
Maison >base de données >tutoriel mysql >Résoudre le problème d'optimisation SQL de CBO (explication détaillée avec images et textes)
Résoudre le problème d'optimisation SQL de CBO (explication détaillée avec images et textes)

- 怪我咯original
- 2017-04-05 11:26:336484parcourir
Aperçu de ce partage :
Quels sont les pièges de l'optimiseur CBO
Optimiseur CBO Solutions aux pièges
Renforcer l'audit SQL pour éliminer les problèmes de performances à leurs balbutiements
Partager la FAQ sur site
L'optimiseur CBO (Cost Based Optimizer) est actuellement largement utilisé dans Oracle. Il utilise des informations statistiques, la conversion de requêtes, etc. pour calculer les coûts des différents chemins d'accès possibles et génère une variété de plans d'exécution alternatifs. choisira le plan d’exécution le moins coûteux comme plan d’exécution optimal. Par rapport au RBO (Rule Based Optimizer) de l'ère « ancienne », il est évidemment plus conforme à la situation réelle de la base de données et peut s'adapter à davantage de scénarios d'application. Cependant, en raison de sa grande complexité, il existe de nombreux problèmes et bugs pratiques que CBO n'a pas résolus. Dans le processus d'optimisation quotidien, vous pouvez rencontrer des situations dans lesquelles vous ne pouvez pas suivre le plan d'exécution correct, quelle que soit la manière dont vous collectez des informations statistiques. , vous avez peut-être trompé CBO.
Ce partage utilise principalement les problèmes quotidiens courants des optimiseurs comme introduction pour explorer les solutions aux pièges du CBO.
1. Quels sont les pièges de l'optimiseur CBO
Tout d'abord, jetons un coup d'œil aux composants de l'optimiseur CBO :
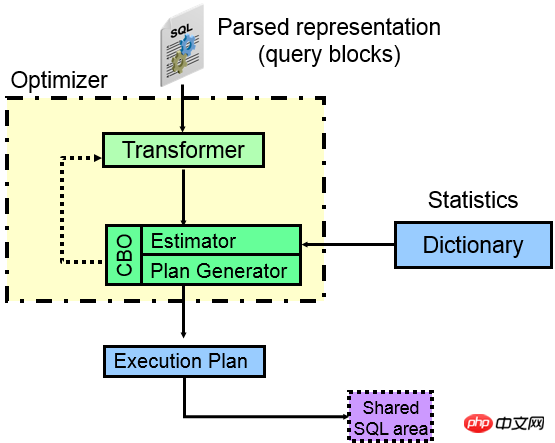
D'après l'image ci-dessus, vous pouvez voir que lorsqu'une instruction SQL entre dans ORACLE, les différentes parties seront en fait séparées après l'analyse, et chaque partie séparée devient un bloc de requête (blocs de requête) indépendamment. Par exemple, une sous-requête. deviendra un bloc de requête, et une requête externe sera un bloc de requête, alors ce que l'optimiseur ORACLE doit faire est quel type de chemin d'accès est le meilleur à l'intérieur de chaque bloc de requête (prenez index , table complète, partition ?), et la seconde est ce qui doit être fait entre chaque bloc de requête. Quelle méthode JOIN et quel ordre JOIN sont utilisés pour finalement calculer quel plan d'exécution est le meilleur.
Le cœur de l'optimiseur est le convertisseur de requêtes, l'estimateur de coûts et le générateur de plan d'exécution.
Transformateur (Query Transformer) :
Comme le montre la figure, le premier dispositif principal de l'optimiseur est le transformateur de requêtes. La fonction principale du transformateur de requêtes est d'étudier diverses requêtes. blocs La relation entre SQL et SQL est syntaxiquement et même sémantiquement équivalente. Le SQL réécrit est plus facilement traité par l'estimateur de coût du périphérique principal et le générateur de plan d'exécution, utilisant ainsi des informations statistiques pour générer le plan d'exécution optimal.
Le convertisseur de requêtes a deux méthodes dans l'optimiseur : la conversion de requêtes heuristiques (basée sur des règles) et la conversion de requêtes basée sur le coût. Les conversions de requêtes heuristiques sont généralement des instructions relativement simples, et celles basées sur les coûts sont généralement plus complexes, c'est-à-dire qu'ORACLE qui se conforme aux requêtes basées sur des règles effectuera la conversion de requêtes dans toutes les circonstances, et ORACLE qui ne répond pas aux exigences peut l'envisager. conversion de requêtes basée sur les coûts. La conversion de requêtes heuristiques a une longue histoire et pose moins de problèmes. Généralement, l'efficacité de la conversion de requêtes est supérieure à celle sans conversion de requêtes basée sur le coût, car elle est étroitement liée à l'optimiseur CBO, a été introduite dans 10G et est très. complexe en interne.Par conséquent, il existe de nombreux bugs.Dans le processus d'optimisation quotidien, divers SQL difficiles apparaissent souvent dans les échecs de conversion de requête, car une fois la conversion de requête échouée, Oracle ne peut pas convertir le SQL d'origine en un SQL mieux structuré (ce qui est plus facile à utiliser). être optimisé). (traitement du processeur), il y a évidemment beaucoup moins de chemins d'exécution parmi lesquels choisir. Par exemple, si la sous-requête ne peut pas être UNNEST, alors c'est souvent le début d'un désastre. En fait, ce qu'Oracle fait le plus dans la conversion de requêtes est de convertir diverses requêtes en méthodes JOIN, afin que diverses méthodes JOIN efficaces puissent être utilisées, telles que HASH JOIN.
Il existe plus de 30 méthodes de transformation de requêtes. Certaines heuristiques courantes et transformations de requêtes basées sur le coût sont répertoriées ci-dessous.
Transformation de requêtes heuristiques (une série de RÈGLES) :
De nombreuses transformations de requêtes heuristiques existent déjà dans le cas RBO. Les plus courants sont :
Fusion de vues simples (fusion de vues simples), SU (extension de sous-requête sans imbrication de sous-requêtes), OJPPD (ancien style de poussée de prédicat de jointure, ancienne méthode de poussée de prédicat de jointure), FPD (poussée de filtre) -down push de prédicat de filtre), OR Expansion (expansion OR), OBYE (Ordre par élimination), JE (élimination de connexion d'élimination de jointure ou élimination de table dans la connexion), Prédicat transitif (transfert de prédicat) et d'autres technologies.
Conversion de requêtes basée sur le COST (calculée par COST) :
Conversion de requêtes basée sur le COST pour les instructions complexes, les plus courantes sont :
CVM (fusion de vues complexes) Fusion de vues ), JPPD (Rejoindre le push-down du prédicat), DP (Placement distinct), GBP (Grouper par placement) et d'autres technologies.
Grâce à une série de technologies de conversion de requêtes, le SQL d'origine est converti en SQL plus facile à comprendre et à analyser pour l'optimiseur, de sorte que davantage de prédicats, de conditions de connexion, etc. puissent être utilisés pour atteindre l'objectif de obtenir le meilleur plan. Pour interroger le processus de conversion, vous pouvez obtenir des informations détaillées via 10053. La réussite de la conversion de requête dépend de la version, des restrictions de l'optimiseur, des paramètres implicites, des correctifs, etc.
Recherchez simplement la conversion de requêtes sur MOS, et un tas de bugs apparaîtront :
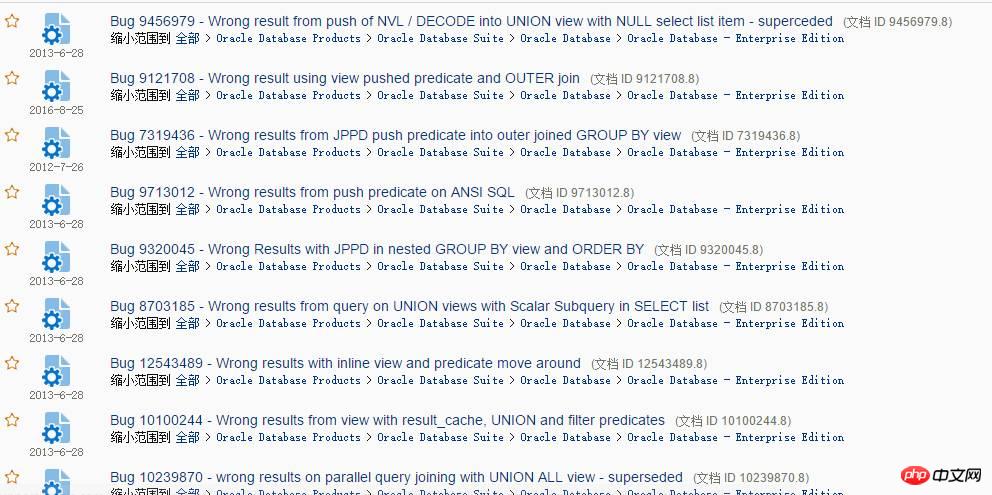
Il s'est avéré que c'était un résultat erroné. Rencontrer ce type de BUG n'est pas un problème de performances, mais un sérieux problème d'exactitude des données. Bien sûr, vous pouvez le trouver dans MOS. Il y a beaucoup de bugs comme celui-ci, mais dans les applications réelles, je pense que vous pourriez en rencontrer moins. Si un jour vous voyez que le résultat d'une requête SQL peut être erroné, alors vous devez hardiment le remettre en question. Pour un géant comme Oracle, D'une manière générale, lorsque vous rencontrez des problèmes, le questionnement est une façon de penser très correcte. Ce type de problème de résultat erroné peut être observé lors du processus de mise à niveau majeure de la version de la base de données. Il existe deux principaux types de problèmes :
- .
Le résultat initial était correct, mais maintenant le résultat est faux. --J'ai rencontré une nouvelle version BUG
Maintenant, le résultat est correct, mais le résultat original était faux. --La nouvelle version corrige l'ancienne version BUG
La première situation est normale, la deuxième situation peut également exister. J'ai vu un client se demander si le résultat après la mise à niveau était incorrect. , et après vérification, il s'est avéré que le plan d'exécution de l'ancienne version était erroné et que le plan d'exécution de la nouvelle version était correct, c'est-à-dire qu'il était erroné depuis de nombreuses années sans être découvert. Après la mise à niveau, il s'est transformé. cela semblait être exact, mais ils pensaient que c'était faux.
En cas de résultats incorrects, s'il ne s'agit pas d'une fonction non essentielle, elle peut vraiment être enfouie profondément pendant de nombreuses années.
Estimateur(Estimateur) :
Évidemment, l'estimateur utilisera des informations statistiques (table, index, colonne, partition, etc.) pour estimer l'opération du plan d'exécution correspondante sélectivité, calculant ainsi la cardinalité de l'opération correspondante, générant le COÛT de l'opération correspondante, et enfin calculant le COÛT de l'ensemble du plan. Pour un estimateur, ce qui est très important est l'exactitude de son modèle d'estimation et l'exactitude du stockage des informations statistiques. Plus le modèle estimé est scientifique, plus les informations statistiques peuvent refléter la distribution réelle des données et couvrir davantage. données spéciales, le COÛT généré sera alors plus précis.
Cependant, cela est impossible. Il existe de nombreux problèmes dans le modèle d'estimateur et les informations statistiques. Par exemple, lors du calcul de la sélectivité pour chaîne, ORACLE convertira en interne la chaîne en type RAW. , après avoir converti le type RAW en un nombre, puis ROUND 15 chiffres à partir de la gauche, les chaînes peuvent être très différentes Puisque le nombre dépasse 15 chiffres après conversion, les résultats peuvent être similaires après conversion interne. Cela aboutit finalement à une sélectivité calculée inexacte.
Plan Generator (Plan Generator) :
Plan Generator analyse divers chemins d'accès, méthodes JOIN et séquences JOIN pour produire différents plans d'exécution. Ainsi, s'il y a un problème avec cette pièce, la pièce correspondante peut avoir des algorithmes insuffisants ou des limitations. Par exemple, s'il existe de nombreuses tables JOIN, le choix des différentes séquences d'accès augmente selon une progression géométrique. Il existe des limites dans ORACLE, ce qui signifie qu'il est impossible de toutes les calculer.
Par exemple, l'algorithme HASH JOIN est généralement l'algorithme préféré pour le traitement du Big Data. Cependant, HASH JOIN a intrinsèquement une limitation : une fois qu'une collision HASH est rencontrée, l'efficacité sera inévitablement considérablement réduite.
L'optimiseur CBO présente de nombreuses limitations. Pour plus de détails, veuillez vous référer à MOS : Limitations de l'optimiseur basé sur les coûts Oracle (ID de document 212809.1).
2. Solutions aux pièges de l'optimiseur CBO
Cette section partage principalement des cas de problèmes quotidiens courants de l'optimiseur. Certains problèmes ne se limitent pas à l'optimiseur CBO, car le CBO est donc actuellement largement utilisé. , intègre toujours le problème du CBO.
1 problème de tueur de performances FILTER
L'opération FILTER est une opération courante dans le plan d'exécution. Il existe deux situations pour cette opération :
Une seule. nœud enfant, il s’agit alors d’une simple opération de filtrage.
S'il y a plusieurs nœuds enfants, alors il s'agit d'une opération similaire à NESTED LOOPS. La seule différence par rapport à NESTED LOOPS est que FILTER construira une table HASH en interne pour les correspondances répétées. ne sera pas effectué à nouveau Boucle pour rechercher, mais utiliser les résultats existants pour améliorer l'efficacité. Mais une fois qu'il y aura moins de correspondances répétées et plus de boucles, l'opération FILTER affectera sérieusement les performances et votre SQL risque de ne pas pouvoir être exécuté avant plusieurs jours.
Jetons un coup d'œil au fonctionnement FILTER dans diverses circonstances :
Nœud enfant unique :
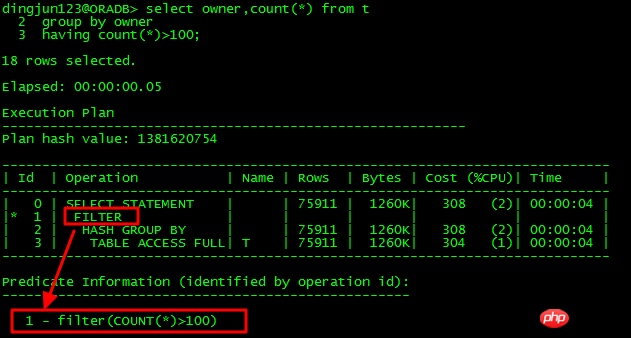
Évidemment l'ID L'opération FILTER de =1 n'a qu'un seul nœud enfant ID=2 Dans ce cas, l'opération FILTER est une simple opération de filtrage.
Nœuds enfants multiples :
FILTER Plusieurs nœuds enfants nuisent souvent aux performances. Ils se produisent principalement lorsque les sous-requêtes ne peuvent pas être converties en requêtes UNNEST. Les situations couramment rencontrées ne sont PAS des sous-requêtes IN, des sous-requêtes et des OU continus. utilisation, sous-requêtes complexes, etc.
(1) FILTRE dans la sous-requête NOT IN
Regardons d'abord la situation NOT IN :
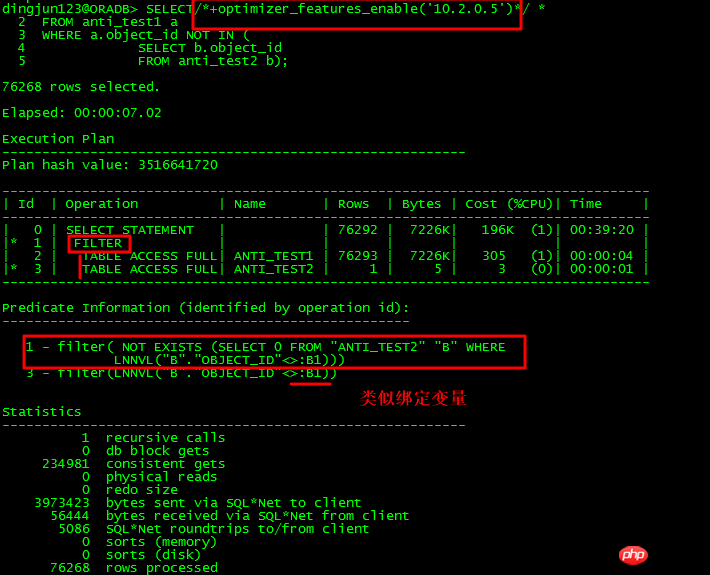
Pour la sous-requête NOT IN ci-dessus, si la sous-requête object_id a NULL, la requête entière n'aura aucun résultat avant 11g, si la table principale et la sous-table si l'object_id. n'a pas de contraintes NOT NULL en même temps, ou aucune restriction IS NOT NULL n'est ajoutée, ORACLE utilisera FILTER. 11g dispose d'une nouvelle optimisation ANTI NA (NULL AWARE) qui peut UNNEST les sous-requêtes pour améliorer l'efficacité.
Pour la sous-requête qui n'est pas NON NESTÉE, utilisez FILTER et ayez au moins 2 nœuds enfants. Une autre caractéristique du plan d'exécution est que la partie Prédicat contient : B1, quelque chose comme la liaison d'une variable . , le fonctionnement interne est similaire à l'opération NESTED LOOPS.
11g a NULL AWARE spécifiquement optimisé pour les problèmes NOT IN, comme indiqué ci-dessous :
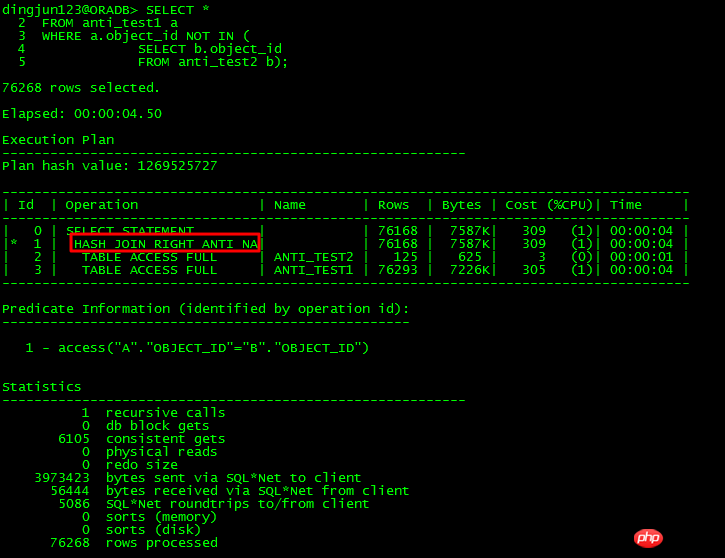
L'opération NULL AWARE est utilisée pour gérer les sous-requêtes NOT IN qui ne peuvent pas être UNNESTed Il peut être converti en formulaire JOIN, ce qui améliore considérablement l'efficacité. Que devez-vous faire si vous rencontrez NOT IN et ne pouvez pas UNNEST avant 11g ?
Définissez la condition de correspondance de la partie NOT IN Dans cet exemple, ANTI_TEST1.object_id et ANTI_TEST2.object_id sont définis sur des contraintes NOT NULL.
Si vous ne modifiez pas la contrainte NOT NULL, vous devez ajouter les conditions IS NOT NULL aux deux object_ids.
est remplacé par NON EXISTE.
est remplacé par le formulaire ANTI JOIN.
Les quatre méthodes ci-dessus peuvent atteindre l'objectif de faire en sorte que l'optimiseur utilise JOIN dans la plupart des cas.
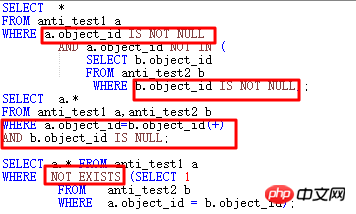
Les plans d'exécution ci-dessus sont les mêmes, comme indiqué ci-dessous :
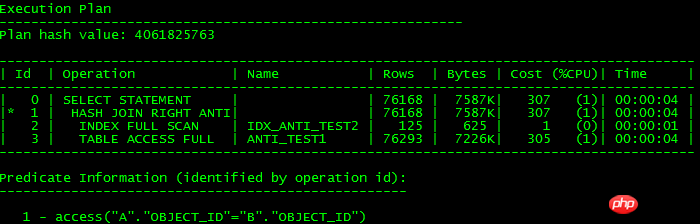
Pour parler franchement, la sous-requête unnest est conversion en formulaire JOIN.S'il peut être converti en JOIN, vous pouvez utiliser la fonctionnalité JOIN efficace pour améliorer l'efficacité opérationnelle. S'il ne peut pas être converti, utilisez FILTER, ce qui peut affecter l'efficacité, comme le montre le plan d'exécution de NULL de 11g. CONSCIENT, il y a encore une légère différence. Il n'y a pas d'analyse INDEX FULL SCAN, car il n'y a aucune condition pour qu'ORACLE sache que object_id peut exister NULL, il ne peut donc pas accéder à l'index.
OK, parlons maintenant d'un cas rencontré lors du processus de mise à niveau de la base de données. Le contexte est que le SQL suivant a des problèmes de performances après la mise à niveau de 11.2.0.2 vers 11.2.0.4 :
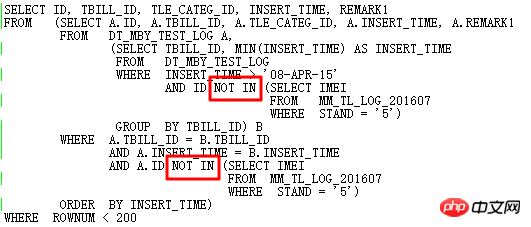
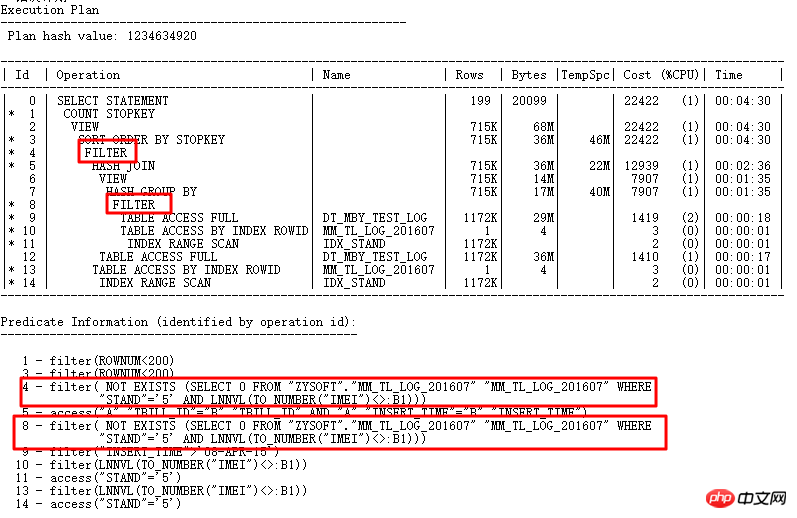
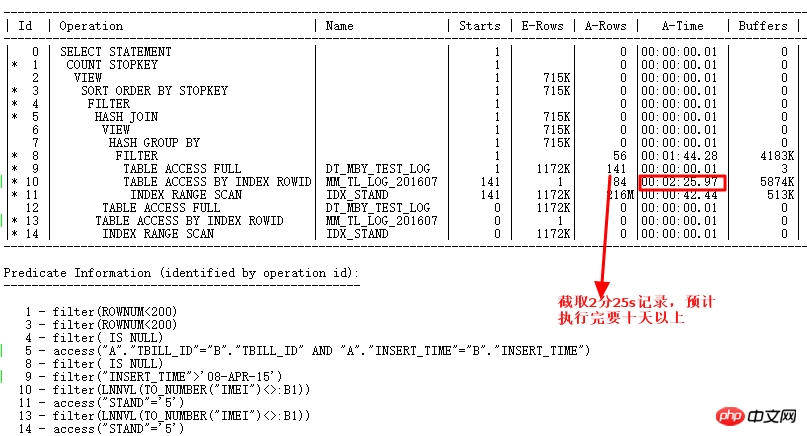
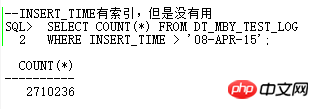
- Requête si les paramètres implicites liés à NULL AWARE ANTI JOIN sont valides
- Les informations statistiques collectées sont-elles valides ?
- Qu'il s'agisse d'un BUG de nouvelle version ou d'une modification de paramètre lors de la mise à jour

Retour au sujet, il faut maintenant savoir si le problème est causé par un BUG d'une nouvelle version ou par un paramètre modifié. Ensuite, il faut utiliser la méthode avancée de SQLT : XPLORE. XPLORE ouvrira et fermera en permanence divers paramètres dans ORACLE pour générer le plan d'exécution. Enfin, nous pouvons trouver le plan d'exécution correspondant via le rapport généré pour déterminer s'il s'agit d'un problème de BUG ou d'un problème de paramétrage.

C'est très simple à utiliser. Reportez-vous au fichier readme.txt pour éditer un fichier séparé pour le SQL qui doit être testé. Généralement, nous utilisons la méthode XPLAIN pour les tests. et appelez EXPLAIN PLAN FOR pour des tests, comme celui-ci Assurer l'efficacité des tests.
SQLT Découvrez la cause première du problème :

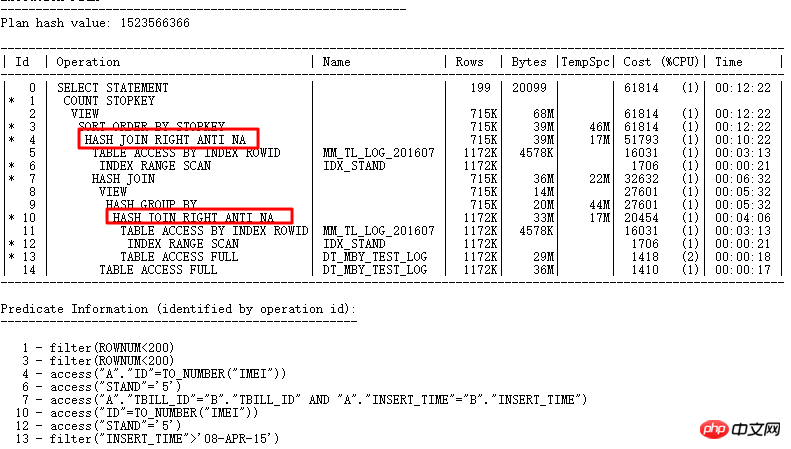
Découvrez enfin la cause première du problème via SQLT XPLORE La nouvelle version désactive le paramètre _optimier_squ_bottomup (lié aux sous-requêtes). On peut également voir à partir de ce point que de nombreuses conversions de requêtes peuvent réussir, non seulement un paramètre fonctionne, mais plusieurs paramètres peuvent fonctionner ensemble. Par conséquent, désactivez les paramètres par défaut et ne modifiez pas facilement leurs valeurs par défaut, sauf en cas de raison sérieuse. À ce stade, ce problème a été rapidement résolu avec l'aide de SQLT. Si SQLT n'était pas utilisé, le processus de résolution du problème serait évidemment plus tortueux. Dans des circonstances normales, on estime que les développeurs devraient d'abord modifier SQL.
Réfléchissez-y, le SQL d'origine peut-il être plus optimisé ?
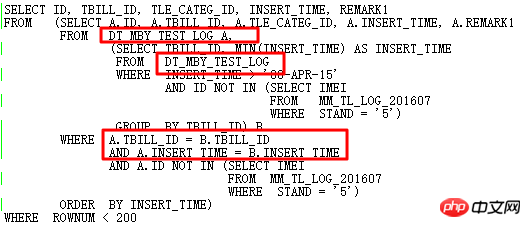
Évidemment, si vous souhaitez optimiser davantage, vous devez réécrire complètement le SQL. Par observation, les deux sous-requêtes ont des similitudes : après analyse de la sémantique : la table de recherche DT_MBY_TEST_LOG. est dans Dans la plage INSERT_TIME spécifiée, prenez le plus petit INSERT_TIME pour chaque TBILL_ID, et l'ID n'est pas dans la sous-requête, puis les résultats sont triés selon INSERT_TIME et enfin TOP 199 est pris.
Le SQL d'origine utilise l'auto-jointure et deux sous-requêtes, ce qui est redondant et compliqué. Naturellement, je pense à le réécrire avec des fonctions analytiques pour éviter l'auto-adhésion et ainsi améliorer l'efficacité. Le SQL réécrit est le suivant :
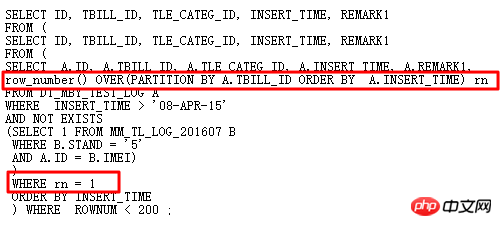
Plan d'exécution :
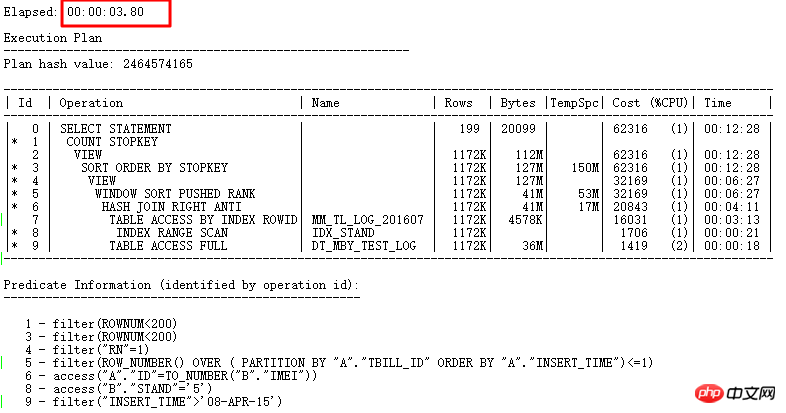
À ce stade, ce SQL nécessite FILTER du original Il a fallu 10 jours. Il a fallu plus de 7 secondes pour trouver la cause première du problème et utiliser NULL AWARE ANTI JOIN. Enfin, il a fallu 3,8 secondes pour le réécrire complètement.
(2) FILTRE dans la sous-requête OR
Examinons l'utilisation courante de OR et de sous-requête Dans le processus d'optimisation actuel, il n'est généralement pas possible d'utiliser OR et sous-requête ensemble. peut entraîner de sérieux problèmes de performances. Il existe deux possibilités d'utilisation de OR avec une sous-requête :
condition ou sous-requête
à l'intérieur de la sous-requête Contient ou, comme par exemple. dans (sélectionnez… depuis l'onglet où condition1 ou condition 2)
Permettez-moi de partager la méthode de traitement de l'optimisation des sous-requêtes OR à travers un cas spécifique Dans une certaine bibliothèque 11g R2, j'ai rencontré le SQL suivant. , qui n'a pas été exécuté depuis plusieurs heures :

Voyons d'abord le plan d'exécution :
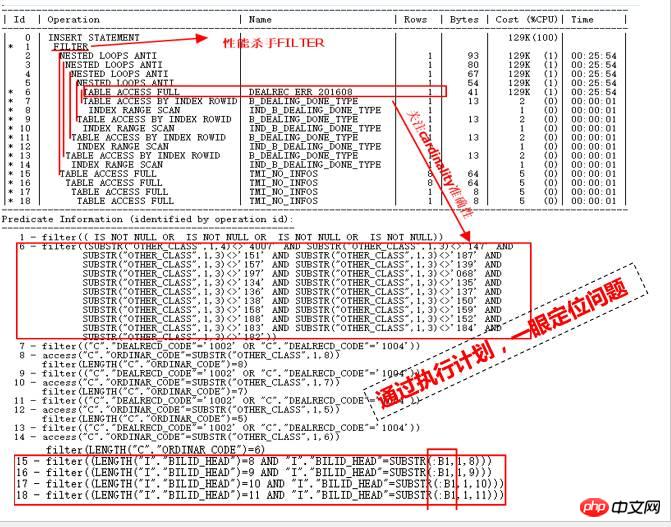
Comment pouvons-nous localiser la cause du ralentissement des performances en un coup d'œil en voyant ce plan d'exécution ? Le positionnement est principalement analysé à travers les points suivants :
Lignes dans le plan d'exécution, c'est-à-dire que la cardinalité renvoyée par chaque étape est très petite, seulement quelques lignes, et le tableau d'analyse n'est pas trop grand, alors comment pourrait-il ne pas être terminé même après plusieurs heures d'exécution ? Une raison importante peut être que des informations statistiques inexactes conduisent à une estimation incorrecte par l'optimiseur CBO. De mauvaises informations statistiques conduisent à de mauvais plans d'exécution.
Regardez les parties ID=15 à 18. Ce sont les deuxièmes nœuds enfants de l'opération ID=1 FILTER. Le premier nœud enfant est la partie ID=2. ID=2 Si l'erreur de cardinalité estimée est en réalité importante, le nombre d'analyses complètes sur les quatre tables avec ID=15 à 18 sera énorme, ce qui conduira au désastre.
Évidemment, un tas de BOUCLES NESTED dans la partie ID=2 sont également très suspectes. L'entrée de l'opération ID=2 se trouve dans la partie ID=6. est analysé pour DEALREC_ERR_201608, et on estime que 1 est renvoyé OK, évidemment, c'est la cause première de l'opération NESTED LOOPS, son exactitude doit donc être vérifiée.
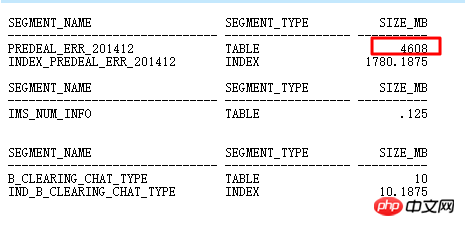
La table principale DEALREC_ERR_201608 renverra 20 millions de lignes dans la condition de requête ID=6. On estime qu'il n'y a qu'une seule ligne dans le plan. Par conséquent, le nombre NESTED LOOPS sera en fait exécuté des dizaines de millions de fois, ce qui entraîne. en faible efficacité. HASH JOIN doit être utilisé pour mettre à jour les statistiques.
De plus, ID=1 est FILTER, et ses nœuds enfants sont ID=2 et ID=15, 16, 17 et 18. Le même ID 15-18 a également été piloté des dizaines de millions de fois. .
Après avoir découvert la source du problème, résolvez-le étape par étape. Tout d'abord, nous devons résoudre l'exactitude de la cardinalité obtenue par la condition de requête substr(other_class, 1, 3) NOT IN ('147', '151', …) pour la table DEALREC_ERR_201608 dans la partie ID=6, c'est-à-dire , pour collecter des informations statistiques.
Cependant, il a été constaté que l'utilisation de size auto et size repeat n'avait aucun effet sur la collecte d'histogrammes pour other_class. L'estimation de retour de la condition de requête pour other_class dans le plan d'exécution était toujours de 1 (20 millions de lignes réelles).

Le plan d'exécution après exécution est à nouveau le suivant :
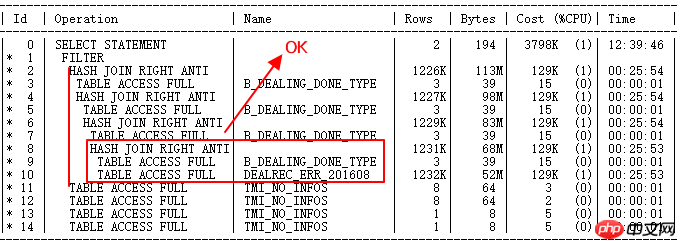
DEALREC_ERR_201608 et B_DEALING_DONE_TYPE à l'origine est allé NL Le HASH JOIN fonctionne désormais correctement. La table de construction est un petit ensemble de résultats, la table de sonde est un grand ensemble de résultats de la table ERR, correct.
Mais ID=2 et ID=11 à 14, c'est-à-dire la sous-requête OR avec TMI_NO_INFOS, ou FILTER, génère des dizaines de millions de requêtes de nœuds enfants, ce qui est la prochaine optimisation doit résoudre la question.
Performance de 12 heures à 2 heures.
Ce qui doit être résolu maintenant, c'est le problème FILTER. Il existe des conditions OR pour les sous-requêtes Si des conditions simples peuvent être interrogées et converties, elles seront généralement converties en une union. after all view Ensuite, effectuez semi join et anti join (convertissez en union all view, si les types de prédicats sont différents, SQL peut signaler une erreur). Pour cette complexité, l'optimiseur ne peut pas interroger la transformation, la réécriture est donc la seule méthode réalisable. Après analyse du SQL, il s'avère que la requête est la même table, et les conditions sont similaires, mais la longueur est différente, donc c'est facile à gérer !

Comment changer le plan d'exécution de la sous-requête avec OR de FILTER à JOIN. Deux méthodes :
1) Passer à UNION ALL/UNION
2) La réécriture sémantique a déjà été utilisée et convertie en interne en opérations de type UNION. Réduisez l'accès à la table, vous ne pouvez réécrire complètement la condition OR pour éviter la conversion en une opération UNION.
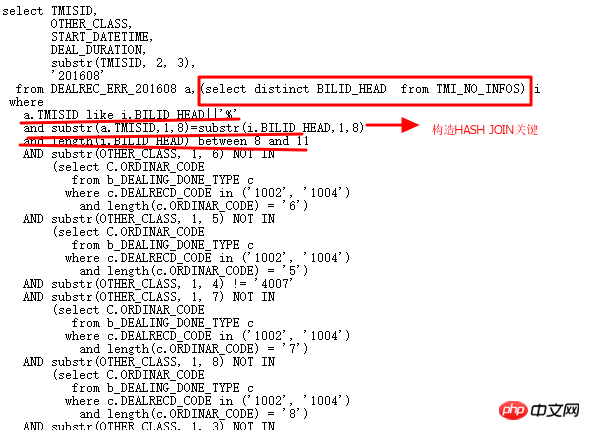
Analysons la condition OR d'origine :
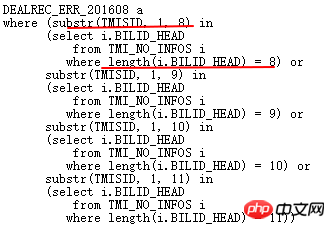
La signification ci-dessus est que les 8, 9, 10 et 11 premiers chiffres du TMISID de l'ERR table correspond à TMI_NO_INFOS.BILLID_HEAD , la longueur BILLID_HEAD correspondante correspondante est exactement 8,9,10,11. Évidemment, la sémantique peut être réécrite comme ceci :
La table ERR est associée à la table TMI_NO_INFOS. Les 8 premiers chiffres de ERR.TMISID correspondent exactement aux 8 premiers chiffres de ITMI_NO_INFOS.BILLID_HEAD avec une longueur comprise entre 8-. 11. Dans ce principe, TMISID ressemble à 'BILLID_HEAD %'.
Commencez maintenant à modifier complètement plusieurs sous-requêtes OR pour rendre SQL plus rationalisé et plus efficace. Réécrit comme suit :
Le plan d'exécution est le suivant :
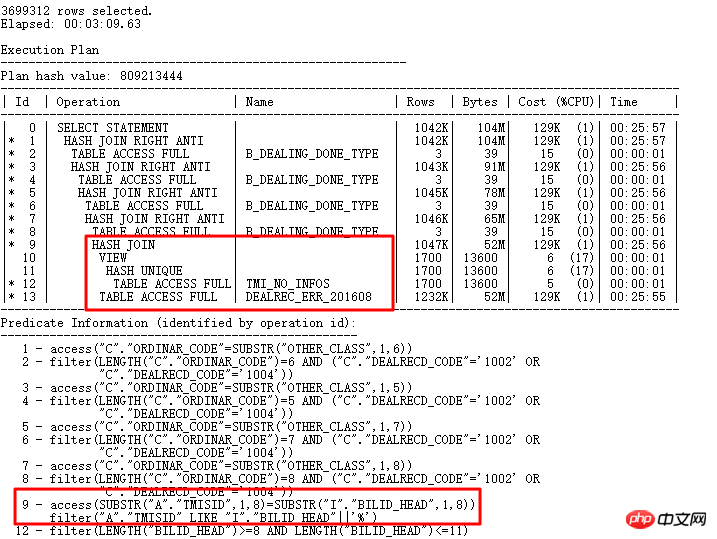
1) Le plan d'exécution actuel est finalement devenu plus court et plus facile Après la lecture, le HASH JOIN a été réécrit par la logique. Le SQL final qui renvoyait plus de 3 millions de lignes de données prenait à l'origine 12 heures à s'exécuter, mais il est maintenant exécuté en 3 minutes.
2) Réflexion : écrire du SQL avec une bonne structure et une sémantique claire aidera l'optimiseur à choisir un plan d'exécution plus raisonnable. Par conséquent, bien écrire du SQL est également un travail technique.
Grâce à ce cas, j'espère qu'il pourra vous inspirer sur la façon d'écrire du SQL pour agir comme un convertisseur de requêtes. Le SQL écrit peut réduire l'accès aux tables, aux index, aux partitions, etc., et peut créer des problèmes. il est plus facile pour ORACLE d'utiliser des opérations algorithmiques efficaces pour améliorer l'efficacité de l'exécution de SQL.
En fait, la sous-requête OR ne signifie pas nécessairement qu'elle ne peut pas du tout être désimbriquée. C'est simplement qu'elle ne peut pas l'être dans la plupart des cas. Veuillez consulter l'exemple suivant :
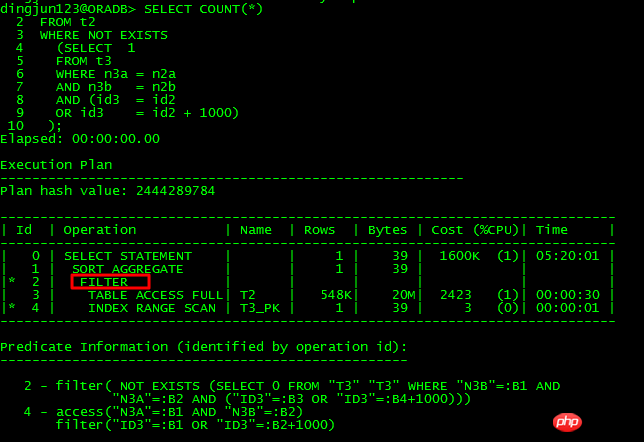
Requête qui ne peut pas l'être. être désimbriqué :
Peut désimbriquer la requête :
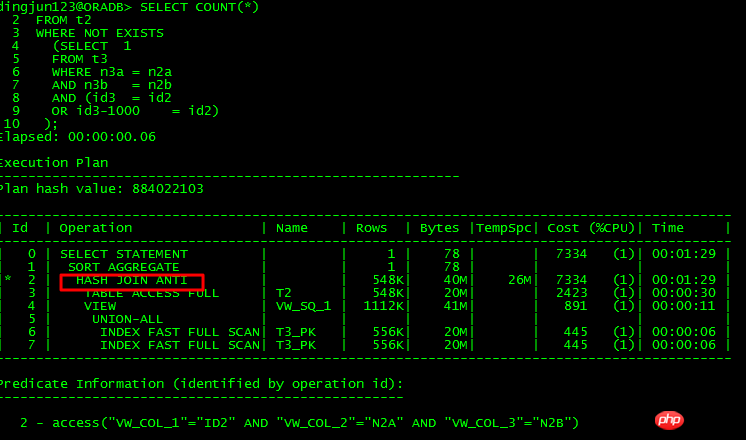
La différence entre ces deux SQL est de convertir la condition ou l'id3 = id2-1000 into ou id3 -1000 = id2, le premier ne peut pas être désimbriqué, et le second peut être désimbriqué. En analysant 10053, nous pouvons connaître :
L'apparition d'un désimbrication :
SU : désimbrication des blocs de requête dans le bloc de requête SEL$1 (#1) qui sont valides pour dissocier l'imbrication.
Sous-requête désimbriquée sur le bloc de requête SEL$1 (#1)SU : exécution d'une dimbrication qui ne nécessite pas de calcul de coût.
SU : prise en compte du désimbrication de la sous-requête sur le bloc de requête SEL$1 (#1).
SU : vérification de la validité de la sous-requête dissociée SEL$2 (#2)
SU : SU contourné : prédicats corrélés non valides.
SU : les contrôles de validité ont échoué.
Peut apparaître sans imbrication :

Et réécrivez le SQL comme :

Enfin, CBO interroge d'abord les conditions T3, crée une vue UNION ALL, puis l'associe à T2. De ce point de vue, les exigences de désimbrication pour les sous-requêtes OR sont relativement strictes. D'après l'analyse de cette instruction, ORACLE peut effectuer des opérations de désimbrication sans nécessiter d'opérations sur les colonnes de la table principale. L'optimiseur lui-même ne décale pas la condition +1000 vers la gauche. . Parce que Strict, donc dans la plupart des cas, la sous-requête OR ne peut pas être désimbriquée, ce qui entraîne divers problèmes de performances.
(3) Problèmes de type FILTER
Les problèmes de type FILTER se reflètent principalement dans les mises à jour liées à UPDATE et les sous-requêtes scalaires. Bien que le mot-clé FILTER n'apparaisse pas explicitement dans de telles instructions SQL, le fichier interne. L’opération est exactement la même que l’opération FILTER.
Premier aperçu de la mise à jour de l'association UPDATE :

14999 lignes doivent être mises à jour ici. Le plan d'exécution est le suivant :
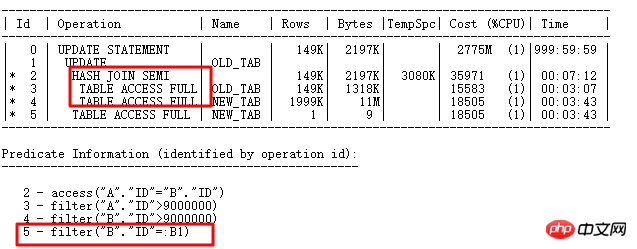
La partie ID=2 est la partie de sélection où existe. Interrogez d'abord les conditions qui doivent être mises à jour, puis exécutez la mise à jour de la sous-requête associée UPDATE. Vous pouvez voir que la variable de liaison apparaît dans le fichier. Partie ID=5 : B1. Évidemment, l'opération UPDATE est similaire à Dans le FILTER d'origine, pour chaque ligne sélectionnée et la requête associée à la table de sous-requête NEW_TAB, si la colonne ID a moins de valeurs répétées, la sous-requête sera exécutée beaucoup, ce qui affectera l'efficacité. C'est-à-dire que l'opération avec ID = 5 devra être exécutée de manière secondaire.
Bien sûr, l'ID de champ ici est tout à fait unique. Vous pouvez créer un INDEX UNIQUE ou un INDEX normal, afin que l'index puisse être utilisé à l'étape 5. Voici un exemple de cette méthode d'optimisation UPDATE. Sans construire d'index, vous pouvez également gérer de telles méthodes UPDATE : MERGR et UPDATE INLINE VIEW.
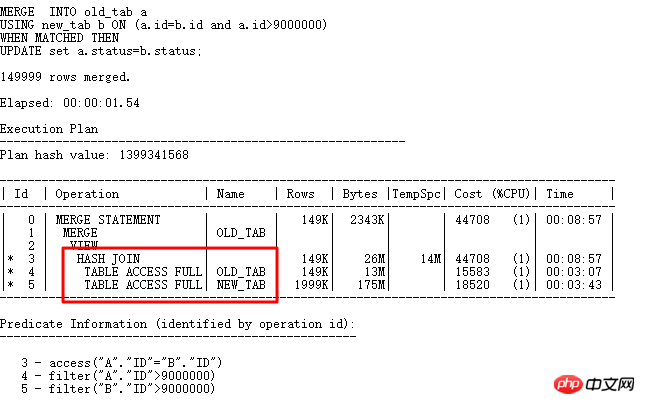
Utilisez HASH JOIN directement dans MERGE pour éviter plusieurs opérations d'accès, augmentant ainsi considérablement l'efficacité. Voyons comment écrire UPDATE LINE VIEW :
MISE À JOUR
(SELECT a.status astatus,
b.status bstatus
FROM old_tab a,
new_tab b
WHERE a .id= b.id
AND a.id >9000000
)
SET astatus=bstatus;
nécessite que b.id soit un clé préservée (index unique, contrainte unique, clé primaire), 11g bypass_ujvc signalera une erreur, similaire à l'opération MERGE.
Jetons un coup d'œil aux sous-requêtes scalaires. Les sous-requêtes scalaires sont souvent à l'origine de graves problèmes de performances :
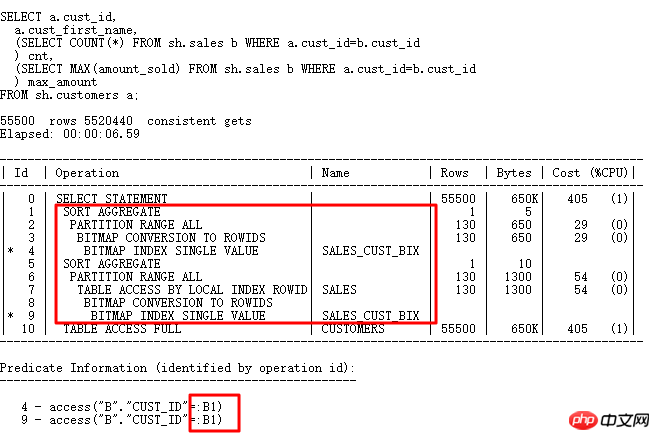
Le plan des sous-requêtes scalaires et l'exécution des sous-requêtes ordinaires. plans L'ordre est différent.Bien que la sous-requête scalaire soit en haut, elle est pilotée par les résultats de la table CUSTOMERS ci-dessous.Chaque ligne pilote une requête de sous-requête scalaire (à l'exception de CACHE), qui est également similaire à l'opération FILTER.
Si vous souhaitez optimiser la sous-requête scalaire, vous devez généralement réécrire le SQL et changer la sous-requête scalaire en un formulaire de jointure externe (elle peut également être réécrite en un JOIN normal si les contraintes et les affaires sont satisfaites) :

Après la réécriture, l'efficacité est grandement améliorée et l'algorithme HASH JOIN est utilisé. Jetons un coup d'œil à CACHE dans la sous-requête scalaire (les mises à jour liées à FILTER et UPDATE sont similaires). Si la colonne associée a beaucoup de valeurs répétées, la sous-requête sera exécutée moins souvent et l'efficacité sera meilleure à ce moment-là :
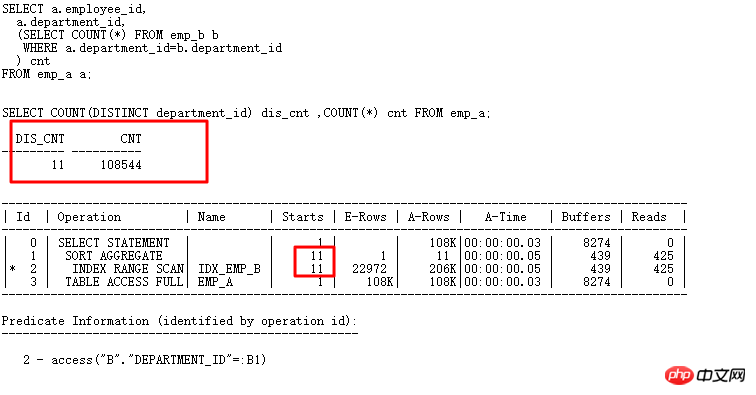
La sous-requête scalaire est la même que FILTER et a CACHE. Par exemple, emp_a ci-dessus a 108 000 lignes, mais le Department_id répété n'est que 11. De cette façon, la requête analyse uniquement. 11 fois, et le nombre d'analyses de la table de sous-requête est faible, l'efficacité sera améliorée.
Concernant le problème du tueur de performances FILTER, je partage principalement ces 3 points. Bien sûr, il y a bien d'autres points à noter, qui nous obligent à faire plus d'attention et d'accumulation au quotidien, afin de nous familiariser. avec comment gérer certains problèmes de l'optimiseur.
2 Problème de cardinalité de la fonction TABLE 8168
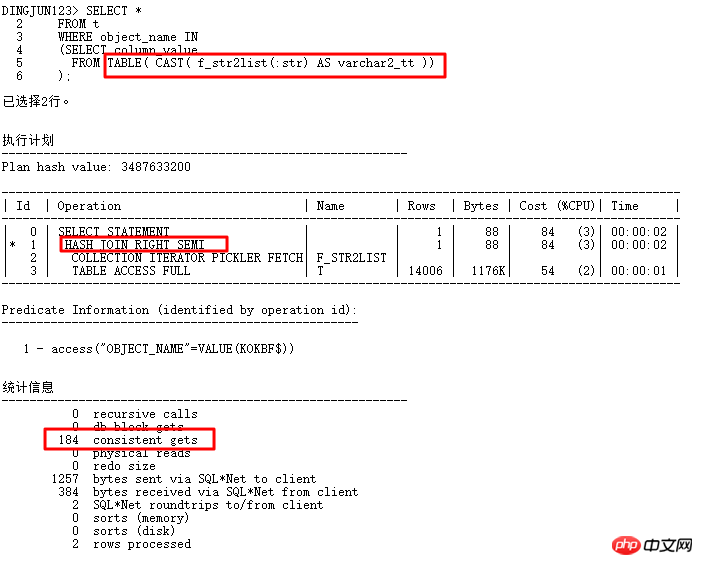
Ce problème vient du problème de liaison dans la liste, utilisant la fonction TABLE pour construire les valeurs entrantes séparées par des virgules En tant que conditions de sous-requête, le front-end transmet généralement moins de valeurs, mais en fait, l'opération HASH JOIN est effectuée et l'index de la table T ne peut pas être utilisé. Une fois la fréquence d'exécution élevée, cela aura inévitablement un impact plus important. sur le système. Pourquoi ORACLE ne sait-il pas que la fonction TABLE transmet très peu de valeurs ?
Analyse plus approfondie :
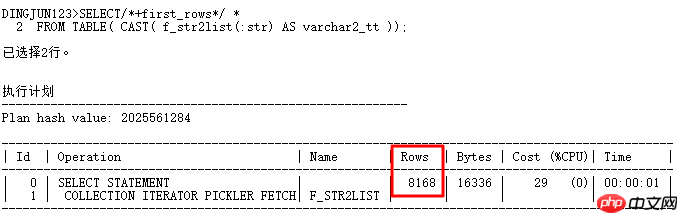
D'après les résultats ci-dessus, nous pouvons voir que le nombre de lignes par défaut de la fonction TABLE est de 8168 lignes (la pseudo-table créée par la fonction TABLE n'a aucune information statistique. Cette valeur n'est pas petite, et est généralement beaucoup plus). que le nombre de lignes dans les applications réelles, ce qui oblige souvent le plan d'exécution à passer par une jointure par hachage au lieu d'une boucle imbriquée. Comment changer cette situation ? Bien sûr, vous pouvez modifier le plan d'exécution via des invites d'indice. Pour où dans la liste, les indices couramment utilisés sont :
first_rows, index, cardinality, use_nl, etc.
Voici une introduction spéciale à la cardinalité(table|alias,n). Cette astuce est très utile. Elle peut faire penser à l'optimiseur CBO que le nombre de lignes dans la table est n, de sorte que le plan d'exécution. peut être modifié. Réécrivez maintenant la requête ci-dessus :
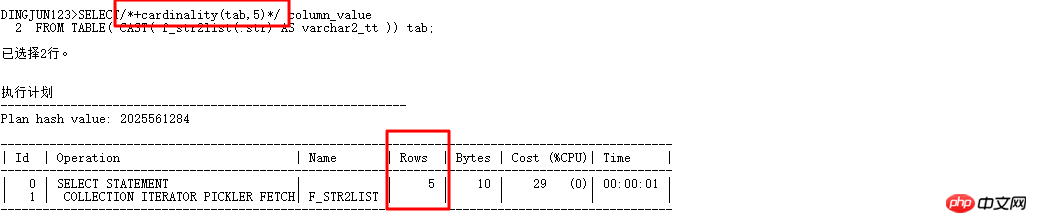
Add cardinality(tab,5) pour exécuter automatiquement l'optimiseur CBO. L'optimiseur traite la cardinalité de la table comme 5, et la précédente où. dans Lorsque la base de la requête de liste était 8168 par défaut, la jointure par hachage a été utilisée. Maintenant que la cardinalité est disponible, essayez-la rapidement :
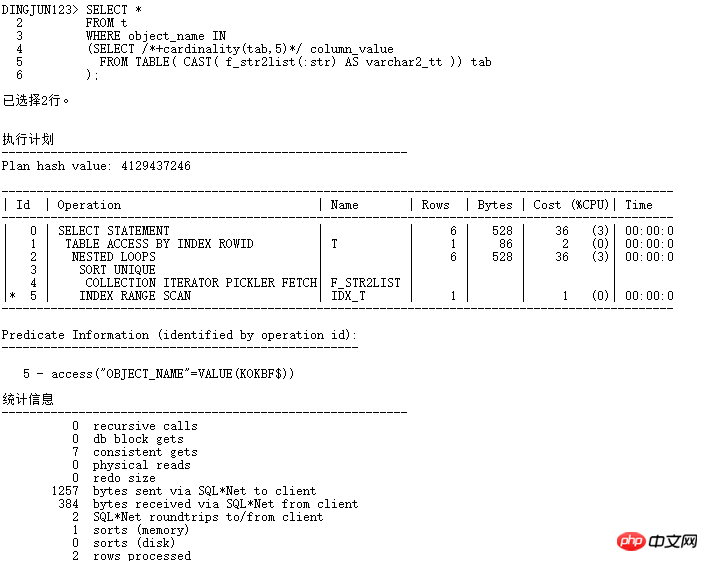
Utilisez maintenant l'opération NESTED LOOPS et l'enfant. les nœuds peuvent utiliser INDEX RANGE SCAN, la lecture logique passe de 184 à 7 et l'efficacité est améliorée des dizaines de fois. Bien entendu, dans les applications réelles, il est préférable de ne pas ajouter d'indices et vous pouvez utiliser la liaison SQL PROFILER.
3 Problème de calcul de sélectivité inexact
Le calcul interne de la sélectivité d'Oracle est calculé au format numérique. Par conséquent, lorsqu'elle rencontre un type de chaîne, la chaîne sera convertie en type RAW, puis convertira le. Tapez RAW sur un nombre et ROUND sur 15 chiffres à partir de la gauche. Si le nombre converti est très grand, les chaînes d'origine peuvent être très différentes, mais les nombres convertis en interne sont relativement proches, ce qui peut entraîner des calculs sélectifs inexacts. Par exemple :

Le plan d'exécution est le suivant :
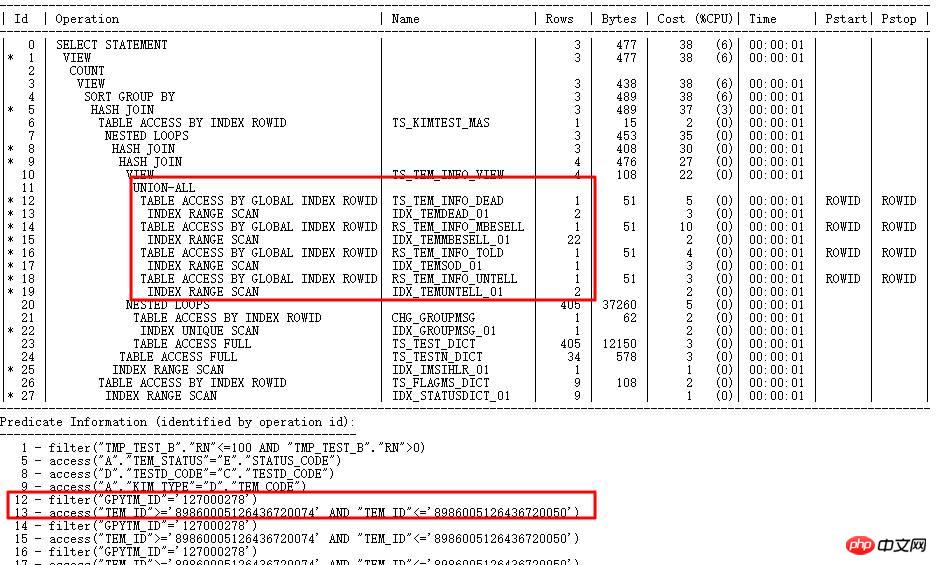
Le plan d'exécution SQL utilise l'index TEM_ID et a besoin fonctionner pendant plus d'une heure. La cardinalité des étapes correspondantes dans le plan est très petite (des dizaines de niveaux), mais la cardinalité réelle est très grande (des millions de niveaux) et les informations statistiques de jugement sont erronées.
Pourquoi se tromper d’index ?
Étant donné que TEM_ID est un type de chaîne CHAR d'une longueur de 20, la sélectivité de calcul interne de CBO convertira d'abord la chaîne en RAW, puis convertira RAW en un nombre, ARRONDISSANT 15 chiffres à partir de la gauche. Par conséquent, il est possible que les valeurs de chaîne soient très différentes et que les valeurs soient similaires après conversion en nombres (car plus de 15 chiffres sont complétés par 0), ce qui entraîne des erreurs de calcul sélectives. Prenons l'exemple de la colonne TEM_ID dans TS_TEM_INFO_DEAD :

Le nombre réel de lignes interrogées selon les conditions est de 29737305. L’index est donc erroné.
Solution :
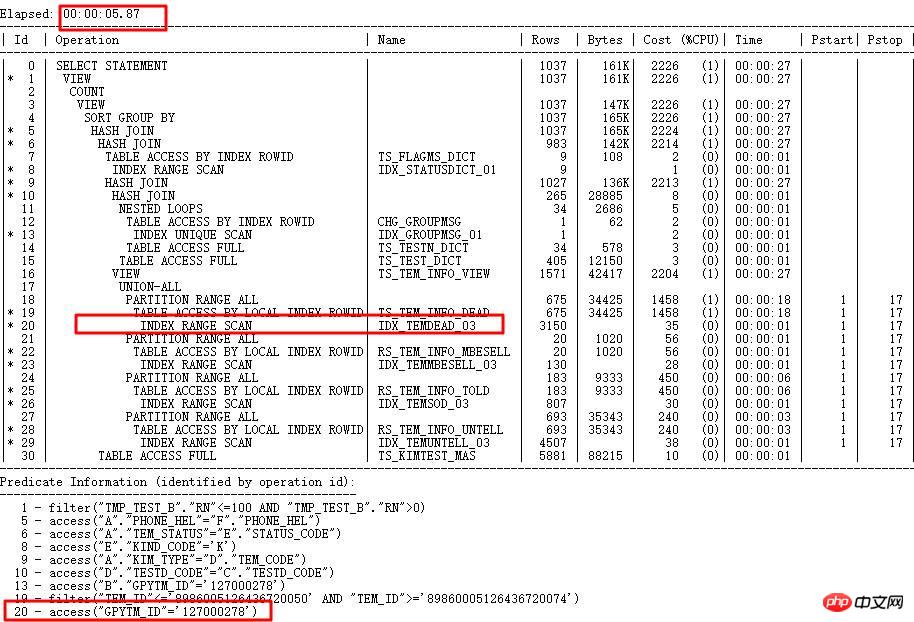
Collectez l'histogramme de la colonne TEM_ID En raison de certaines limitations de l'algorithme interne, les chaînes avec des valeurs différentes peuvent avoir la même valeur calculée interne. pour la chaîne Les valeurs sont différentes, mais elles sont les mêmes après avoir été converties en nombres. ORACLE stockera la valeur réelle dans ENDPOINT_ACTUAL_VALUE pour vérification et améliorera la précision du plan d'exécution. Après avoir correctement indexé GPYTM_ID, la durée d'exécution varie de plus d'une heure à moins de 5 secondes.
4 Les nouvelles fonctionnalités provoquent des erreurs d'exécution
Chaque version introduira de nombreuses nouvelles fonctionnalités. Une mauvaise utilisation des nouvelles fonctionnalités peut entraîner de graves problèmes tels que des problèmes courants. Les commentaires sur l'ACS et la cardinalité entraînent des changements fréquents dans les plans d'exécution, affectant l'efficacité, un trop grand nombre de sous-curseurs, etc. Par conséquent, les nouvelles fonctionnalités doivent être utilisées avec prudence, y compris l'anti-jointure 11g null-ware susmentionné, qui comporte également de nombreux bugs.
Le cas à analyser aujourd'hui est le SQL rencontré lors de la mise à niveau majeure de la version 10g vers 11g. Il fonctionnait normalement en 10g, mais s'exécutait incorrectement en 11g. Le SQL est le suivant :
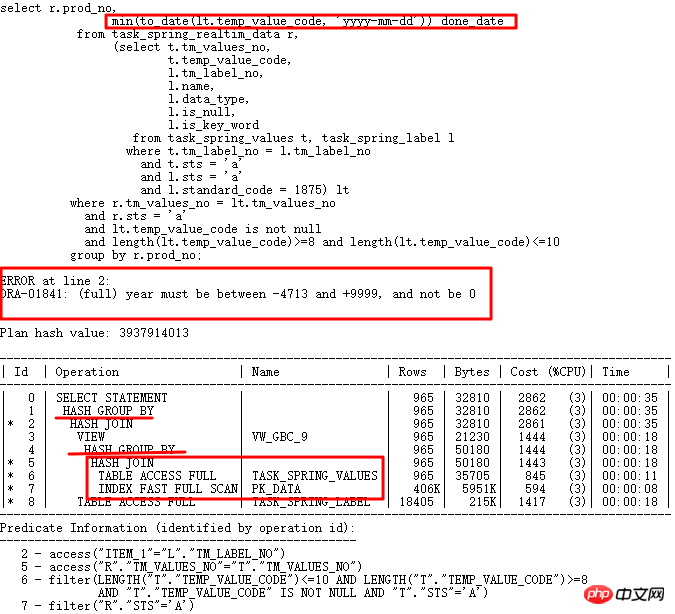
10g est normal. Après la mise à niveau vers 11g r2, l'erreur de conversion de date se produit. Plan d'exécution correct : la requête associée à LT est exécutée en premier, puis associée à la table. Le mauvais plan d'exécution est que TASK_SPRING_VALUES est d'abord associé à la table puis regroupé, en tant que VIEW, puis associé à TASK_SPRING_LABEL, puis regroupé à nouveau. Il y a 2 opérations GROUP BY ici, ce qui est différent du plan d'exécution 10g avec seulement 1. Opération GROUP BY, qui conduit finalement à une erreur.
Évidemment, pourquoi il y a deux opérations GROUP BY doit être étudiée. 10053 est le premier choix :
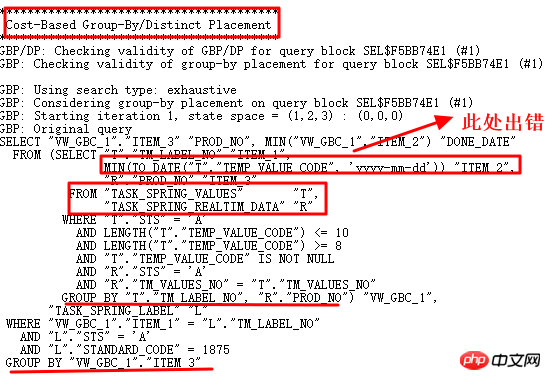
Analyse selon l'opération 10053, s'il faut trouver. le format non-date Valeur :
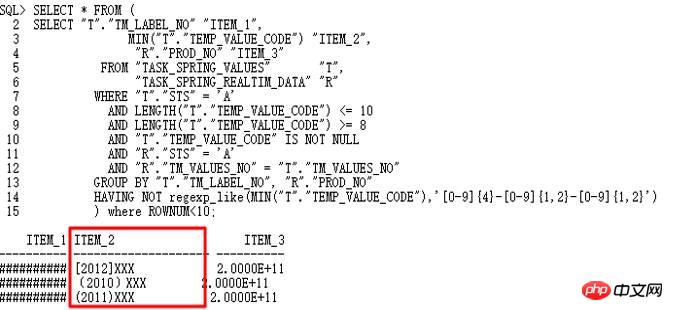
Une chaîne au format non-aaaa-mm-jj a bien été trouvée, par conséquent, l'opération to_date a échoué. Comme le montre 10053, l'opération Regrouper par/Placement distinct est utilisée ici. Par conséquent, il est nécessaire de trouver les paramètres de contrôle correspondants et de désactiver cette conversion de requête.
Corriger après avoir désactivé les paramètres implicites GBP : _optimizer_group_by_placement. Le plan d'exécution correct est le suivant :
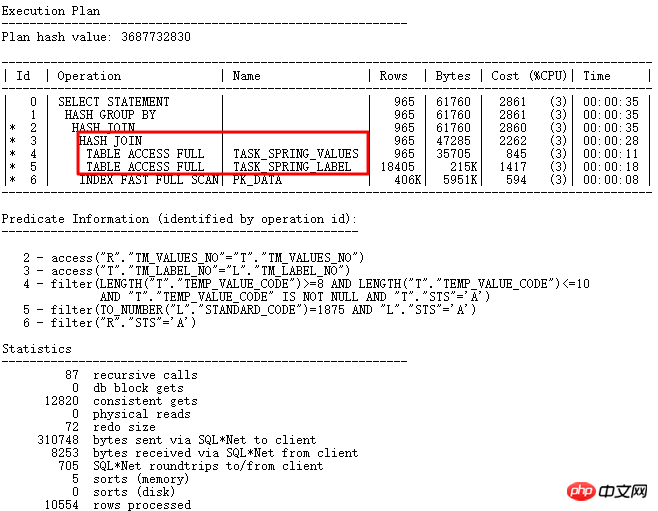
Réflexion : l'essence de ce problème réside dans la conception déraisonnable de l'utilisation des champs, dans laquelle temp_value_code est utilisé comme varchar2 pour stocker les caractères ordinaires , les caractères numériques et le format de date aaaa-mm -jj, il y a to_number, to_date et d'autres conversions dans le programme, qui dépendent fortement de l'ordre des connexions de table et des conditions dans le plan d'exécution. Par conséquent, une bonne conception est très importante, notamment pour garantir la cohérence des types de champs associés et le rôle unique des champs, et pour répondre aux exigences du paradigme.
5 CBO ne peut rien faire avec de mauvaises méthodes d'écriture
Un SQL bien structuré peut être plus facile à comprendre par CBO, permettant de meilleures opérations de conversion de requêtes, jetant ainsi les bases de la génération ultérieure de le meilleur plan d'exécution, puis l'application pratique Au cours du processus, CBO n'a rien pu faire car il ne prêtait pas attention à l'écriture SQL. Ce qui suit est une étude de cas d’écriture de pagination.
Écriture de pagination inefficace :

Méthode d'écriture originale La couche la plus interne est interrogée en fonction de la date d'utilisation et d'autres conditions, puis triée, le numéro de ligne est obtenu et un alias, et la couche la plus externe est utilisée rnlaw. Quel est le problème ?
Si vous écrivez la pagination directement <,<=, vous pouvez obtenir le numéro de ligne directement après le tri (deux niveaux d'imbrication). Si vous avez besoin d'obtenir la valeur d'intervalle, obtenez >,>= à). le niveau le plus extérieur (trois niveaux) imbriqués).
Cette instruction obtient <=, et l'utilisation de trois niveaux d'imbrication rend impossible l'utilisation de l'algorithme STOPKEY de requête de pagination car rownum empêchera la poussée de prédicat, ce qui n'entraînera aucune opération STOPKEY dans le plan d'exécution.
<=La pagination ne nécessite que 2 niveaux d'imbrication, et la colonne done_date a un index Selon la condition done_date>to_date('20150916','YYYYMMDD') et seules les 20 premières lignes sont obtenues. l'algorithme d'index et STOPKEY peut être utilisé efficacement, une fois la réécriture terminée, l'analyse descendante de l'index est utilisée, le temps d'exécution est de 1,72 s à 0,01 s et l'E/S logique est de 42648 à 59, comme suit :

Une écriture de pagination efficace doit être conforme aux spécifications et peut utiliser pleinement les index pour éliminer le tri.
6 Problème de BUG CBO
Le BUG CBO apparaît plus souvent dans la conversion des requêtes. Une fois qu'un BUG se produit, il peut être difficile à trouver. À ce stade, vous devez analyser rapidement 10053 ou utiliser SQLT XPLORE. Trouvez la source du problème. Par exemple :
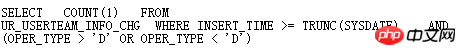
Le oper_type de cette table a un index, et la condition oper_type>'D' ou oper_type<'D' est préférable d'utiliser l'index, mais dans fait, Oracle est passé à l'analyse complète de la table, analyse rapide via SQLT >
Évidemment, _fix_control=8275054 est très suspect En interrogeant MOS :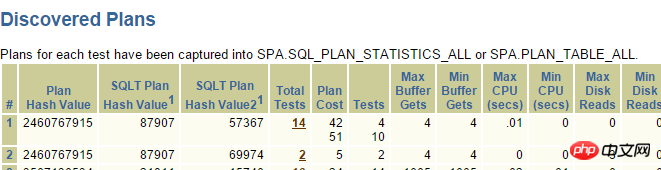
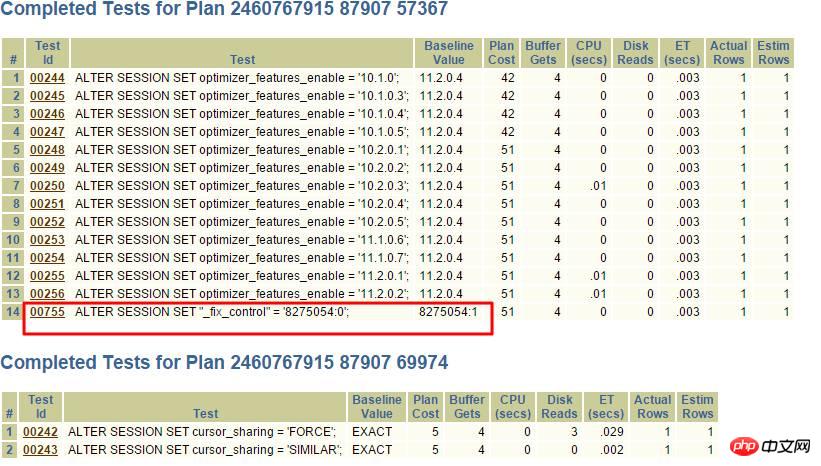 7 Problème de collision HASH
7 Problème de collision HASH
HASHJOIN est un algorithme efficace spécialement utilisé pour le traitement du Big Data, et ne peut être utilisé que pour des conditions de jointure équivalentes, pour la table de construction de table (table de hachage) et la construction de table de sonde une opération HASH pour trouver l’ensemble de résultats qui remplit les conditions.
Le format général est le suivant : 
Utilisons un petit exemple pour analyser la collision de hachage :
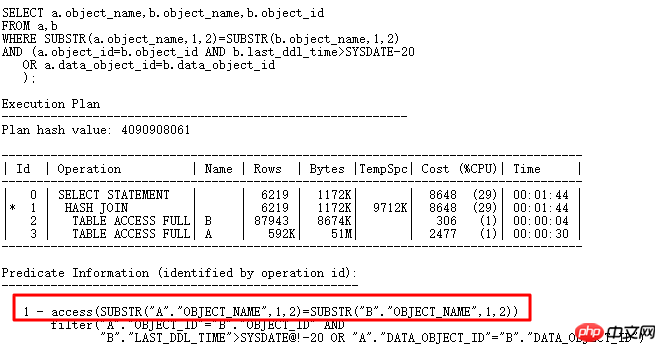
Parmi eux, la table a contient 61 enregistrements multiples et la table b contient 7 enregistrements multiples. Ce résultat SQL renvoie 80 000 enregistrements multiples. À partir du plan d'exécution, il n'y a aucun problème à effectuer du HASH. Opération JOIN. Cependant, l'exécution réelle de ce SQL n'a pas été terminée pendant plus de 10 minutes, l'efficacité était très faible et l'utilisation du processeur a soudainement augmenté, ce qui était beaucoup plus long que le temps d'accès aux deux tables.
Si vous connaissez HASHJOIN, vous devez actuellement vous demander si vous avez rencontré une collision de hachage. Si une grande quantité de données est stockée dans de nombreux compartiments, la recherche de données dans de tels compartiments de hachage est similaire aux boucles imbriquées. . , l’efficacité sera inévitablement considérablement réduite. Une analyse plus approfondie est la suivante :

Recherchez les valeurs supérieures aux données en double et supérieures à 3000. Effectivement, il y en a beaucoup. Bien sûr, il reste également de nombreuses données plus volumineuses. Détection HASH JOIN, vous pouvez utiliser EVENT 10104 :
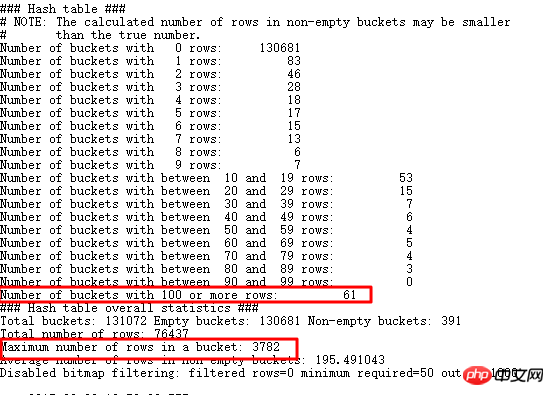
Vous pouvez voir qu'il y a 61 compartiments qui stockent plus de 100 lignes, et le plus grand seau stocke 3 782 articles, ce qui est cohérent et ce que nous avons découvert est cohérent. Revenons au SQL d'origine :
Pourquoi Oralce a-t-il choisi substr(b.object_name,1,2) pour construire la table HASH si OR peut être étendu et que le SQL d'origine est remplacé par une forme UNION ALL ? , puis la table HASH Elle peut être construite en utilisant substr(b.object_name,1,2), b.object_id et data_object_id Ensuite, l'unicité doit être très bonne, ce qui devrait résoudre le problème de collision de hachage comme suit :

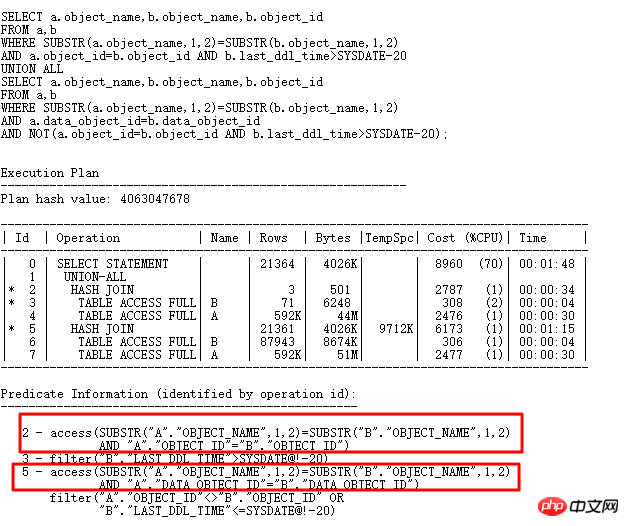 Celui avec le plus Seuls 6 éléments de données sont stockés dans le bucket, les performances doivent donc être bien meilleures qu'avant. Les collisions de hachage sont très dangereuses. Dans les applications pratiques, elles peuvent être plus compliquées. Si vous rencontrez des problèmes de collision de hachage, le meilleur moyen est de réécrire SQL d'un point de vue commercial et de voir si vous pouvez ajouter d'autres colonnes plus sélectives. REJOINDRE. .
Celui avec le plus Seuls 6 éléments de données sont stockés dans le bucket, les performances doivent donc être bien meilleures qu'avant. Les collisions de hachage sont très dangereuses. Dans les applications pratiques, elles peuvent être plus compliquées. Si vous rencontrez des problèmes de collision de hachage, le meilleur moyen est de réécrire SQL d'un point de vue commercial et de voir si vous pouvez ajouter d'autres colonnes plus sélectives. REJOINDRE. .
Avec le recul, puisque je sais qu'après l'avoir réécrit en UNION ALL, deux colonnes combinées seront utilisées pour construire une meilleure table HASH, alors pourquoi Oracle ne le fait-il pas ? C'est très simple. Je fais cela délibérément à titre d'exemple pour illustrer le problème de collision HASH. Pour ce type de SQL simple, si vous avez des colonnes plus sélectives et collectez des informations statistiques, Oracle peut OU étendre le SQL.
3. Renforcer l'audit SQL et résoudre les problèmes de performances dès l'enfance
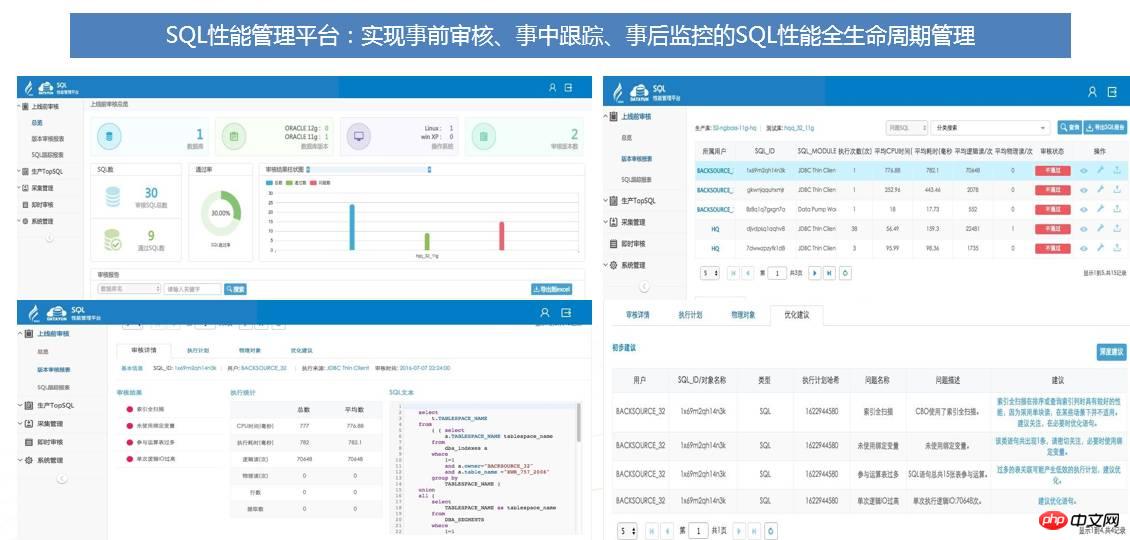
Il existe de nombreux SQL dans les systèmes d'application Si vous jouez toujours le rôle d'un pompier pour résoudre les problèmes en ligne, ce ne sera évidemment pas le cas. capable de répondre au développement rapide des systèmes informatiques actuels. Selon les besoins des systèmes basés sur des bases de données, le principal problème de performances réside dans les instructions SQL. Si les instructions SQL peuvent être examinées pendant la phase de développement et de test, le SQL à optimiser peut. être trouvé, et des invites intelligentes peuvent être données pour aider rapidement à l'optimisation, puis de nombreuses questions en ligne. De plus, les instructions SQL en ligne peuvent également être surveillées en permanence pour détecter rapidement les instructions présentant des problèmes de performances, atteignant ainsi l'objectif d'une gestion complète du
cycle de viede SQL. À cette fin, la société a combiné des années d'expérience en exploitation, maintenance et optimisation pour développer de manière indépendante des outils d'audit SQL, ce qui améliore considérablement l'efficacité du traitement d'optimisation d'audit SQL et de surveillance des performances.
L'outil d'audit SQL adopte une règle en quatre étapes : collecte SQL - analyse SQL - optimisation SQL - suivi en ligne. La méthode d'audit SQL en quatre étapes est différente de la méthode d'optimisation SQL traditionnelle. et l'optimisation avant la mise en ligne du système. Concentrez-vous sur la résolution des problèmes SQL avant la mise en ligne du système et éliminez les problèmes de performances à leurs balbutiements. Comme le montre la figure ci-dessous :
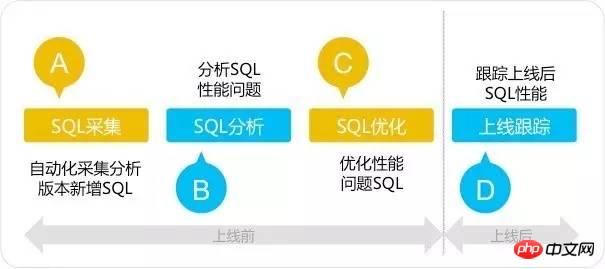
 Les problèmes suivants peuvent être résolus via la plateforme de gestion des performances SQL :
Les problèmes suivants peuvent être résolus via la plateforme de gestion des performances SQL :
- Avant : audit des performances SQL avant la mise en ligne, éliminez les problèmes de performances à leurs balbutiements ;
- Pendant : le traitement de surveillance des performances SQL, découvrez en temps opportun les changements dans les performances SQL après la mise en ligne ; , dans les performances SQL Lorsque des changements se produisent et ne causent pas de problèmes graves, résolvez-les rapidement
- Ensuite : surveillance TOPSQL et gestion des alarmes en temps opportun ;
- La plate-forme de gestion des performances SQL réalise une gestion et un contrôle du cycle de vie complet à 360 degrés des performances SQL, et grâce à diverses invites et traitements intelligents, la plupart des problèmes de performances causés à l'origine par SQL sont résolus . Résolvez les problèmes avant qu’ils ne surviennent et améliorez la stabilité du système.
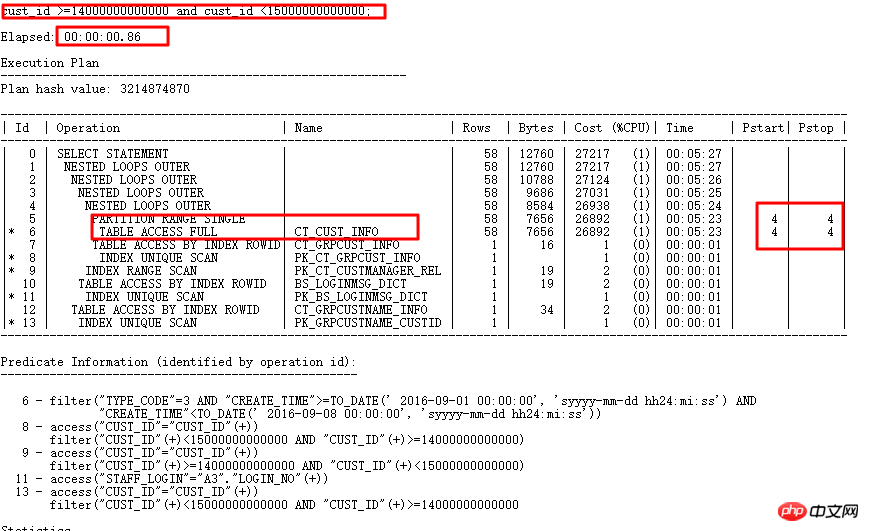
Ce qui suit est un cas typique d'audit SQL :
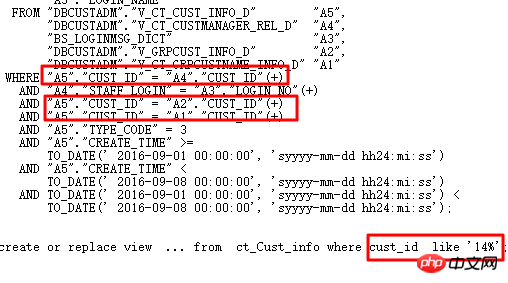
Le plan d'exécution est le suivant :
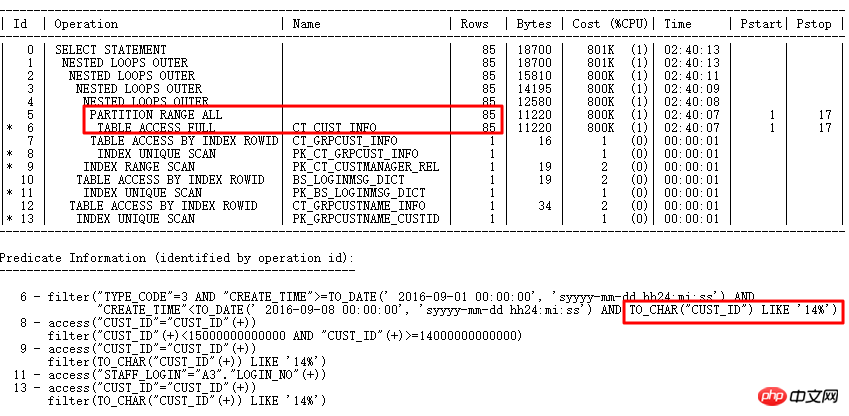
Le SQL d'origine s'exécute pendant 1688 s. Trouvez avec précision les points d'optimisation grâce à l'optimisation intelligente de l'audit SQL - les colonnes de partition ont une conversion de type. 0,86 s après optimisation.
L'audit SQL est un module de la plateforme de gestion des performances de base de données Xinju DPM Si vous souhaitez en savoir plus sur DPM, vous pouvez rejoindre Maître Zou Deyu (WeChat : carydy) pour la communication. et des discussions.
Aujourd'hui, je partage principalement avec vous quelques problèmes existant dans l'optimiseur Oracle et des solutions aux problèmes courants. Bien entendu, les problèmes de l'optimiseur ne se limitent pas à ceux partagés aujourd'hui, bien que CBO soit très puissant et ait été grandement amélioré. 12c, Cependant, il existe de nombreux problèmes. Ce n'est qu'en accumulant, en observant davantage et en maîtrisant certaines méthodes que nous pouvons élaborer une stratégie après avoir rencontré des problèmes et gagner la bataille.
Questions et réponses
Q1 : La jointure par hachage est-elle triée ? Pouvez-vous expliquer brièvement le principe de la jointure par hachage ?
A1 : ORACLE HASH JOIN lui-même n'a pas besoin d'être trié, ce qui est l'une des caractéristiques qui distinguent SORT MERGE JOIN. Le principe d'ORACLE HASH JOIN est relativement compliqué. Vous pouvez vous référer à la partie HASH JOIN des principes fondamentaux d'Oracle basés sur les coûts de Jonathan Lewis. La chose la plus importante pour HASH JOIN est de déterminer quand il sera lent en fonction du principe. , HASH_AREA_SIZE est trop petit et HASH TABLE ne peut pas être complètement placé dans la mémoire, l'opération HASH du disque se produira et la collision HASH mentionnée ci-dessus se produira.
Q2 : Quand ne faut-il pas indexer ?
A2 : Il existe de nombreux cas où l'indexation n'est pas utilisée. La première raison est que les informations statistiques sont inexactes. La deuxième raison est que l'indexation est moins efficace que l'analyse complète. Un problème courant est également que des opérations sont effectuées sur les colonnes d'index, ce qui entraîne l'impossibilité d'indexer. Il existe de nombreuses autres raisons pour lesquelles l'index ne peut pas être utilisé. Pour plus de détails, veuillez consulter le document MOS : Diagnostiquer pourquoi une requête n'utilise pas d'index (ID de document 67522.1).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!