
Maison >développement back-end >Tutoriel Python >Un cours qui vous apprend à utiliser Python pour explorer w3shcool et l'enregistrer dans des exemples de code local
Un cours qui vous apprend à utiliser Python pour explorer w3shcool et l'enregistrer dans des exemples de code local

- Y2Joriginal
- 2017-04-27 11:42:032250parcourir
Cet article présente principalement la méthode d'analyse de Python en explorant le cours JQuery de w3shcool et en l'enregistrant localement. A une très bonne valeur de référence. Jetons un coup d'œil avec l'éditeur ci-dessous
J'ai été occupé à chercher un emploi récemment. Pendant mon temps libre, j'ai également trouvé des projets de robots pour mettre en pratique mes compétences et écrire du code. , mais j'ai besoin de m'entraîner davantage. Shushan a le travail routier est le chemin. Si vous avez des fosses de test, pouvez-vous me les présenter ? L'automatisation, les fonctions et les interfaces peuvent toutes être réalisées.
Tout d'abord, nous avons clairement défini nos besoins. De nombreux étudiants veulent voir certaines technologies alors qu'ils n'ont rien à faire. Par exemple, je veux voir la syntaxe de JQuery, mais je n'en ai pas. Internet maintenant, et je n'ai pas de livres électroniques sur mon téléphone portable. Vraiment, cela nous met mal à l'aise, alors ne vous inquiétez pas, je suis là pour répondre à vos besoins. Tout d'abord, votre besoin est d'obtenir la syntaxe de. JQuery, alors je vois ce besoin, j'ai un site qui répond, alors allons-y, allez analyser ce site. www.w3school.com.cn/jquery/jquery_syntax.asp Ceci est l'URL de syntaxe, http://www.w3school.com.cn/jquery/jquery_intro.asp Ceci est l'URL d'introduction, puis nous avons eu beaucoup d'analyses d'URL , notre www.w3school.com.cn/jquery est le même, alors analysons comment les obtenir dans l'interface. Nous pouvons voir qu'il y a une barre cible correspondante sur la droite, alors analysons-la
. 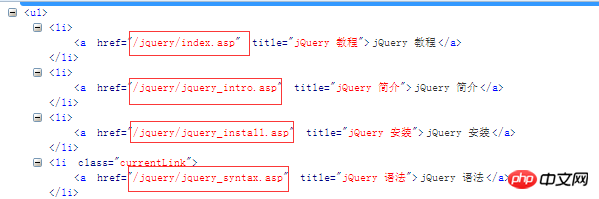
Jetons un coup d'œil à ces liens. Nous pouvons relier ces liens avec http://www.w3school.com.cn. Formez ensuite notre nouvelle url,
et ajoutez le code
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_textafin que nous puissions utiliser la fonction url_s pour obtenir tous nos liens.
['/jquery/index.asp', '/jquery/jquery_intro.asp', '/jquery/jquery_install.asp', '/jquery/jquery_syntax.asp', '/jquery/jquery_selectors.asp', '/jquery/jquery_events.asp', '/jquery/jquery_hide_show.asp', '/jquery/jquery_fade.asp', '/jquery/jquery_slide.asp', '/jquery/jquery_animate.asp', '/jquery/jquery_stop.asp', '/jquery/jquery_callback.asp', '/jquery/jquery_chaining.asp', '/jquery/jquery_dom_get.asp', '/jquery/jquery_dom_set.asp', '/jquery/jquery_dom_add.asp', '/jquery/jquery_dom_remove.asp', '/jquery/jquery_css_classes.asp', '/jquery/jquery_css.asp', '/jquery/jquery_dimensions.asp', '/jquery/jquery_traversing.asp', '/jquery/jquery_traversing_ancestors.asp', '/jquery/jquery_traversing_descendants.asp', '/jquery/jquery_traversing_siblings.asp', '/jquery/jquery_traversing_filtering.asp', '/jquery/jquery_ajax_intro.asp', '/jquery/jquery_ajax_load.asp', '/jquery/jquery_ajax_get_post.asp', '/jquery/jquery_noconflict.asp', '/jquery/jquery_examples.asp', '/jquery/jquery_quiz.asp', '/jquery/jquery_reference.asp', '/jquery/jquery_ref_selectors.asp', '/jquery/jquery_ref_events.asp', '/jquery/jquery_ref_effects.asp', '/jquery/jquery_ref_manipulation.asp', '/jquery/jquery_ref_attributes.asp', '/jquery/jquery_ref_css.asp', '/jquery/jquery_ref_ajax.asp', '/jquery/jquery_ref_traversing.asp', '/jquery/jquery_ref_data.asp', '/jquery/jquery_ref_dom_element_methods.asp', '/jquery/jquery_ref_core.asp', '/jquery/jquery_ref_prop.asp'], ['jQuery 教程', '', 'jQuery 教程', 'jQuery 简介', 'jQuery 安装', 'jQuery 语法', 'jQuery 选择器', 'jQuery 事件', '', 'jQuery 效果', '', 'jQuery 隐藏/显示', 'jQuery 淡入淡出', 'jQuery 滑动', 'jQuery 动画', 'jQuery stop()', 'jQuery Callback', 'jQuery Chaining', '', 'jQuery HTML', '', 'jQuery 获取', 'jQuery 设置', 'jQuery 添加', 'jQuery 删除', 'jQuery CSS 类', 'jQuery css()', 'jQuery 尺寸', '', 'jQuery 遍历', '', 'jQuery 遍历', 'jQuery 祖先', 'jQuery 后代', 'jQuery 同胞', 'jQuery 过滤', '', 'jQuery AJAX', '', 'jQuery AJAX 简介', 'jQuery 加载', 'jQuery Get/Post', '', 'jQuery 杂项', '', 'jQuery noConflict()', '', 'jQuery 实例', '', 'jQuery 实例', 'jQuery 测验', '', 'jQuery 参考手册', '', 'jQuery 参考手册', 'jQuery 选择器', 'jQuery 事件', 'jQuery 效果', 'jQuery 文档操作', 'jQuery 属性操作', 'jQuery CSS 操作', 'jQuery Ajax', 'jQuery 遍历', 'jQuery 数据', 'jQuery DOM 元素', 'jQuery 核心', 'jQuery 属性', '', ''])
C'est le nom de tous les liens et les modules de grammaire correspondants des liens correspondants. Ensuite, notre prochaine étape consiste à épisser les URL, en utilisant l'épissage str
['http://www.w3school.com.cn//jquery/index.asp', 'http://www.w3school.com.cn//jquery/jquery_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_install.asp', 'http://www.w3school.com.cn//jquery/jquery_syntax.asp', 'http://www.w3school.com.cn//jquery/jquery_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_events.asp', 'http://www.w3school.com.cn//jquery/jquery_hide_show.asp', 'http://www.w3school.com.cn//jquery/jquery_fade.asp', 'http://www.w3school.com.cn//jquery/jquery_slide.asp', 'http://www.w3school.com.cn//jquery/jquery_animate.asp', 'http://www.w3school.com.cn//jquery/jquery_stop.asp', 'http://www.w3school.com.cn//jquery/jquery_callback.asp', 'http://www.w3school.com.cn//jquery/jquery_chaining.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_get.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_set.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_add.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_remove.asp', 'http://www.w3school.com.cn//jquery/jquery_css_classes.asp', 'http://www.w3school.com.cn//jquery/jquery_css.asp', 'http://www.w3school.com.cn//jquery/jquery_dimensions.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_ancestors.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_descendants.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_siblings.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_filtering.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_load.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_get_post.asp', 'http://www.w3school.com.cn//jquery/jquery_noconflict.asp', 'http://www.w3school.com.cn//jquery/jquery_examples.asp', 'http://www.w3school.com.cn//jquery/jquery_quiz.asp', 'http://www.w3school.com.cn//jquery/jquery_reference.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_events.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_effects.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_manipulation.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_attributes.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_css.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_ajax.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_data.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_dom_element_methods.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_core.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_prop.asp']
Ensuite, nous avons toutes ces URL, puis analysons le texte de l'article.
L'analyse peut montrer que tous nos textes sont dans un id=maincontent, puis nous analysons directement la balise id=maincontent dans chaque interface, obtenons le document texte de réponse et l'enregistrons.
Donc tout notre code est le suivant :
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()Résultats
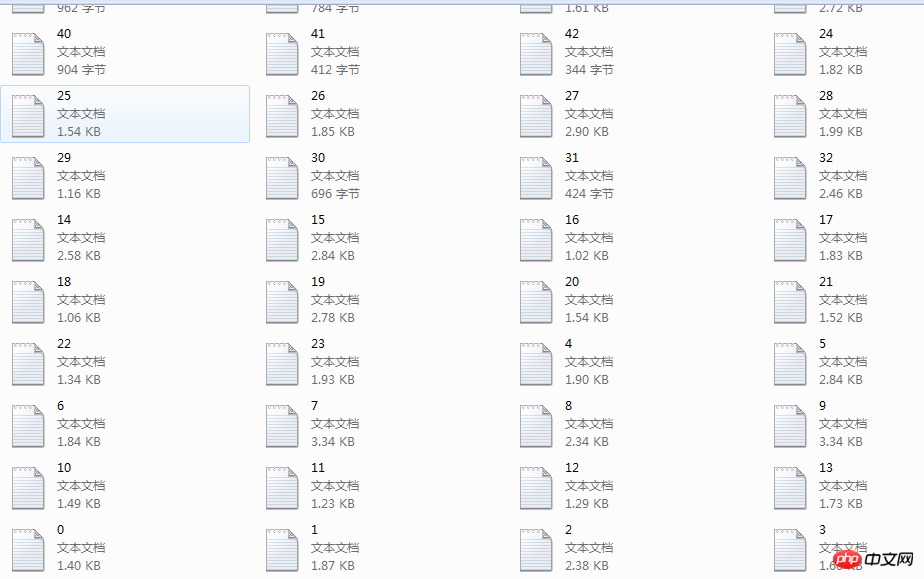
Ça y est, notre travail d'exploration Une fois que c'est fait, il ne reste plus que des réparations et des révisions mineures, et nous aurions dû terminer tout le contenu majeur.
En fait, le robot d'exploration de Python est encore très simple. Tant que nous pouvons analyser les éléments du site Web et découvrir les termes communs à tous les éléments, nous pouvons très bien analyser et résoudre nos problèmes
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!