
Maison >base de données >tutoriel mysql >Collection de spécifications SQL Server couramment utilisées
Collection de spécifications SQL Server couramment utilisées
- 巴扎黑original
- 2017-05-01 11:25:151287parcourir
Sélection du type de champ commun
1. Il est recommandé d'utiliser le type de données varchar/nvarchar pour le type de caractère
2. Il est recommandé d'utiliser le type de données money pour la devise du montant
3. Il est recommandé d'utiliser le type de données numérique pour la notation scientifique
4. Il est recommandé d'utiliser le type de données bigint pour les logos à croissance automatique (la quantité de données est importante et elles ne peuvent pas être chargées avec le type int, et la transformation sera alors gênante à l'avenir)
5. Il est recommandé que le type d'heure soit le type de données datetime
6. Il est interdit d'utiliser les anciens types de données texte, ntext et image
7. Il est interdit d'utiliser le type de données XML, varchar(max), nvarchar(max)
Contraintes et index
Chaque table doit avoir une clé primaire
Chaque table doit avoir une clé primaire, qui est utilisée pour garantir l'intégrité de l'entité
Une seule table ne peut avoir qu'une seule clé primaire (les données vides et en double ne sont pas autorisées)
Essayez d'utiliser des clés primaires à champ unique
Les clés étrangères ne sont pas autorisées
Les clés étrangères augmentent la complexité des modifications de la structure des tables et de la migration des données
Les clés étrangères ont un impact sur les performances des insertions et des mises à jour. Vous devez vérifier les contraintes des clés étrangères primaires
. L'intégrité des données est contrôlée par le programme
Attribut NULL
Pour la table nouvellement ajoutée, NULL est interdit dans tous les champs
(Pourquoi la nouvelle table n'autorise-t-elle pas NULL ?
Autoriser les valeurs NULL augmentera la complexité de l'application. Vous devez ajouter un code logique spécifique pour éviter divers bugs inattendus
Logique à trois valeurs, toutes les requêtes de signe égal ("=") doivent ajouter un jugement nul.
Null=Null, Null!=Null, not(Null=Null), not(Null!=Null) sont tous inconnus, pas vrais)
Illustrons avec un exemple :
Si les données du tableau sont telles qu'indiquées sur la figure :

Vous souhaitez rechercher toutes les données sauf le nom égal à aa, puis vous utilisez par inadvertance SELECT * FROM NULLTEST WHERE NAME<>’aa’
Le résultat était différent de ce qui était attendu. En fait, il n'a trouvé que l'enregistrement de données avec name=bb mais pas l'enregistrement de données avec name=NULL
. Alors comment retrouver toutes les données sauf le nom égal à aa ? On ne peut utiliser que la fonction ISNULL
SELECT * FROM NULLTEST WHERE ISNULL(NAME,1)<>’aa’
Mais vous ne savez peut-être pas qu'ISNULL peut entraîner de sérieux goulots d'étranglement en termes de performances. Par conséquent, dans de nombreux cas, il est préférable de limiter les entrées des utilisateurs au niveau de l'application pour garantir que les utilisateurs saisissent des données valides avant d'interroger.
Les nouveaux champs ajoutés à l'ancienne table doivent pouvoir être NULL (pour éviter les mises à jour des données dans l'ensemble de la table et le blocage causé par un verrouillage à long terme) (il s'agit principalement d'envisager la transformation de la table précédente)
Directives de conception d'index
Les index doivent être créés sur les colonnes fréquemment utilisées dans les clauses WHERE
Les index doivent être créés sur les colonnes fréquemment utilisées pour joindre des tables
Les index doivent être créés sur les colonnes fréquemment utilisées dans les clauses ORDER BY
Les index ne doivent pas être créés sur de petites tables (tables qui n'utilisent que quelques pages) car une opération d'analyse de table complète peut être plus rapide qu'une requête utilisant un index
-
Le nombre d'index dans une seule table ne dépasse pas 6
Ne créez pas d'index à colonne unique pour les champs à faible sélectivité
Utiliser pleinement les contraintes uniques
L'index ne contient pas plus de 5 champs (y compris les colonnes d'inclusion)
Ne créez pas d'index à colonne unique pour les champs à faible sélectivité
SQL SERVER a des exigences pour la sélectivité des champs d'index Si la sélectivité est trop faible, SQL SERVER abandonnera l'utilisation de
- Champs non adaptés à la création d'index : genre, 0/1, VRAI/FAUX
- Champs adaptés à la création d'index : ORDERID, UID, etc.
Le nombre d'index de table ne dépasse pas 6
Le nombre d'index de table ne doit pas dépasser 6 (cette règle n'est formulée par Ctrip DBA qu'après tests...)
-
Les index accélèrent les requêtes, mais affectent les performances d'écriture
- Requête SQL
-
Il est interdit d'effectuer des opérations complexes dans la base de données
SELECT *
est interdit N'utilisez pas de fonctions ou de calculs sur des colonnes indexées
Les curseurs sont interdits
Déclencheurs interdits
Il est interdit de préciser l'index
Le type de variable/paramètre/champ associé doit être cohérent avec le type de champ
Requête paramétrée
Limiter le nombre de JOINs
Limiter la longueur des instructions SQL et le nombre de clauses IN
Essayez d'éviter les opérations de transactions importantes
La désactivation des informations sur le nombre de lignes concernées renvoie
Sauf nécessité, l'instruction SELECT doit être ajoutée avec NOLOCK
Utilisez UNION ALL pour remplacer UNION
Interrogez de grandes quantités de données à l'aide de la pagination ou de TOP
Restrictions récursives au niveau des requêtes
PAS EXISTE remplace PAS DANS
Tables temporaires et variables de table
Utilisez des variables locales pour sélectionner un plan d'exécution moyen
Essayez d'éviter d'utiliser l'opérateur OR
Ajouter un mécanisme de gestion des exceptions de transaction
Les colonnes de sortie utilisent le format de dénomination en deux parties
Il est interdit d'effectuer des opérations complexes dans la base de données
Analyse XML
Comparaison de similarité de chaînes
Recherche de chaîne (Charindex)
Des opérations complexes sont réalisées côté programme
Il est interdit d'utiliser SELECT *
Réduisez la consommation de mémoire et la bande passante du réseau
Donnez à l'optimiseur de requêtes une chance de lire les colonnes requises de l'index
Lorsque la structure de la table change, il est facile de provoquer des erreurs de requête
Il est interdit d'utiliser des fonctions ou des calculs sur les colonnes d'index
Il est interdit d'utiliser des fonctions ou des calculs sur les colonnes d'index
Dans la clause Where, si l'index fait partie de la fonction, l'optimiseur n'utilisera plus l'index et utilisera un parcours complet de la table
En supposant qu'il existe un index construit sur le champ Col1, l'index ne sera pas utilisé dans les scénarios suivants :
ABS[Col1]=1
[Col1]+1>9
Donnons un autre exemple

Une requête comme celle ci-dessus ne pourra pas utiliser l'index PrintTime sur la table O_OrderProcess, nous utilisons donc la requête suivante SQL
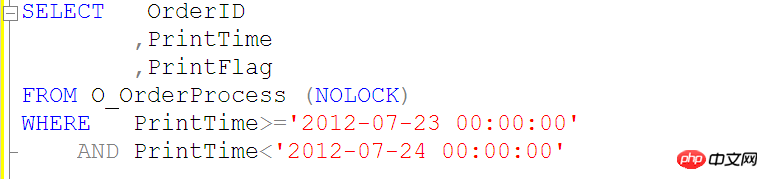
Il est interdit d'utiliser des fonctions ou des calculs sur les colonnes d'index
En supposant qu'il existe un index construit sur le champ Col1, les scénarios suivants utiliseront l'index :
[Col1]=3.14
[Col1]>100
[Col1] ENTRE 0 ET 99
[Col1] LIKE 'abc%'
[Col1] IN(2,3,5,7)
Problème d'indexation de la requête LIKE
1.[Col1] comme « abc% » –index seek Ceci utilise une requête d'index
2.[Col1] comme « %abc% » –index scan Et cela n'utilise pas de requête d'index
3.[Col1] comme « %abc » –index scan Cela n'utilise pas non plus de requête d'index
Je pense qu'à partir des trois exemples ci-dessus, tout le monde devrait comprendre qu'il est préférable de ne pas utiliser de correspondance floue devant la condition LIKE, sinon la requête d'index ne sera pas utilisée.
L'utilisation de curseurs est interdite
Les bases de données relationnelles conviennent aux opérations d'ensemble, c'est-à-dire que les opérations d'ensemble sont effectuées sur l'ensemble de résultats déterminé par la clause WHERE et la colonne de sélection. Le curseur est un moyen de fournir des opérations non définies. Dans des circonstances normales, la fonction implémentée par un curseur est souvent équivalente à la fonction implémentée par une boucle côté client.
Le curseur place l'ensemble de résultats dans la mémoire du serveur et traite les enregistrements un par un via une boucle, ce qui consomme beaucoup de ressources de base de données (en particulier les ressources de mémoire et de verrouillage).
(De plus, les curseurs sont vraiment compliqués et difficiles à utiliser, alors utilisez-les le moins possible)
L'utilisation de déclencheurs est interdite
Le déclencheur est opaque pour l'application (le niveau application ne sait pas quand le déclencheur sera déclenché, ni quand il se produira, ce qui semble inexplicable...)
Il est interdit de préciser l'index dans la requête
With(index=XXX) (Dans les requêtes, nous utilisons généralement With(index=XXX) pour spécifier l'index)
À mesure que les données changent, les performances de l'index spécifiées par l'instruction de requête peuvent ne pas être optimales
L'index doit être transparent pour l'application. Si l'index spécifié est supprimé, cela provoquera une erreur de requête, ce qui n'est pas propice au dépannage
L'index nouvellement créé ne peut pas être utilisé immédiatement par l'application et doit être publié pour prendre effet
Le type de variable/paramètre/champ associé doit être cohérent avec le type de champ (c'est quelque chose auquel je n'avais pas prêté beaucoup d'attention auparavant)
Évitez la consommation supplémentaire de CPU liée à la conversion de type, ce qui est particulièrement grave pour les analyses de tables volumineuses
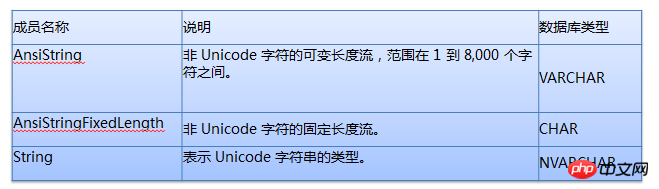
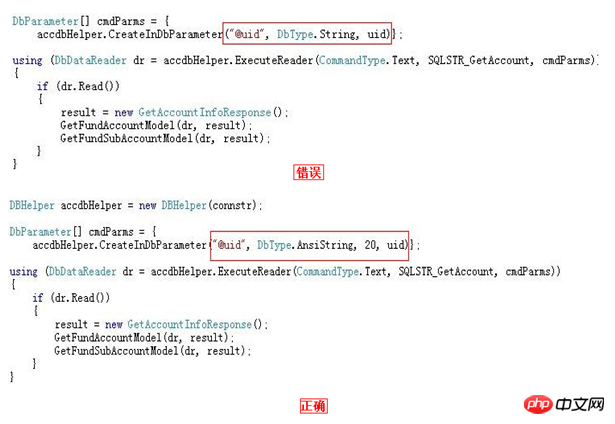
Après avoir regardé les deux photos ci-dessus, je ne pense pas avoir besoin d’expliquer, tout le monde devrait déjà le savoir.
Si le type du champ de la base de données est VARCHAR, il est préférable de spécifier le type comme AnsiString dans l'application et de spécifier clairement sa longueur
Si le type de champ de base de données est CHAR, il est préférable de spécifier le type comme AnsiStringFixedLength dans l'application et de spécifier clairement sa longueur
Si le type de champ de la base de données est NVARCHAR, il est préférable de spécifier le type comme String dans l'application et de préciser clairement sa longueur
Requête paramétrée
La requête SQL peut être paramétrée des manières suivantes :
sp_executesql
Requêtes préparées
Procédures stockées
Laissez-moi vous expliquer avec une photo, haha.


Limiter le nombre de JOIN
Le nombre de JOIN de table dans une seule instruction SQL ne peut pas dépasser 5
Trop de JOIN entraîneront l'analyseur de requêtes dans le mauvais plan d'exécution
Trop de JOIN consomment beaucoup d'argent lors de l'élaboration du plan d'exécution
Limiter le nombre de conditions dans la clause IN
Inclure un très grand nombre de valeurs (milliers) dans la clause IN peut consommer des ressources et renvoyer l'erreur 8623 ou 8632. Le nombre de conditions dans la clause IN doit être limité à 100
Essayez d'éviter les opérations de transactions importantes
Démarrez les transactions uniquement lorsque les données doivent être mises à jour, réduisant ainsi le temps de maintien du verrouillage des ressources
Ajouter un mécanisme de prétraitement de capture des exceptions de transaction
L'utilisation de transactions distribuées sur la base de données est interdite
Utilisez des images pour expliquer
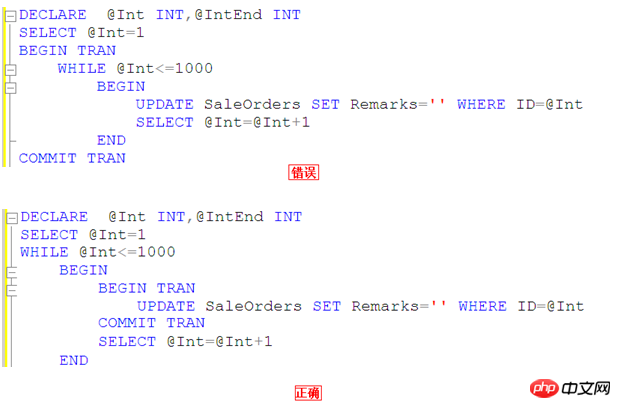
En d'autres termes, nous ne devrions pas valider la transaction une fois que les 1 000 lignes de données ont été mises à jour. Demandez-vous si vous monopolisez les ressources lors de la mise à jour de ces 1 000 lignes de données, ce qui empêcherait le traitement d'autres transactions.
Fermez les informations sur le nombre de lignes concernées et revenez
Affichez Set Nocount On dans l'instruction SQL, annulez le retour des informations sur le nombre de lignes concernées et réduisez le trafic réseau
Sauf nécessité, l'instruction SELECT doit être ajoutée avec NOLOCK
Sauf si nécessaire, essayez de faire en sorte que toutes les instructions sélectionnées ajoutent NOLOCK
Spécifie que les lectures incorrectes sont autorisées. Les verrous partagés ne sont pas émis pour empêcher d'autres transactions de modifier les données lues par la transaction en cours, et les verrous exclusifs définis par d'autres transactions n'empêcheront pas la transaction en cours de lire les données verrouillées. Autoriser les lectures incorrectes peut entraîner davantage d'opérations simultanées, mais le coût réside dans les modifications de données qui seront annulées par d'autres transactions après la lecture. Cela pourrait entraîner une erreur de votre transaction, afficher les données utilisateur qui n'ont jamais été validées ou amener l'utilisateur à voir l'enregistrement deux fois (ou à ne pas voir l'enregistrement du tout)
Utilisez UNION ALL pour remplacer UNION
Utilisez UNION ALL pour remplacer UNION
UNION désorganisera le jeu de résultats SQL et augmentera la consommation de CPU, de mémoire, etc.
Pour interroger de grandes quantités de données, utilisez la pagination ou TOP
Limiter raisonnablement le nombre de retours d'enregistrements pour éviter les goulots d'étranglement dans les E/S et la bande passante du réseau
Restrictions récursives au niveau des requêtes
Utilisez MAXRECURSION pour empêcher le CTE récursif déraisonnable d'entrer dans une boucle infinie
Tables temporaires et variables de table
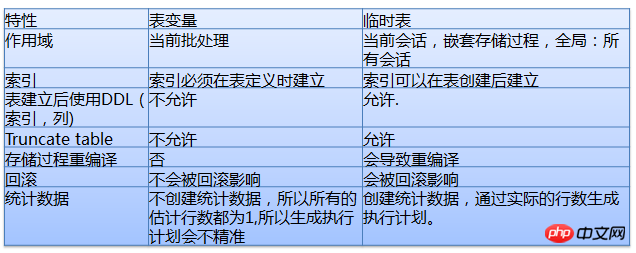
Utilisez des variables locales pour sélectionner un plan d'exécution moyen
Dans une procédure stockée ou une requête, l'accès à une table avec une répartition des données très inégale entraîne souvent l'utilisation par la procédure stockée ou la requête d'un plan d'exécution sous-optimal, voire médiocre, provoquant des problèmes tels qu'un processeur élevé et un grand nombre de lectures d'E/S. éviter les mauvais plans d’exécution.
En utilisant des variables locales, SQL ne connaît pas la valeur de cette variable locale lors de la compilation. À ce stade, SQL « devinera » une valeur de retour basée sur la distribution générale des données dans la table. Quelles que soient les valeurs de variable que l'utilisateur remplace lors de l'appel de la procédure stockée ou de l'instruction, le plan généré est le même. Un tel plan est généralement plus modéré et n’est pas nécessairement le meilleur plan, mais ce n’est généralement pas non plus le pire plan
Si la variable locale de la requête utilise l'opérateur d'inégalité, l'analyseur de requête utilise un simple calcul de 30 % pour estimer
Lignes estimées =(Total des lignes * 30)/100
Si la variable locale de la requête utilise l'opérateur d'égalité, l'analyseur de requête utilise : la précision * le nombre total d'enregistrements de la table à estimer
Lignes estimées = Densité * Total des lignes
Essayez d'éviter d'utiliser l'opérateur OR
Pour l'opérateur OR, une analyse complète de la table est généralement utilisée. Envisagez de la diviser en plusieurs requêtes et d'implémenter UNION/UNION ALL. Ici, vous devez confirmer que la requête peut accéder à l'index et renvoyer un ensemble de résultats plus petit
Ajouter un mécanisme de gestion des exceptions de transaction L'application doit bien gérer les accidents et effectuer une restauration à temps.
Définir les propriétés de connexion « définir xact_abort sur »
- Lire et écrire la séparation
- Découplage de schéma
- Cycle de vie des données
- La séparation de la lecture et de l'écriture est envisagée dès le début de la conception, même si la même bibliothèque est lue et écrite, elle est propice à une expansion rapide
- Selon les caractéristiques de lecture, les lectures sont divisées en lectures en temps réel et lectures différées, correspondant respectivement à la bibliothèque d'écriture et à la bibliothèque de lecture
-
- La séparation de la lecture et de l'écriture devrait envisager de basculer automatiquement du côté de l'écriture lorsque la lecture n'est pas disponible
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!