_log_file=/tmp/slow.log
方法二:mysqldumpslow命令
/path/mysqldumpslow -s c -t 10 /tmp/slow-log
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如
/path/mysqldumpslow -s r -t 10 /tmp/slow-log
得到返回记录集最多的10个查询。
/path/mysqldumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照时间排序的前10条里面含有左连接的查询语句。
最后总结一下节点监控的好处
1. 轻量级的监控,而且是实时的,还可以根据实际的情况来定制和修改
2. 设置了过滤程序,可以对那些一定要跑的语句进行过滤
3. 及时发现那些没有用索引,或者是不合法的查询,虽然这很耗时去处理那些慢语句,但这样可以避免数据库挂掉,还是值得的
4. 在数据库出现连接数过多的时候,程序会自动保存当前数据库的processlist,DBA进行原因查找的时候这可是利器
5. 使用mysqlbinlog 来分析的时候,可以得到明确的数据库状态异常的时间段
有些人会建义我们来做mysql配置文件设置
调节tmp_table_size 的时候发现另外一些参数
Qcache_queries_in_cache 在缓存中已注册的查询数目
Qcache_inserts 被加入到缓存中的查询数目
Qcache_hits 缓存采样数数目
Qcache_lowmem_prunes 因为缺少内存而被从缓存中删除的查询数目
Qcache_not_cached 没有被缓存的查询数目 (不能被缓存的,或由于 QUERY_CACHE_TYPE)
Qcache_free_memory 查询缓存的空闲内存总数
Qcache_free_blocks 查询缓存中的空闲内存块的数目
Qcache_total_blocks 查询缓存中的块的总数目
Qcache_free_memory 可以缓存一些常用的查询,如果是常用的sql会被装载到内存。那样会增加数据库访问速度
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!