
Maison >Java >javaDidacticiel >Analyse approfondie des problèmes d'encodage chinois dans Java Web
Analyse approfondie des problèmes d'encodage chinois dans Java Web
- 巴扎黑original
- 2017-04-30 10:05:341427parcourir
Contexte :
Les problèmes de codage ont toujours troublé les développeurs de programmes, en particulier en Java, car Java est un langage multiplateforme et il y a beaucoup de commutations entre le codage sur différentes plates-formes. Ensuite, nous présenterons les causes profondes des problèmes d'encodage Java ; les différences entre plusieurs formats d'encodage souvent rencontrés en Java ; les scénarios qui nécessitent souvent un encodage en Java ; l'analyse des causes possibles des problèmes d'encodage en chinois dans le développement de Java Web ; comment contrôler le format d'encodage d'une requête HTTP ; comment éviter les problèmes d'encodage chinois, etc.
1. Plusieurs formats d'encodage courants
1.1 Pourquoi devrions-nous encoder
La plus petite unité de stockage d'informations dans un ordinateur est de 1 octet, soit 8 bits, donc la plage de caractères pouvant être représentée est de 0 à 255.
Il y a trop de symboles à représenter et ne peuvent pas être entièrement représentés sur 1 octet.
1.2 Comment traduire
Les ordinateurs offrent une variété de méthodes de traduction, les plus courantes incluent ASCII, ISO-8859-1, GB2312, GBK, UTF-8, UTF-16, etc. Ceux-ci stipulent tous les règles de conversion. Selon ces règles, l'ordinateur peut représenter correctement nos personnages. Ces formats d'encodage sont présentés ci-dessous :
-
Code ASCII
Il y en a 128 au total, représentés par les 7 bits inférieurs de 1 octet, 0 ~ 31 sont des caractères de contrôle tels que le saut de ligne, le retour chariot, la suppression, etc., 32 ~ 126 sont des caractères d'impression, qui peuvent être saisis via le clavier et affiché.
-
ISO-8859-1
128 caractères ne suffisent évidemment pas, c'est pourquoi l'organisation ISO s'est développée sur la base de l'ASCII. Ils vont de ISO-8859-1 à ISO-8859-15. La première couvre la plupart des caractères et est la plus largement utilisée. ISO-8859-1 est toujours un codage sur un seul octet, qui peut représenter un total de 256 caractères.
-
GB2312
Il s'agit d'un codage sur deux octets, et la plage de codage totale est A1 ~ F7, où A1 ~ A9 est la zone de symboles, contenant un total de 682 symboles ; B0 ~ F7 est la zone de caractères chinois, contenant 6763 caractères chinois ;
-
GBk
GBK est la "Spécification d'extension du code interne des caractères chinois", qui est une extension de GB2312. Sa plage de codage est 8140 ~ FEFE (en supprimant XX7F). Il y a un total de 23940 points de code, qui peuvent représenter 21003 caractères chinois. avec le codage GB2312 et n'aura pas de caractères tronqués.
-
UTF-16
Il définit spécifiquement la manière dont les caractères Unicode sont accessibles sur l'ordinateur. UTF-16 utilise deux octets pour représenter le format de conversion Unicode. Il utilise une méthode de représentation de longueur fixe, c'est-à-dire que quel que soit le caractère, il est représenté par deux octets. Deux octets font 16 bits, c'est donc ce qu'on appelle UTF-16. Il est très pratique de représenter des caractères. Deux octets ne représentent pas un caractère, ce qui simplifie grandement les opérations sur les chaînes.
-
UTF-8
Bien qu'il soit simple et pratique pour UTF-16 d'utiliser uniformément deux octets pour représenter un caractère, une grande partie des caractères peut être représentée par un octet. S'il est représenté par deux octets, l'espace de stockage sera doublé. la bande passante du réseau est limitée. Dans ce cas, le trafic de transmission réseau sera augmenté. UTF-8 utilise une technologie de longueur variable. Chaque zone de codage a des longueurs de caractères différentes. Différents types de caractères peuvent être composés de 1 à 6 octets.
UTF-8 a les règles d'encodage suivantes :
S'il fait 1 octet et que le bit le plus élevé (8ème bit) est 0, cela signifie qu'il s'agit d'un caractère ASCII (00 ~ 7F)
S'il s'agit de 1 octet, en commençant par 11, le nombre de 1 consécutifs indique le nombre d'octets de ce caractère
S'il fait 1 octet, en commençant par 10, cela signifie que ce n'est pas le premier octet, et vous devez attendre avec impatience d'obtenir le premier octet du caractère actuel
2. Scénarios nécessitant du codage en Java
2.1 Encodages présents dans les opérations d'E/S
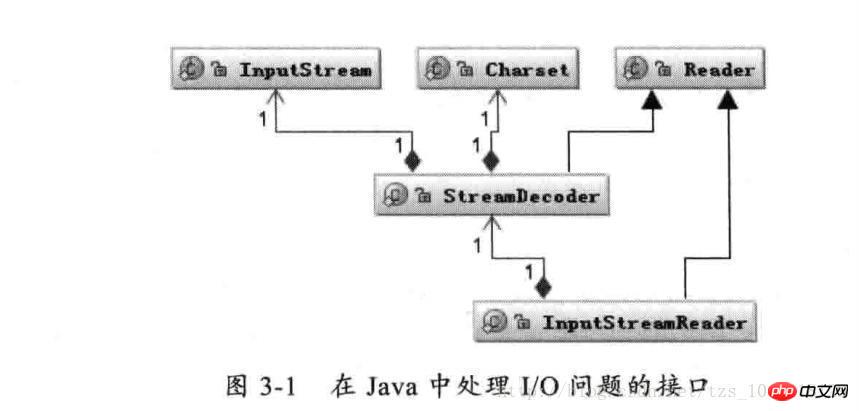
Comme indiqué ci-dessus : la classe Reader est la classe parent pour la lecture des caractères dans les E/S Java, et la classe InputStream est la classe parent pour la lecture des octets. La classe InputStreamReader est le pont qui associe les octets aux caractères. pendant le processus d'E/S. Il gère la conversion des octets lus en caractères et confie à StreamDecoder la mise en œuvre du décodage d'octets spécifiques en caractères. Pendant le processus de décodage de StreamDecoder, le format de codage Charset doit être spécifié par l'utilisateur. Il convient de noter que si vous ne spécifiez pas Charset, le caractère par défaut défini dans l'environnement local sera utilisé. Par exemple, le codage GBK sera utilisé dans l'environnement chinois.
Par exemple, le morceau de code suivant implémente la fonction de lecture et d'écriture de fichiers :
String file = "c:/stream.txt";
String charset = "UTF-8";
// 写字符换转成字节流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(
outputStream, charset);
try {
writer.write("这是要保存的中文字符");
} finally {
writer.close();
}
// 读取字节转换成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buffer, 0, count);
}
} finally {
reader.close();
}Lorsque notre application implique des opérations d'E/S, tant que nous prêtons attention à spécifier un jeu de caractères Charset de codage et de décodage unifié, il n'y aura généralement pas de problèmes de code tronqué.
2.2 Codage en opérations de mémoire
Effectuez une conversion de type de données de caractères en octets en mémoire.
1、String 类提供字符串转换到字节的方法,也支持将字节转换成字符串的构造函数。
String s = "字符串";
byte[] b = s.getBytes("UTF-8");
String n = new String(b, "UTF-8");2、Charset 提供 encode 与 decode,分别对应 char[] 到 byte[] 的编码 和 byte[] 到 char[] 的解码。
Charset charset = Charset.forName("UTF-8");
ByteBuffer byteBuffer = charset.encode(string);
CharBuffer charBuffer = charset.decode(byteBuffer);...
3、在 Java 中如何编解码
Java 编码类图
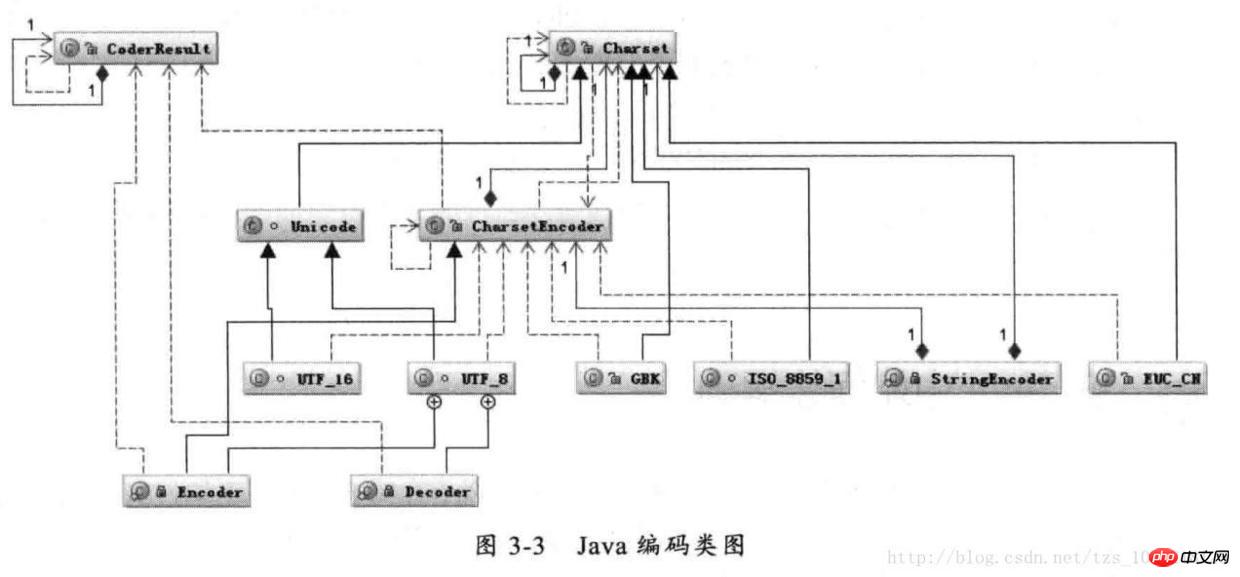
首先根据指定的 charsetName 通过 Charset.forName(charsetName) 设置 Charset 类,然后根据 Charset 创建 CharsetEncoder 对象,再调用 CharsetEncoder.encode 对字符串进行编码,不同的编码类型都会对应到一个类中,实际的编码过程是在这些类中完成的。下面是 String. getBytes(charsetName) 编码过程的时序图
Java 编码时序图
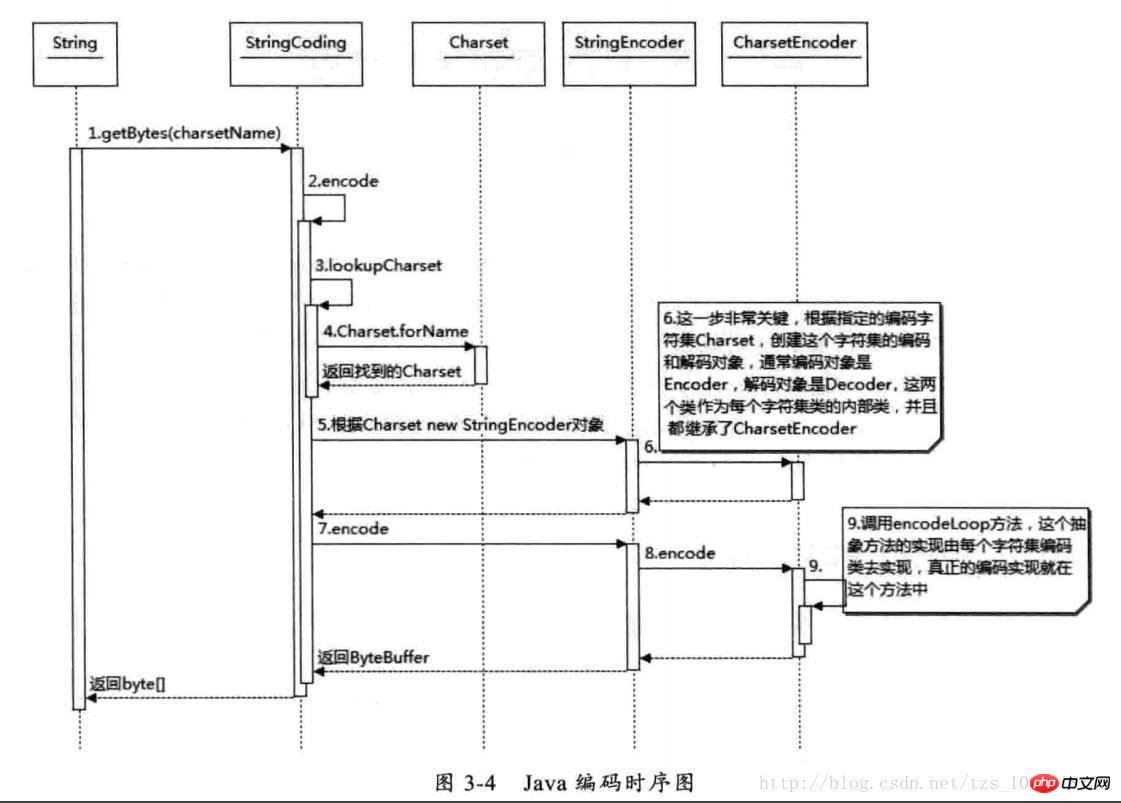
从上图可以看出根据 charsetName 找到 Charset 类,然后根据这个字符集编码生成 CharsetEncoder,这个类是所有字符编码的父类,针对不同的字符编码集在其子类中定义了如何实现编码,有了 CharsetEncoder 对象后就可以调用 encode 方法去实现编码了。这个是 String.getBytes 编码方法,其它的如 StreamEncoder 中也是类似的方式。
经常会出现中文变成“?”很可能就是错误的使用了 ISO-8859-1 这个编码导致的。中文字符经过 ISO-8859-1 编码会丢失信息,通常我们称之为“黑洞”,它会把不认识的字符吸收掉。由于现在大部分基础的 Java 框架或系统默认的字符集编码都是 ISO-8859-1,所以很容易出现乱码问题,后面将会分析不同的乱码形式是怎么出现的。
几种编码格式的比较
对中文字符后面四种编码格式都能处理,GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
4、在 Java Web 中涉及的编解码
对于使用中文来说,有 I/O 的地方就会涉及到编码,前面已经提到了 I/O 操作会引起编码,而大部分 I/O 引起的乱码都是网络 I/O,因为现在几乎所有的应用程序都涉及到网络操作,而数据经过网络传输都是以字节为单位的,所以所有的数据都必须能够被序列化为字节。在 Java 中数据被序列化必须继承 Serializable 接口。
一段文本它的实际大小应该怎么计算,我曾经碰到过一个问题:就是要想办法压缩 Cookie 大小,减少网络传输量,当时有选择不同的压缩算法,发现压缩后字符数是减少了,但是并没有减少字节数。所谓的压缩只是将多个单字节字符通过编码转变成一个多字节字符。减少的是 String.length(),而并没有减少最终的字节数。例如将“ab”两个字符通过某种编码转变成一个奇怪的字符,虽然字符数从两个变成一个,但是如果采用 UTF-8 编码这个奇怪的字符最后经过编码可能又会变成三个或更多的字节。同样的道理比如整型数字 1234567 如果当成字符来存储,采用 UTF-8 来编码占用 7 个 byte,采用 UTF-16 编码将会占用 14 个 byte,但是把它当成 int 型数字来存储只需要 4 个 byte 来存储。所以看一段文本的大小,看字符本身的长度是没有意义的,即使是一样的字符采用不同的编码最终存储的大小也会不同,所以从字符到字节一定要看编码类型。
我们能够看到的汉字都是以字符形式出现的,例如在 Java 中“淘宝”两个字符,它在计算机中的数值 10 进制是 28120 和 23453,16 进制是 6bd8 和 5d9d,也就是这两个字符是由这两个数字唯一表示的。Java 中一个 char 是 16 个 bit 相当于两个字节,所以两个汉字用 char 表示在内存中占用相当于四个字节的空间。
这两个问题搞清楚后,我们看一下 Java Web 中那些地方可能会存在编码转换?
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接受到 HTTP 请求后要解析 HTTP 协议,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都可能存在编码问题,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。这些过程如下图所示:
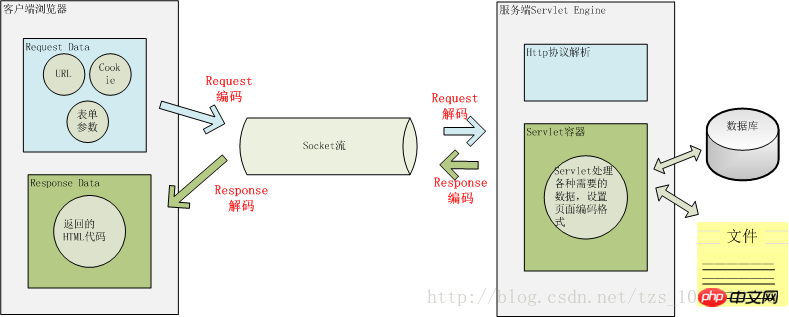
一次 HTTP 请求的编码示例
4.1 URL 的编解码
用户提交一个 URL,这个 URL 中可能存在中文,因此需要编码,如何对这个 URL 进行编码?根据什么规则来编码?有如何来解码?如下图一个 URL:
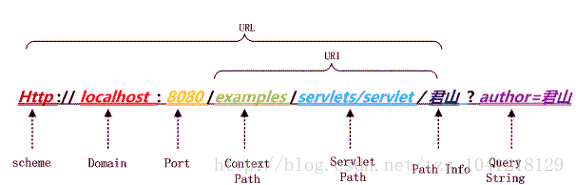
上图中以 Tomcat 作为 Servlet Engine 为例,它们分别对应到下面这些配置文件中:
Port 对应在 Tomcat 的 2d40a7d47a79d09f1e13ed7afa569ba8 中配置,而 Context Path 在 cc9811071a6b9ec4ee8fd6740dade5e9 中配置,Servlet Path 在 Web 应用的 web.xml 中的
<servlet-mapping>
<servlet-name>junshanExample</servlet-name>
<url-pattern>/servlets/servlet/*</url-pattern>
</servlet-mapping>66e1775cbd9d5002635ae3285442ba88 中配置,PathInfo 是我们请求的具体的 Servlet,QueryString 是要传递的参数,注意这里是在浏览器里直接输入 URL 所以是通过 Get 方法请求的,如果是 POST 方法请求的话,QueryString 将通过表单方式提交到服务器端。
上图中 PathInfo 和 QueryString 出现了中文,当我们在浏览器中直接输入这个 URL 时,在浏览器端和服务端会如何编码和解析这个 URL 呢?为了验证浏览器是怎么编码 URL 的我选择的是360极速浏览器并通过 Postman 插件观察我们请求的 URL 的实际的内容,以下是 URL:
HTTP://localhost:8080/examples/servlets/servlet/君山?author=君山
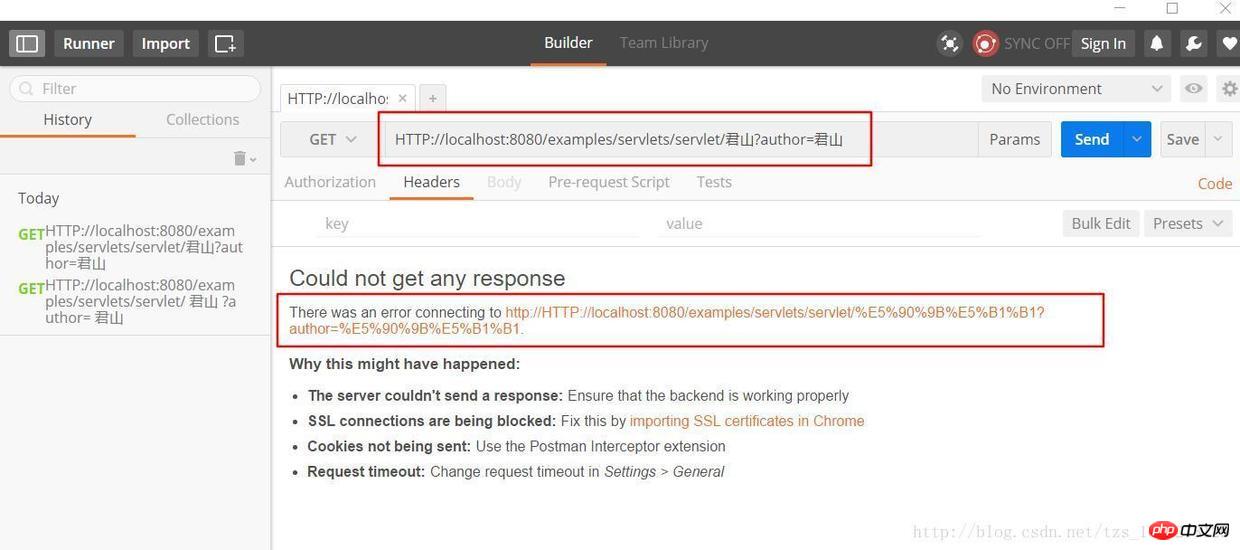
君山的编码结果是:e5 90 9b e5 b1 b1,和《深入分析 Java Web 技术内幕》中的结果不一样,这是因为我使用的浏览器和插件和原作者是有区别的,那么这些浏览器之间的默认编码是不一样的,原文中的结果是:

君山的编码结果分别是:e5 90 9b e5 b1 b1,be fd c9 bd,查阅上一届的编码可知,PathInfo 是 UTF-8 编码而 QueryString 是经过 GBK 编码,至于为什么会有“%”?查阅 URL 的编码规范 RFC3986 可知浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成 16 进制数字然后将每个 16 进制表示的字节前加上“%”,所以最终的 URL 就成了上图的格式了。
从上面测试结果可知浏览器对 PathInfo 和 QueryString 的编码是不一样的,不同浏览器对 PathInfo 也可能不一样,这就对服务器的解码造成很大的困难,下面我们以 Tomcat 为例看一下,Tomcat 接受到这个 URL 是如何解码的。
解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在 org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length -
cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(),
cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}从上面的代码中可以知道对 URL 的 URI 部分进行解码的字符集是在 connector 的 fb5e5a423fbf569b89d2849dcbd1c1d3 中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。所以如果有中文 URL 时最好把 URIEncoding 设置成 UTF-8 编码。
Comment analyser QueryString ? La QueryString de la requête HTTP GET et les paramètres de formulaire de la requête HTTP POST sont enregistrés en tant que paramètres et les valeurs des paramètres sont obtenues via request.getParameter. Ils sont décodés lors du premier appel de la méthode request.getParameter. Lorsque la méthode request.getParameter est appelée, elle appellera la méthode parseParameters de org.apache.catalina.connector.Request. Cette méthode décodera les paramètres transmis par GET et POST, mais leurs jeux de caractères de décodage peuvent être différents. Le décodage du formulaire POST sera introduit plus tard. Où est défini le jeu de caractères de décodage de QueryString ? Il est transmis au serveur via l'en-tête HTTP et se trouve également dans l'URL. Est-ce le même que le jeu de caractères de décodage de l'URI ? D'après les navigateurs précédents utilisant des formats d'encodage différents pour PathInfo et QueryString, on peut deviner que les jeux de caractères décodés ne seront certainement pas cohérents. En effet, le jeu de caractères de décodage de QueryString est soit le Charset défini dans ContentType dans l'en-tête, soit l'ISO-8859-1 par défaut. Pour utiliser l'encodage défini dans ContentType, vous devez définir le 843db55229dcc6a5df7f192aea7df3be useBodyEncodingForURI est défini sur true. Le nom de cet élément de configuration est un peu déroutant. Il n'utilise pas BodyEncoding pour décoder l'intégralité de l'URI, mais utilise uniquement BodyEncoding pour décoder QueryString. Cela mérite une attention particulière.
À en juger par le processus d'encodage et de décodage d'URL ci-dessus, il est relativement compliqué et nous ne pouvons pas entièrement contrôler l'encodage et le décodage dans l'application. Par conséquent, nous devrions essayer d'éviter d'utiliser des caractères non-ASCII dans l'URL de notre application, sinon cela se produirait. sera très difficile. Vous pouvez rencontrer des caractères tronqués. Bien sûr, il est préférable de définir les deux paramètres URIEncoding et useBodyEncodingForURI dans 5de43e088bab17594573baec6d1f4ce2
4.2 Encodage et décodage de l'en-tête HTTP
Lorsque le client initie une requête HTTP, en plus de l'URL ci-dessus, il peut également transmettre d'autres paramètres dans l'en-tête tels que Cookie, redirectPath, etc. Ces valeurs définies par l'utilisateur peuvent également avoir des problèmes d'encodage. Comment Tomcat les décode-t-il. ?
Le décodage des éléments de l'en-tête est également effectué en appelant request.getHeader. Si l'élément d'en-tête demandé n'est pas décodé, la méthode toString de MessageBytes est appelée. Le codage par défaut utilisé par cette méthode pour la conversion d'octet en caractère est également ISO-8859. -1. , et nous ne pouvons pas définir d'autres formats de décodage de l'en-tête, donc si vous définissez le décodage des caractères non-ASCII dans l'en-tête, il y aura certainement des caractères tronqués.
La même chose est vraie lorsque nous ajoutons un en-tête. Ne transmettez pas de caractères non-ASCII dans l'en-tête. Si nous devons les transmettre, nous pouvons d'abord encoder ces caractères avec org.apache.catalina.util.URLEncoder, puis les ajouter à l'en-tête. . De cette façon, les informations ne seront pas perdues lors du transfert du navigateur vers le serveur. Ce serait bien si nous les décodions en fonction du jeu de caractères correspondant lorsque nous voulons accéder à ces éléments.
4.3 Codage et décodage du formulaire POST
Comme mentionné précédemment, le décodage des paramètres soumis par le formulaire POST se produit lorsque request.getParameter est appelé pour la première fois. La méthode de transfert des paramètres du formulaire POST est différente de QueryString. Elle est transmise au serveur via le BODY de HTTP. Lorsque nous cliquons sur le bouton Soumettre sur la page, le navigateur encodera d'abord les paramètres remplis dans le formulaire selon le format d'encodage Charset de ContentType, puis les soumettra au serveur. Le serveur utilisera également le caractère défini dans ContentType pour le décodage. Par conséquent, les paramètres soumis via le formulaire POST ne posent généralement pas de problèmes, et ce codage de jeu de caractères est défini par nous-mêmes et peut être défini via request.setCharacterEncoding(charset).
De plus, pour les paramètres de type multipart/form-data, c'est-à-dire que le codage du fichier téléchargé utilise également le codage du jeu de caractères défini par ContentType. Il convient de noter que le fichier téléchargé est transmis au répertoire temporaire local du serveur dans un octet. stream.Ce processus n'implique pas de codage de caractères, mais le codage réel ajoute le contenu du fichier aux paramètres. S'il ne peut pas être codé en utilisant ce codage, le codage par défaut ISO-8859-1 sera utilisé.
4.4 Encodage et décodage HTTP BODY
Lorsque les ressources demandées par l'utilisateur ont été obtenues avec succès, le contenu sera renvoyé au navigateur client via Réponse. Ce processus doit d'abord être codé puis décodé par le navigateur. Le jeu de caractères d'encodage et de décodage de ce processus peut être défini via response.setCharacterEncoding, qui remplacera la valeur de request.getCharacterEncoding et reviendra au client via le Content-Type de l'en-tête. Lorsque le navigateur reçoit le flux de socket renvoyé, il. transmettra le jeu de caractères Content-Type à décoder. Si le Content-Type dans l'en-tête HTTP renvoyé ne définit pas le jeu de caractères, le navigateur le décodera en fonction du df46de9193954878cfb5b3c593de8396
Velocity 模版设置编码格式:
services.VelocityService.input.encoding=UTF-8
JSP 设置编码格式:
b17dd5d8ec994687dd967facddfb5350
访问数据库都是通过客户端 JDBC 驱动来完成,用 JDBC 来存取数据要和数据的内置编码保持一致,可以通过设置 JDBC URL 来制定如 MySQL:url="jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK"。
5、常见问题分析
下面看一下,当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
5.1 中文变成了看不懂的字符
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”编码过程如下图所示:
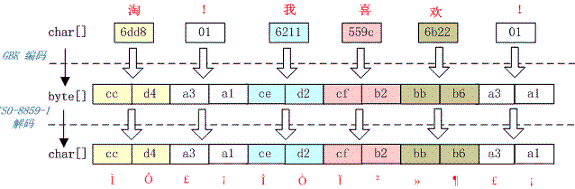
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
5.2 一个汉字变成一个问号
例如,字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示:
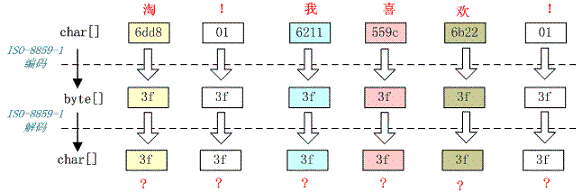
将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
5.3 一个汉字变成两个问号
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示:
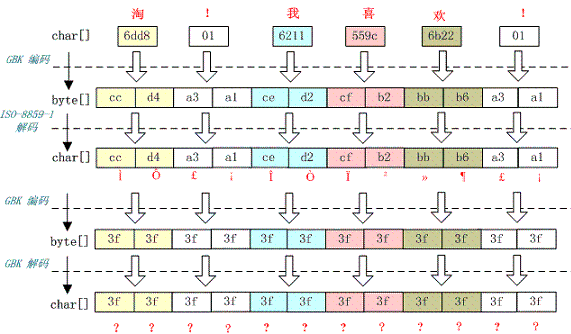
这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。
5.4 一种不正常的正确编码
还有一种情况是在我们通过 request.getParameter 获取参数值时,当我们直接调用
String value = request.getParameter(name); 会出现乱码,但是如果用下面的方式
String value = String(request.getParameter(name).getBytes(" ISO-8859-1"), "GBK");
解析时取得的 value 会是正确的汉字字符,这种情况是怎么造成的呢?
看下如所示:
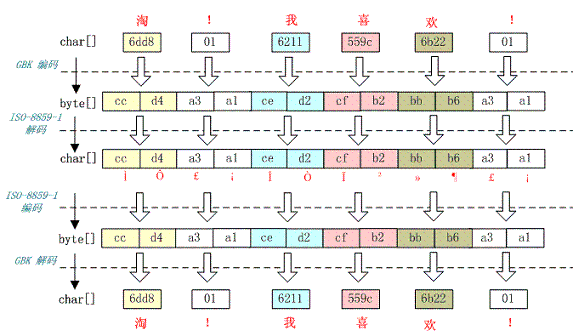
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat 的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
6、总结
本文首先总结了几种常见编码格式的区别,然后介绍了支持中文的几种编码格式,并比较了它们的使用场景。接着介绍了 Java 那些地方会涉及到编码问题,已经 Java 中如何对编码的支持。并以网络 I/O 为例重点介绍了 HTTP 请求中的存在编码的地方,以及 Tomcat 对 HTTP 协议的解析,最后分析了我们平常遇到的乱码问题出现的原因。
En résumé, pour résoudre le problème chinois, nous devons d'abord déterminer où se produira le codage caractère à octet et le décodage octet à caractère. Les endroits les plus courants sont la lecture et le stockage des données sur le disque, ou les données transitant par le réseau. . transmission. Ensuite, pour ces endroits, déterminez comment le framework ou le système qui exploite ces données contrôle l'encodage, définissez correctement le format d'encodage et évitez d'utiliser le format d'encodage par défaut du logiciel ou de la plate-forme du système d'exploitation.
Remarque : La majeure partie de l'article fait référence au troisième chapitre du livre "Insider Java Web Technology". Je l'ai supprimé. Assurez-vous d'indiquer la source lors de la réimpression.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!