
Maison >Java >javaDidacticiel >Présentation de HashMap, stockage de collections Java
Présentation de HashMap, stockage de collections Java

- Y2Joriginal
- 2017-05-09 11:52:491632parcourir
Cet article présente principalement le principe de fonctionnement de HashMap_Compiled par Power Node Java Academy. Les amis dans le besoin peuvent s'y référer
En fait, il existe de nombreuses similitudes entre HashSet et HashMap, Pour HashSet, le système utilise le. Algorithme de hachage pour déterminer l'emplacement de stockage des éléments de l'ensemble, ce qui garantit que les éléments de l'ensemble peuvent être stockés et récupérés rapidement ; pour HashMap, la valeur-clé du système est traitée dans son ensemble et le système calcule toujours le stockage de la valeur-clé en fonction. sur l'emplacement de l'algorithme de hachage, qui garantit que les paires clé-valeur de la carte peuvent être rapidement stockées et récupérées.
Avant d'introduire le stockage de collections, une chose doit être soulignée : bien que les collections prétendent stocker des objets Java, les objets Java ne sont pas réellement placés dans les collections Set Keep . références à ces objets de la collection Set. C'est-à-dire : une collection Java est en fait une collection de plusieurs variables de référence, qui pointent vers des objets Java réels. Tout comme le type de référence tableau, lorsque nous mettons l'objet Java dans le tableau, nous ne mettons pas réellement l'objet Java dans le tableau, mais mettons simplement la référence de l'objet dans le tableau Chaque tableau Chaque. L'élément est une variable de référence.
Implémentation du stockage HashMap (méthode put())
Lorsque le programme essaie de mettre plusieurs valeurs-clés dans HashMap, pour Prenons l'exemple de l'extrait de code suivant :
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("语文" , 80.0);
map.put("数学" , 89.0);
map.put("英语" , 78.2);HashMap utilise ce qu'on appelle un "algorithme de hachage" pour déterminer l'emplacement de stockage de chaque élément.
Lorsque le programme exécute map.put("Chinese",80.0), le système appellera la méthode hashCode() de "Chinese" (c'est-à-dire Key) pour obtenir sa valeur hashCode --- chaque objet Java a hashCode (), vous pouvez obtenir sa valeur hashCode via cette méthode. Après avoir obtenu la valeur hashCode de cet objet, le système détermine l'emplacement de stockage de l'élément en fonction de la valeur hashCode.
On peut regarder le code source de la méthode put(K key, V value) de la classe HashMap :
public V put(K key, V value)
{
// 如果 key 为 null,调用 putForNullKey 方法进行处理
if (key == null)
return putForNullKey(value);
// 根据 key 的 keyCode 计算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在对应 table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next)
{
Object k;
// 找到指定 key 与需要放入的 key 相等(hash 值相同
// 通过 equals 比较放回 true)
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引处的 Entry 为 null,表明此处还没有 Entry
modCount++;
// 将 key、value 添加到 i 索引处
addEntry(hash, key, value, i);
return null;
}Une interface interne importante est utilisée dans le programme ci-dessus : Map.Entry, chaque Map.Entry est en fait une paire clé-valeur. Comme le montre le programme ci-dessus : lorsque le système décide de stocker les paires clé-valeur dans le HashMap, il ne prend pas du tout en compte la valeur de l'entrée, mais calcule et détermine uniquement l'emplacement de stockage de chaque entrée en fonction de la clé. Cela illustre également la conclusion précédente : nous pouvons tout à fait considérer la valeur de la collection Map comme un accessoire de la clé. Une fois que le système a déterminé l'emplacement de stockage de la clé, la valeur peut y être stockée.
La méthode ci-dessus fournit une méthode pour calculer le code de hachage basé sur la valeur de retour de hashCode() : hash(). Cette méthode est un calcul purement mathématique. La méthode est la suivante :
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}Pour tout objet donné, tant que sa valeur de retour hashCode() est la même, la valeur du code de hachage calculée par le programme appelant la méthode hash(int h) est toujours la même. Ensuite, le programme appellera la méthode indexFor(int h, int length) pour calculer à quel index du tableau l'objet doit être enregistré. Le code de la méthode indexFor(int h, int length) est le suivant : static int indexFor(int h, int length)
{
return h & (length-1);
}Cette méthode est très astucieuse, elle récupère toujours l'objet via h &(table.length -1) L'emplacement de stockage - et la longueur du tableau sous-jacent de HashMap sont toujours de 2 à la nième puissance. Pour ce point, veuillez vous référer à l'introduction du constructeur HashMap plus tard. Lorsque la longueur est toujours un multiple de 2, h & (longueur-1) sera une conception très intelligente : en supposant h=5, longueur=16, alors h & longueur - 1 obtiendra 5 si h ; =6, longueur = 16, alors h et longueur - 1 obtiendront 6... si h = 15, longueur = 16, alors h et longueur - 1 obtiendront 15 mais quand h = 16, longueur = 16, alors h ; & length - 1 obtiendra 0 ; lorsque h=17, length=16, alors h & length - 1 obtiendra 1... Cela garantit que la valeur d'index calculée est toujours dans l'index du tableau. 当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。
上面程序中还调用了 addEntry(hash, key, value, i); 代码,其中 addEntry 是 HashMap 提供的一个包访问权限的方法,该方法仅用于添加一个 key-value 对。下面是该方法的代码:
void addEntry(int hash, K key, V value, int bucketIndex)
{
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex]; // ①
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到 2 倍。
resize(2 * table.length); // ②
}上面方法的代码很简单,但其中包含了一个非常优雅的设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序①号代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。
什么是Map.Entry?
Map是java中的接口,Map.Entry是Map的一个内部接口。
Map提供了一些常用方法,如keySet()、entrySet()等方法,keySet()方法返回值是Map中key值的集合;entrySet()的返回值也是返回一个Set集合,此集合的类型为Map.Entry。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entryb77a8d9c3c319e50d4b02a976b347910。它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。
由以上可以得出,遍历Map的常用方法:
1. Map map = new HashMap();
Irerator iterator = map.entrySet().iterator();
while(iterator.hasNext()) {
Map.Entry entry = iterator.next();
Object key = entry.getKey();
//
}
2.Map map = new HashMap();
Set keySet= map.keySet();
Irerator iterator = keySet.iterator;
while(iterator.hasNext()) {
Object key = iterator.next();
Object value = map.get(key);
//
}另外,还有一种遍历方法是,单纯的遍历value值,Map有一个values方法,返回的是value的Collection集合。通过遍历collection也可以遍历value,如
Map map = new HashMap();
Collection c = map.values();
Iterator iterator = c.iterator();
while(iterator.hasNext()) {
Object value = iterator.next();
}Map.Entry是Map内部定义的一个接口,专门用来保存key→value的内容。Map.Entry的定义如下:
1. public static interface Map.Entryb77a8d9c3c319e50d4b02a976b347910
Map.Entry是使用static关键字声明的内部接口,此接口可以由外部通过"外部类.内部类"的形式直接调用。
Map.Entry接口的常用方法
序号 |
方法 |
类型 |
描述 |
1 |
public boolean equals(Object o) |
Normal |
|
2 |
public K getKey() |
Normal |
Obtenir la clé |
3 |
public V getValue() |
ordinaire |
Obtenir de la valeur |
4 |
public int hashCode() |
Normal |
Retour ha Hima |
5 |
public V setValue (valeur V ) |
普通 |
设置value的值 |
从之前的内容可以知道,在Map的操作中,所有的内容都是通过key→value的形式保存数据的,那么对于集合来讲,实际上是将key→value的数据保存在了Map.Entry的实例之后,再在Map集合中插入的是一个Map.Entry的实例化对象,如下图所示。
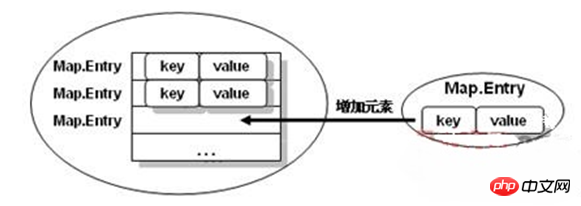
提示:Map.Entry在集合输出时会使用到。
在一般的Map操作中(例如,增加或取出数据等操作)不用去管Map.Entry接口,但是在将Map中的数据全部输出时就必须使用Map.Entry接口
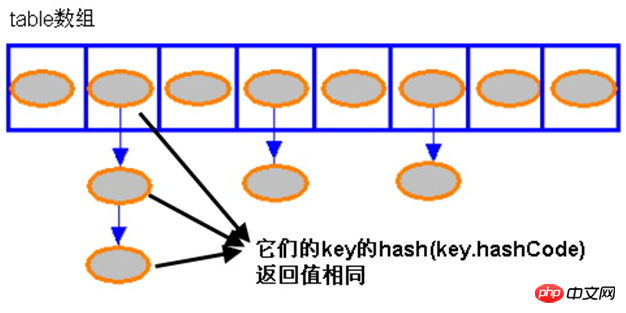
HashMap 的存储示意
HashMap 的读取实现()
当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时,此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。看 HashMap 类的 get(K key) 方法代码:
public V get(Object key)
{
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 直接取出 table 数组中指定索引处的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
// 搜索该 Entry 链的下一个 Entr
e = e.next) // ①
{
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}从上面代码中可以看出,如果 HashMap 的每个 bucket 里只有一个 Entry 时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry;在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用
一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 Hash 算法来决定其存储位置;当需要取出一个 Entry 时,也会根据 Hash 算法找到其存储位置,直接取出该 Entry。由此可见:HashMap 之所以能快速存、取它所包含的 Entry,完全类似于现实生活中母亲从小教我们的:不同的东西要放在不同的位置,需要时才能快速找到它。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
掌握了上面知识之后,我们可以在创建 HashMap 时根据实际需要适当地调整 load factor 的值;如果程序比较关心空间开销、内存比较紧张,可以适当地增加负载因子;如果程序比较关心时间开销,内存比较宽裕则可以适当的减少负载因子。通常情况下,程序员无需改变负载因子的值。
如果开始就知道 HashMap 会保存多个 key-value 对,可以在创建时就使用较大的初始化容量,如果 HashMap 中 Entry 的数量一直不会超过极限容量(capacity * load factor),HashMap 就无需调用 resize() 方法重新分配 table 数组,从而保证较好的性能。当然,开始就将初始容量设置太高可能会浪费空间(系统需要创建一个长度为 capacity 的 Entry 数组),因此创建 HashMap 时初始化容量设置也需要小心对待。
【相关推荐】
1. Java免费视频教程
2. Java教程手册
3. 极客学院Java视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!