
Maison >développement back-end >Tutoriel Python >Explication détaillée du code python du proxy asynchrone et du pool de proxy
Explication détaillée du code python du proxy asynchrone et du pool de proxy

- Y2Joriginal
- 2017-05-10 11:33:132095parcourir
Cet article présente principalement les connaissances pertinentes de Python pour implémenter des robots d'exploration de proxy asynchrones et des pools de proxy. Il a une très bonne valeur de référence. Jetons-y un coup d'œil avec l'éditeur.
Utiliser python asyncio pour implémenter. un pool de proxys asynchrones, explorez les proxys gratuits sur le site Web du proxy selon les règles, stockez-les dans Redis après avoir vérifié leur validité, augmentez régulièrement le nombre de proxys et vérifiez la validité des proxys dans le pool, et supprimez les proxys invalides. Dans le même temps, un serveur est implémenté à l'aide d'aiohttp et d'autres programmes peuvent obtenir le proxy du pool de proxy en accédant à l'URL correspondante.
Code source
Github
Environnement
Python 3.5+
Redis
PhantomJS (facultatif)
Superviseur (facultatif) )
Étant donné que les syntaxes async et wait d'asyncio sont largement utilisées dans le code, elles ne sont fournies que dans Python3.5, il est donc préférable d'utiliser Python3.5 et supérieur. 6 est utilisé.
Dépend de
redis
aiohttp
bs4
lxml
requêtes
-
sélénium
Le package sélénium est principalement utilisé pour faire fonctionner PhantomJS.
Le code est expliqué ci-dessous.
1. Partie chenille
Code de base
async def start(self):
for rule in self._rules:
parser = asyncio.ensure_future(self._parse_page(rule)) # 根据规则解析页面来获取代理
logger.debug('{0} crawler started'.format(rule.rule_name))
if not rule.use_phantomjs:
await page_download(ProxyCrawler._url_generator(rule), self._pages, self._stop_flag) # 爬取代理网站的页面
else:
await page_download_phantomjs(ProxyCrawler._url_generator(rule), self._pages,
rule.phantomjs_load_flag, self._stop_flag) # 使用PhantomJS爬取
await self._pages.join()
parser.cancel()
logger.debug('{0} crawler finished'.format(rule.rule_name))Le code de base ci-dessus est en fait, ce qui précède est un modèle producteur-consommateur implémenté à l'aide de asyncio.Queue. Ce qui suit est une implémentation simple de ce modèle :
import asyncio from random import random async def produce(queue, n): for x in range(1, n + 1): print('produce ', x) await asyncio.sleep(random()) await queue.put(x) # 向queue中放入item async def consume(queue): while 1: item = await queue.get() # 等待从queue中获取item print('consume ', item) await asyncio.sleep(random()) queue.task_done() # 通知queue当前item处理完毕 async def run(n): queue = asyncio.Queue() consumer = asyncio.ensure_future(consume(queue)) await produce(queue, n) # 等待生产者结束 await queue.join() # 阻塞直到queue不为空 consumer.cancel() # 取消消费者任务,否则它会一直阻塞在get方法处 def aio_queue_run(n): loop = asyncio.get_event_loop() try: loop.run_until_complete(run(n)) # 持续运行event loop直到任务run(n)结束 finally: loop.close() if name == 'main': aio_queue_run(5)
En exécutant le code ci-dessus, une sortie possible est la suivante. Suit:
produce 1 produce 2 consume 1 produce 3 produce 4 consume 2 produce 5 consume 3 consume 4 consume 5
Pages d'exploration
async def page_download(urls, pages, flag):
url_generator = urls
async with aiohttp.ClientSession() as session:
for url in url_generator:
if flag.is_set():
break
await asyncio.sleep(uniform(delay - 0.5, delay + 1))
logger.debug('crawling proxy web page {0}'.format(url))
try:
async with session.get(url, headers=headers, timeout=10) as response:
page = await response.text()
parsed = html.fromstring(decode_html(page)) # 使用bs4来辅助lxml解码网页:http://lxml.de/elementsoup.html#Using only the encoding detection
await pages.put(parsed)
url_generator.send(parsed) # 根据当前页面来获取下一页的地址
except StopIteration:
break
except asyncio.TimeoutError:
logger.error('crawling {0} timeout'.format(url))
continue # TODO: use a proxy
except Exception as e:
logger.error(e)Exploration du Web à l'aide d'aiohttpFonction, big Certains sites Web proxy peut être exploré en utilisant la méthode ci-dessus. Pour les sites Web qui utilisent js pour générer dynamiquement des pages, vous pouvez utiliser Selenium pour contrôler PhantomJS pour l'exploration - ce projet n'a pas d'exigences élevées en matière d'efficacité du robot d'exploration. La mise à jour du proxy. site WebLa fréquence est limitée et il n'est pas nécessaire d'explorer fréquemment PhantomJS.
Analyser le proxy
Le moyen le plus simple est d'utiliser XPath pour analyser le proxy. Si vous utilisez le navigateur Chrome, vous pouvez l'obtenir. directement en faisant un clic droit sur XPath de l'élément de page sélectionné :
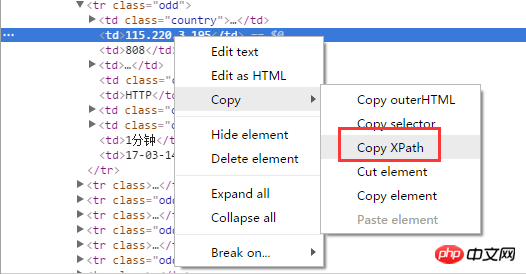
Installerl'extension Chrome "XPath Helper" pour l'exécuter et déboguer directement sur le pagexpath, très pratique :
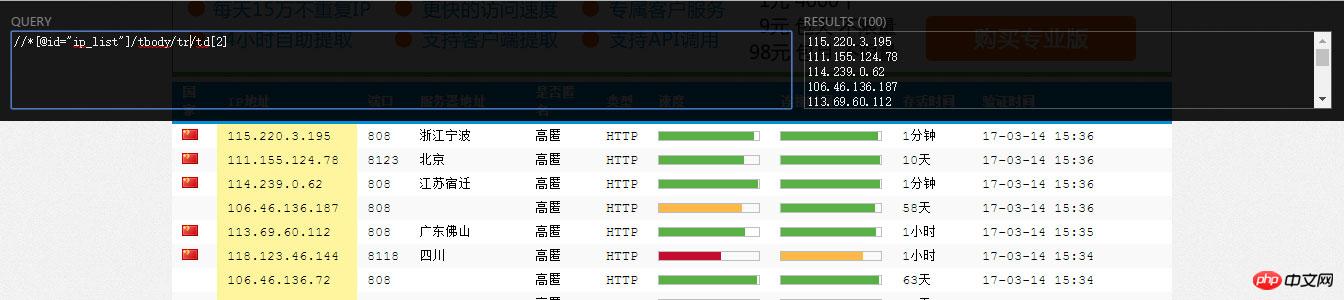
BeautifulSoup ne supporte pas xpath et utilise lxml pour analyser la page. Le code est le suivant :
async def _parse_proxy(self, rule, page):
ips = page.xpath(rule.ip_xpath) # 根据xpath解析得到list类型的ip地址集合
ports = page.xpath(rule.port_xpath) # 根据xpath解析得到list类型的ip地址集合
if not ips or not ports:
logger.warning('{2} crawler could not get ip(len={0}) or port(len={1}), please check the xpaths or network'.
format(len(ips), len(ports), rule.rule_name))
return
proxies = map(lambda x, y: '{0}:{1}'.format(x.text.strip(), y.text.strip()), ips, ports)
if rule.filters: # 根据过滤字段来过滤代理,如“高匿”、“透明”等
filters = []
for i, ft in enumerate(rule.filters_xpath):
field = page.xpath(ft)
if not field:
logger.warning('{1} crawler could not get {0} field, please check the filter xpath'.
format(rule.filters[i], rule.rule_name))
continue
filters.append(map(lambda x: x.text.strip(), field))
filters = zip(*filters)
selector = map(lambda x: x == rule.filters, filters)
proxies = compress(proxies, selector)
for proxy in proxies:
await self._proxies.put(proxy) # 解析后的代理放入asyncio.Queue中Règles d'exploration
Les règles d'exploration des sites Web, d'analyse du proxy, de filtrage et d'autres opérations sont définies par les classes de règles de chaque métaclasse et classes de base. sont utilisés pour gérer les classes de règles. La classe de base est définie comme suit :
class CrawlerRuleBase(object, metaclass=CrawlerRuleMeta): start_url = None page_count = 0 urls_format = None next_page_xpath = None next_page_host = '' use_phantomjs = False phantomjs_load_flag = None filters = () ip_xpath = None port_xpath = None filters_xpath = ()
La signification de chaque paramètre est la suivante :
start_url(obligatoire)
Page de démarrage du robot.
ip_xpath(obligatoire)
Règles XPath pour l'exploration de l'IP.
port_xpath(obligatoire)
Règles XPath pour l'exploration des numéros de port.
page_count
Nombre de pages explorées.
urls_format
Format de l'adresse de la page String, il est plus courant de générer l'adresse de la page n via urls_format.format(start_url, n) Format de l'adresse de la page .
next_page_xpath, next_page_host
utilise les règles XPath pour obtenir l'URL de la page suivante (common est le chemin relatif) et se combine avec l'hôte pour obtenir l'adresse de la page suivante : next_page_host + url.
use_phantomjs, phantomjs_load_flag
use_phantomjs est utilisé pour identifier si PhantomJS est requis pour explorer le site Web. S'il est utilisé, phantomjs_load_flag (un élément sur la page Web, type str) doit le faire. être défini comme un signe que la page PhantomJS a été chargée.
filters
Collection de champs de filtre, type itérable. Utilisé pour filtrer les proxys.
Explorez les règles XPath de chaque champ de filtre et faites correspondre les champs de filtre dans l'ordre.
La métaclasse CrawlerRuleMeta est utilisée pour gérer la définition des classes de règles. Par exemple : si use_phantomjs=True est défini, phantomjs_load_flag doit être défini, sinon il lancera une exception , qui ne le fera pas. être décrit ici.
目前已经实现的规则有西刺代理、快代理、360代理、66代理和 秘密代理。新增规则类也很简单,通过继承CrawlerRuleBase来定义新的规则类YourRuleClass,放在proxypool/rules目录下,并在该目录下的init.py中添加from . import YourRuleClass(这样通过CrawlerRuleBase.subclasses()就可以获取全部的规则类了),重启正在运行的proxy pool即可应用新的规则。
2. 检验部分
免费的代理虽然多,但是可用的却不多,所以爬取到代理后需要对其进行检验,有效的代理才能放入代理池中,而代理也是有时效性的,还要定期对池中的代理进行检验,及时移除失效的代理。
这部分就很简单了,使用aiohttp通过代理来访问某个网站,若超时,则说明代理无效。
async def validate(self, proxies): logger.debug('validator started') while 1: proxy = await proxies.get() async with aiohttp.ClientSession() as session: try: real_proxy = 'http://' + proxy async with session.get(self.validate_url, proxy=real_proxy, timeout=validate_timeout) as resp: self._conn.put(proxy) except Exception as e: logger.error(e) proxies.task_done()
3. server部分
使用aiohttp实现了一个web server,启动后,访问http://host:port即可显示主页:
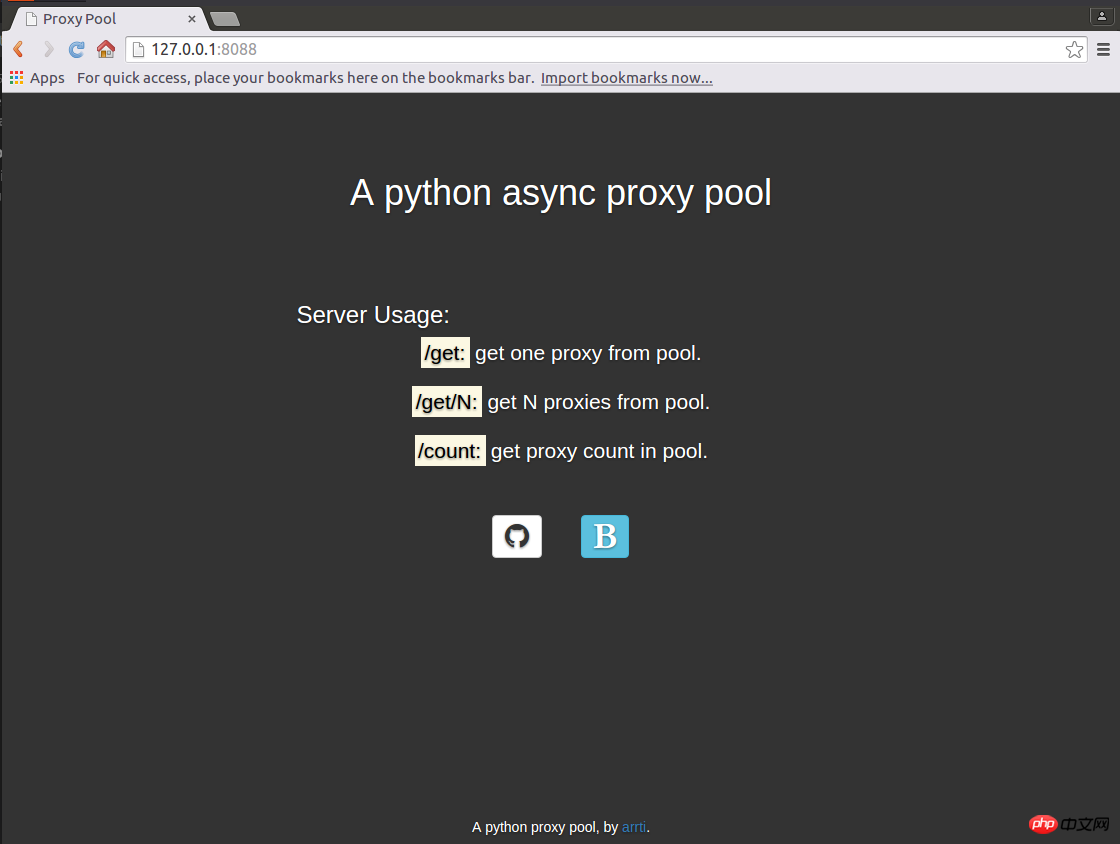
访问host:port/get来从代理池获取1个代理,如:'127.0.0.1:1080';
访问host:port/get/n来从代理池获取n个代理,如:"['127.0.0.1:1080', '127.0.0.1:443', '127.0.0.1:80']";
访问host:port/count来获取代理池的容量,如:'42'。
因为主页是一个静态的html页面,为避免每来一个访问主页的请求都要打开、读取以及关闭该html文件的开销,将其缓存到了redis中,通过html文件的修改时间来判断其是否被修改过,如果修改时间与redis缓存的修改时间不同,则认为html文件被修改了,则重新读取文件,并更新缓存,否则从redis中获取主页的内容。
返回代理是通过aiohttp.web.Response(text=ip.decode('utf-8'))实现的,text要求str类型,而从redis中获取到的是bytes类型,需要进行转换。返回的多个代理,使用eval即可转换为list类型。
返回主页则不同,是通过aiohttp.web.Response(body=main_page_cache, content_type='text/html') ,这里body要求的是bytes类型,直接将从redis获取的缓存返回即可,conten_type='text/html'必不可少,否则无法通过浏览器加载主页,而是会将主页下载下来——在运行官方文档中的示例代码的时候也要注意这点,那些示例代码基本上都没有设置content_type。
这部分不复杂,注意上面提到的几点,而关于主页使用的静态资源文件的路径,可以参考之前的博客《aiohttp之添加静态资源路径》。
4. 运行
将整个代理池的功能分成了3个独立的部分:
proxypool
定期检查代理池容量,若低于下限则启动代理爬虫并对代理检验,通过检验的爬虫放入代理池,达到规定的数量则停止爬虫。
proxyvalidator
用于定期检验代理池中的代理,移除失效代理。
proxyserver
启动server。
这3个独立的任务通过3个进程来运行,在Linux下可以使用supervisod来=管理这些进程,下面是supervisord的配置文件示例:
; supervisord.conf [unix_http_server] file=/tmp/supervisor.sock [inet_http_server] port=127.0.0.1:9001 [supervisord] logfile=/tmp/supervisord.log logfile_maxbytes=5MB logfile_backups=10 loglevel=debug pidfile=/tmp/supervisord.pid nodaemon=false minfds=1024 minprocs=200 [rpcinterface:supervisor] supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface [supervisorctl] serverurl=unix:///tmp/supervisor.sock [program:proxyPool] command=python /path/to/ProxyPool/run_proxypool.py redirect_stderr=true stdout_logfile=NONE [program:proxyValidator] command=python /path/to/ProxyPool/run_proxyvalidator.py redirect_stderr=true stdout_logfile=NONE [program:proxyServer] command=python /path/to/ProxyPool/run_proxyserver.py autostart=false redirect_stderr=true stdout_logfile=NONE
因为项目自身已经配置了日志,所以这里就不需要再用supervisord捕获stdout和stderr了。通过supervisord -c supervisord.conf启动supervisord,proxyPool和proxyServer则会随之自动启动,proxyServer需要手动启动,访问http://127.0.0.1:9001即可通过网页来管理这3个进程了:
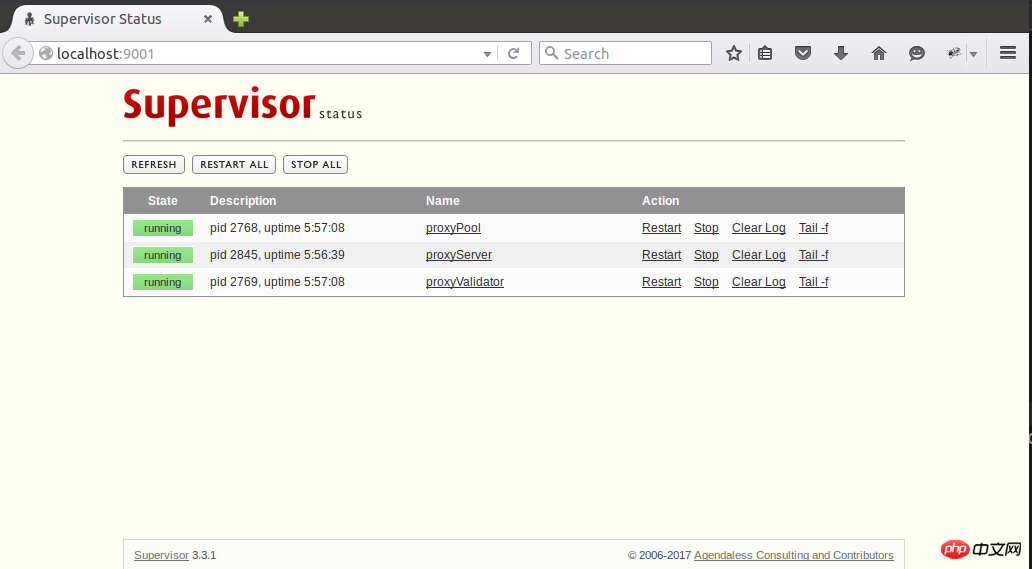
supervisod的官方文档说目前(版本3.3.1)不支持python3,但是我在使用过程中没有发现什么问题,可能也是由于我并没有使用supervisord的复杂功能,只是把它当作了一个简单的进程状态监控和启停工具了。
【相关推荐】
1. Python免费视频教程
2. Tutoriel vidéo Python rencontre la collecte de données
3 Manuel d'apprentissage Python
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!