
Maison >développement back-end >Tutoriel Python >Explication détaillée d'exemples de chaînes de nettoyage en Python
Explication détaillée d'exemples de chaînes de nettoyage en Python

- Y2Joriginal
- 2017-05-10 12:00:302470parcourir
Cet article présente principalement les informations pertinentes sur le traitement des chaînes du nettoyage des données Python. Les amis qui en ont besoin peuvent s'y référer
Avant-propos
Le nettoyage des données est un complexe. et fastidieux (kubi), c'est aussi le maillon le plus important de tout le processus d'analyse des données. Certaines personnes disent que 80 % du temps consacré à un projet d’analyse est consacré au nettoyage des données. Cela semble étrange, mais c’est vrai dans le travail réel. Le nettoyage des données a deux objectifs. Le premier est de rendre les données disponibles via le nettoyage. La seconde consiste à rendre les données plus adaptées à une analyse ultérieure. En d’autres termes, il y a des données « sales » qui doivent être nettoyées, et des données propres qui doivent également être nettoyées.
Dans l'analyse de données, en particulier l'analyse de texte, le traitement des caractères nécessite beaucoup d'énergie, donc comprendre le traitement des caractères est également une capacité très importante pour l'analyse des données.
Méthodes de traitement des chaînes
Tout d'abord, comprenons quelles sont les méthodes de base.
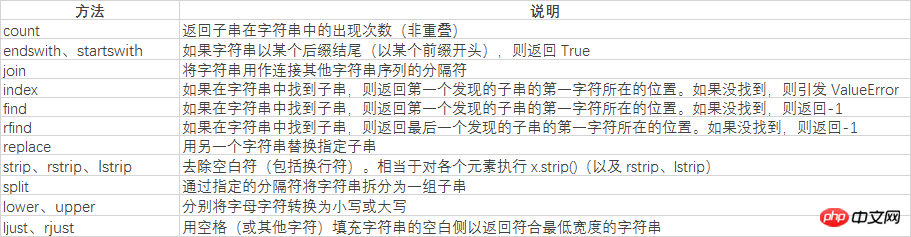
Tout d'abord tout, comprenons La méthode de fractionnement de chaîne suivante
str='i like apple,i like bananer' print(str.split(','))
entraîne la division de la chaîne de caractères avec des virgules :
['j'aime la pomme', 'j'aime bananer']
print(str.split(' '))
Le résultat du fractionnement basé sur les espaces :
['i', 'like', 'apple,i', 'like', 'bananer']
print(str.index(',')) print(str.find(','))
Les deux résultats de recherche sont :
12
S'il n'est pas trouvé, index renvoie une erreur et find renvoie -1
print(str.count('i'))
Le résultat est :
4
connt est utilisé pour compter la fréquence de la chaîne cible
print(str.replace(',', ' ').split(' '))
Le résultat est :
['i', 'like', 'apple', 'i', 'like', 'bananer']
Ici, remplacer les virgules par des espaces, en utilisant des espaces pour diviser la chaîne, juste assez pour supprimer chaque mot.
En plus des méthodes conventionnelles, l'outil de traitement de caractères le plus puissant Expression régulière n'est autre que.
Expressions régulières
Avant d'utiliser des expressions régulières, nous devons comprendre les nombreuses méthodes des expressions régulières.

Permettez-moi d'examiner l'utilisation de la méthode suivante. Tout d'abord, comprenez la différence entre les méthodes de correspondance et de recherche
str = "Cats are smarter than dogs" pattern=re.compile(r'(.*) are (.*?) .*') result=re.match(pattern,str) for i in range(len(result.groups())+1): print(result.group(i))
Le résultat est :
Les chats sont plus intelligents que les chiens
Les chats
plus intelligents
Sous cette forme de règle de correspondance de pettern, les résultats de retour des méthodes de correspondance et de recherche sont les pareil
À ce moment, si vous modifiez le modèle en
pattern=re.compile(r'are (.*?) .*')
match ne renverra aucun et le résultat de la recherche sera :
sont plus intelligents que les chiens
plus intelligents
Apprenons ensuite l'utilisation d'autres méthodes
str = "138-9592-5592 # number" pattern=re.compile(r'#.*$') number=re.sub(pattern,'',str) print(number)
Le résultat est :
138- 9592-5592
Ce qui précède consiste à extraire le numéro en remplaçant le contenu après le signe # par rien.
On peut encore remplacer la barre transversale du numéro
print(re.sub(r'-*','',number))
Le résultat est :
13895925592
Nous pouvons également utiliser la méthode find pour imprimer la chaîne trouvée
str = "138-9592-5592 # number" pattern=re.compile(r'5') print(pattern.findall(str))
Le résultat est :
['5', '5', '5']
Le contenu global des expressions régulières est relativement volumineux et nous devons avoir une compréhension suffisante des règles de correspondance des chaînes. Voici les règles de correspondance spécifiques.

Chaîne vectoriséeFonction
Lors du nettoyage des données dispersées à analyser, il faut souvent effectuer un travail de normalisation de chaîne.
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data)Le résultat est :

Vous pouvez porter des jugements préliminaires sur les données grâce à certaines méthodes d'intégration, telles que l'utilisation de contain pour déterminer si chaque data contain Contenant les mots-clés
print(data.str.contains('@'))
le résultat est :

Vous pouvez également diviser la chaîne et extraire la chaîne requise
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
pattern=re.compile(r'(\d*)@([a-z]+)\.([a-z]{2,4})')
result=data.str.match(pattern) #这里用fillall的方法也可以result=data.str.findall(pattern)
print(result) Le résultat est :
chen [(8622, xinlang, com)]
li [(120, qq, com)]
soleil [(5243, gmail, com) )]
wang [(5632, qq, com)]
zhao NaN
dtype : object
Pour rejoindre à ce moment-là, nous devons extraire au recto de l'adresse email Le nom
print(result.str.get(0))
donne :

ou le nom de domaine auquel appartient l'adresse email
print(result.str.get(1))
donne :

Bien sûr, elles peuvent également être extraites par découpage, mais la précision des données extraites n'est pas élevée
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data.str[:6])Le résultat est :

Enfin, nous apprenons la méthode des chaînes vectorisées

Résumé
[Connexe recommandations]
1. Tutoriel vidéo gratuit Python
2 Tutoriel vidéo orienté objet Python
3. >Tutoriel d'introduction de base à Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!