
Maison >Java >javaDidacticiel >Explication détaillée de la façon dont LinkedHashMap garantit l'ordre d'itération des éléments
Explication détaillée de la façon dont LinkedHashMap garantit l'ordre d'itération des éléments

- Y2Joriginal
- 2017-05-12 09:38:186474parcourir
Cet article présente principalement les connaissances pertinentes de LinkedHashMap en Java, qui a une bonne valeur de référence. Jetons un coup d'œil avec l'éditeur ci-dessous
Première introduction à LinkedHashMap
Dans la plupart des cas, Map peut essentiellement utiliser HashMap tant qu'il n'implique pas de problèmes de sécurité des threads, mais il y a un problème avec HashMap, c'est-à-dire que l'ordre dans lequel HashMap est itéré n'est pas l'ordre dans lequel HashMap est placé , qui est désordonné. Cette lacune de HashMap pose souvent problème, car dans certains scénarios, nous nous attendons à une Map ordonnée.
En ce moment, LinkedHashMap fait ses débuts. Bien qu'il augmente la surcharge de temps et d'espace, En maintenant une liste doublement chaînée qui s'exécute sur toutes les entrées, LinkedHashMap garantit l'ordre d'itération des éléments.
Les réponses aux quatre préoccupations sur LinkedHashMap
| 关 注 点 | 结 论 |
| LinkedHashMap是否允许空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
Structure de base de LinkedHashMap
À propos de LinkedHashMap, permettez-moi de mentionner deux points :
1 LinkedHashMap peut être considéré comme HashMap+Linked. List, c'est-à-dire qu'il utilise non seulement HashMap pour faire fonctionner la structure de données, mais utilise également LinkedList pour maintenir l'ordre des éléments insérés
2. L'idée de base d'implémentation de LinkedHashMap C'est ----polymorphique. On peut dire que comprendre le polymorphisme puis comprendre le principe LinkedHashMap obtiendra deux fois le résultat avec la moitié de l'effort. À l'inverse, l'apprentissage du principe LinkedHashMap peut également promouvoir et approfondir la compréhension du polymorphisme ;
Pourquoi pouvons-nous dire cela ? Tout d'abord, jetez un œil à la définition de LinkedHashMap :
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}Vous voyez, LinkedHashMap est une sous-classe de HashMap, donc naturellement LinkedHashMap héritera Toutes les méthodes non privées dans HashMap. Jetons un coup d'œil aux méthodes dans LinkedHashMap :
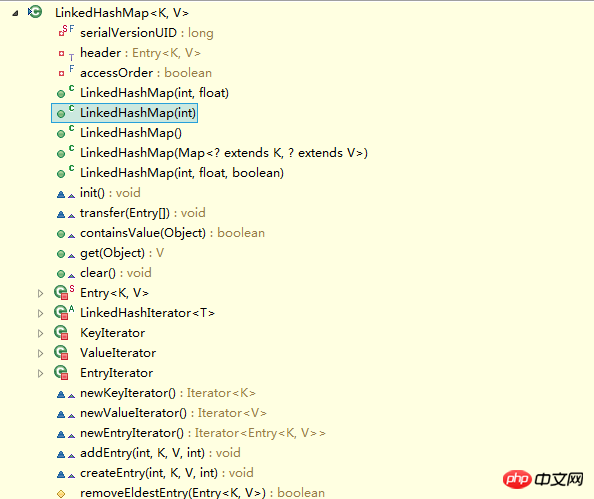
Nous voyons qu'il n'existe aucune méthode pour faire fonctionner les structures de données dans LinkedHashMap, ce qui signifie que LinkedHashMap opère sur des structures de données (telles que mettre une donnée). , la méthode d'exploitation des données est exactement la même que celle de HashMap, mais il existe quelques différences dans les détails.
La différence entre LinkedHashMap et HashMap réside dans leur structure de données de base. Jetez un œil à la structure de données de base de LinkedHashMap, qui est Entry :
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
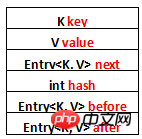
}Répertoriez certaines des entrées dans Entry. Attributs :
Touche K
Valeur V
Entréeb56561a2c0bc639cf0044c0859afb88f suivant
-
int hash
Entrée
Entréeb56561a2c0bc639cf0044c0859afb88f après
Les quatre premiers, c'est-à-dire le rouge la partie provient de Inherited from HashMap.Entry ; les deux dernières, c'est-à-dire la partie bleue, sont uniques à LinkedHashMap. Ne confondez pas next avec before et After. next est utilisé pour maintenir l'ordre des entrées connectées à la position spécifiée dans la table de HashMap avant et After sont utilisés pour maintenir l'ordre d'insertion des entrées.
Utilisons un diagramme pour le représenter et listons les attributs :
Initialiser LinkedHashMap
Supposons qu'il existe un tel morceau de code :
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}Tout d'abord, ligne 3 ~ ligne 4, un nouveau LinkedHashMap sort, voyez ce qui est fait :
public LinkedHashMap() {
super();
accessOrder = false;
} public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
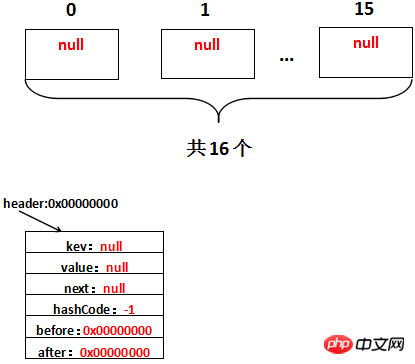
}void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
} /** * The head of the doubly linked list. */ private transient Entry<K,V> header;
Le premier polymorphisme apparaît ici : la méthode init(). Bien que la méthode init() soit définie dans HashMap, en raison de :
1. LinkedHashMap remplace la méthode init
2. Ce qui est instancié est LinkedHashMap
, c'est donc le cas. en fait appelée La méthode init est la méthode init remplacée par LinkedHashMap. Supposons que l'adresse de l'en-tête soit 0x00000000, puis après initialisation, cela ressemble en fait à ceci :
LinkedHashMap ajoute des éléments
Continuez à regarder LinkedHashMap Ajouter des éléments, c'est-à-dire ce que fait put("111", "111"), c'est bien sûr appeler la méthode put de HashMap :
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}La ligne 17 est un autre polymorphisme car LinkedHashMap est réécrite La méthode addEntry est ajoutée, donc addEntry appelle la méthode réécrite de LinkedHashMap :
void addEntry(int hash, K key, V value, int bucketIndex) {
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}Parce que LinkedHashMap lui-même maintient l'ordre d'insertion, LinkedHashMap peut être utilisé pour la mise en cache , Lignes 5 à 7 sont utilisés pour prendre en charge l'algorithme FIFO, nous n'avons donc pas à nous en soucier pour le moment. Jetez un œil à la méthode createEntry :
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}Le code des lignes 2 à 4 n'est pas différent de HashMap , L'élément nouvellement ajouté est placé sur table[i]. La différence est que LinkedHashMap effectue également l'opération addBefore. La signification de ces quatre lignes de code est de générer une liste doublement chaînée entre la nouvelle entrée et la liste chaînée d'origine. Si Si vous connaissez le code source de LinkedList, cela ne devrait pas être difficile à comprendre. Notez qu'existantEntry représente l'en-tête : . 1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000 2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000 3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001 4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001 这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的: 就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。 总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。 利用LinkedHashMap实现LRU算法缓存 前面讲了LinkedHashMap添加元素,删除、修改元素就不说了,比较简单,和HashMap+LinkedList的删除、修改元素大同小异,下面讲一个新的内容。 LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已: 顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点: 1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致 2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU 那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。 我们看一下LinkedList带boolean型参数的构造方法: 就是这个accessOrder,它表示: (1)false,所有的Entry按照插入的顺序排列 (2)true,所有的Entry按照访问的顺序排列 第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。 "访问",这个词有两层意思: 1、根据Key拿到Value,也就是get方法 2、修改Key对应的Value,也就是put方法 首先看一下get方法,它在LinkedHashMap中被重写: 然后是put方法,沿用父类HashMap的: 修改数据也就是第6行~第14行的代码。看到两端代码都有一个共同点:都调用了recordAccess方法,且这个方法是Entry中的方法,也就是说每次的recordAccess操作的都是某一个固定的Entry。 recordAccess,顾名思义,记录访问,也就是说你这次访问了双向链表,我就把你记录下来,怎么记录?把你访问的Entry移到尾部去。这个方法在HashMap中是一个空方法,就是用来给子类记录访问用的,看一下LinkedHashMap中的实现: 看到每次recordAccess的时候做了两件事情: 1、把待移动的Entry的前后Entry相连 2、把待移动的Entry移动到尾部 当然,这一切都是基于accessOrder=true的情况下。最后用一张图表示一下整个recordAccess的过程吧: 代码演示LinkedHashMap按照访问顺序排序的效果 最后代码演示一下LinkedList按照访问顺序排序的效果,验证一下上一部分LinkedHashMap的LRU功能: 注意这里的构造方法要用三个参数那个且最后的要传入true,这样才表示按照访问顺序排序。看一下代码运行结果: 代码运行结果证明了两点: 1、LinkedList是有序的 2、每次访问一个元素(get或put),被访问的元素都被提到最后面去了 【相关推荐】 1. Java免费视频教程 2. 全面解析Java注解 3. Java教程手册
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}private void remove() {
before.after = after;
after.before = before;
}private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator();
while (iterator.hasNext())
{
System.out.print(iterator.next() + "\t");
}
System.out.println();
}111=111 222=222 333=333 444=444
222=222 333=333 444=444 111=111
333=333 444=444 111=111 222=2222
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!