
Maison >développement back-end >Tutoriel Python >Opérations de base de DataFrame introduites par la bibliothèque pandas
Opérations de base de DataFrame introduites par la bibliothèque pandas

- PHPzoriginal
- 2017-04-04 13:38:054836parcourir
Comment supprimer liste les caractères creux ?
La méthode la plus simple : new_list = [ x for x in li if x != '' ]
Aujourd'hui, c'est le 1er mai.
Cette partie étudie principalement les opérations de base chez les pandas basées sur les deux structures de données précédentes.
设有DataFrame结果的数据a如下所示: a b c one 4 1 1 two 6 2 0 three 6 1 6
1. Afficher les données (la méthode de visualisation de l' objet est également applicable aux séries)
1. de DataFrame Ou les xx dernières lignes
a=DataFrame(data);
a.head(6) signifie afficher les 6 premières lignes de données s'il n'y a aucun paramètre dans. head(), il sera affiché.
a.tail(6) signifie afficher les 6 dernières lignes de données. S'il n'y a pas de paramètres dans tail(), toutes les données seront affichées.
2. Afficher l'index, les colonnes et les valeurs de DataFrame
a.index; a.columns et ensuite
3.describe ()FonctionPour un résumé statistique rapide des données
a.describe() effectue des statistiques sur chaque colonne de données, y compris le nombre, la moyenne, la norme, chaque quantile, etc. .
4. Transposer les données
a.T
Trier les axes
a.tri _index(axis=1,ascending=False);
où axis=1 signifie trier toutes les colonnes de , et les nombres suivants se déplaceront également en conséquence. Le suivant ascending=False signifie trier par ordre décroissant, et la valeur par défaut est l'ordre croissant lorsque le paramètre est manquant.
6. Triez les valeurs dans le DataFrame
a.sort(columns='x')
C'est-à-dire, triez la colonne x dans a de petit à grand . Notez qu'il ne s'agit que de la colonne x et que le tri par axe ci-dessus fonctionnera sur toutes les colonnes.
2. Sélectionnez des objets
1. Sélectionnez les données de colonnes et de lignes spécifiques
a['x'] Ensuite, la colonne dont les colonnes sont x sera renvoyé, Notez que cette méthode ne peut renvoyer qu'une seule colonne à la fois. a.x signifie la même chose que a['x'].
Obtenez les données des lignes et sélectionnez
en découpant []. Par exemple : a[0:3] renverra les données des trois premières lignes.
2.loc sélectionne les données via des balises
a.loc['one'] indiquera par défaut que la ligne avec comportement 'one' est sélectionnée ;
a.loc[:,['a','b'] ] signifie sélectionner toutes les lignes et colonnes dont les colonnes sont a et b
a.loc[['one'; ,'two'],['a','b']] signifie sélectionner les deux lignes 'one' et 'two' et les colonnes dont les colonnes sont a et b
a.loc['one; ' ,'a'] a le même effet que a.loc[['one'],['a']], mais le premier affiche uniquement la valeur correspondante, tandis que le second affiche les étiquettes de ligne et de colonne correspondantes.
3.iloc sélectionne les données directement par emplacement
Ceci est similaire à la sélection par étiquette
a.iloc[1:2,1:2] sera affiché Les données dans la première ligne et la première colonne (la valeur après la tranche ne peut pas être obtenue)
a.iloc[1:2] signifie que lorsqu'il n'y a pas de valeur dans la colonne suivante, la ligne la position est sélectionnée à 1 par défaut. Les données ;
a.iloc[[0,2],[1,2]] signifient que vous pouvez sélectionner librement les données correspondant à la position de la ligne et de la colonne. .
4. Utilisez les conditions pour sélectionner
Utilisez une colonne séparée pour sélectionner les données
a[a.c>0] signifie sélectionner la colonne c Données supérieur à 0
Utilisez où sélectionner les données
a[a>0] Le tableau sélectionne directement toutes les données supérieures à 0 dans a
Utilisez isin() pour sélectionner des lignes spécifiques contenant des valeurs spécifiques dans la colonne
a1=a.copy()
a1[a1['one'].isin(['2','3']) ] Le tableau affiche toutes les lignes qui remplissent la condition : la valeur dans la première colonne contient "2", "3".
3. Valeur de réglage (affectation)
L'opération d'affectation peut être directement attribuée en fonction de l'opération de sélection ci-dessus.
Exemple a.loc[:,['a','c']]=9 signifie définir les valeurs de toutes les lignes des colonnes a et c sur 9
a.iloc[:,[1, 3] ]=9 signifie également définir les valeurs de toutes les lignes des colonnes a et c sur 9
En même temps, vous pouvez toujours utiliser des conditions pour attribuer des valeurs directement
a[ a>0]=-a signifie définir a dans Tous les nombres supérieurs à 0 sont convertis en valeurs négatives
4. Traitement des valeurs manquantes
Dans les pandas, utilisez np.nan pour remplacer valeurs manquantes Ces valeurs ne seront pas incluses dans le calcul par défaut. La méthode
1.reindex()
est utilisée pour modifier/ajouter/supprimer l'index sur l'axe spécifié , ce A une copie des données originales sera restituée.
a.reindex(index=list(a.index)+['five'],columns=list(a.columns)+['d'])
a.reindex(index=['one','five'],columns=list(a.columns)+['d'])
即用index=[]表示对index进行操作,columns表对列进行操作。
2.对缺失值进行填充
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
3.去掉包含缺失值的行
a.dropna(how='any')
表示去掉所有包含缺失值的行
五、合并
1.contact
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
例:a1=[b['a'],b['c']]
result=pd.concat(a1,axis=1,keys=['1','2'])
2.Append 将一行或多行数据连接到一个DataFrame上
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
3.merge类似于SQL中的join
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。
六、分组(groupby)
用pd.date_range函数生成连续指定天数的的日期
pd.date_range('20000101',periods=10)
def shuju():
data={
'date':pd.date_range('20000101',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=DataFrame(data)
print(a)
date gender height weight
0 2000-01-01 0 47 165
1 2000-01-02 0 46 179
2 2000-01-03 1 48 172
3 2000-01-04 0 45 173
4 2000-01-05 1 47 151
5 2000-01-06 0 45 172
6 2000-01-07 0 48 167
7 2000-01-08 0 45 157
8 2000-01-09 1 42 157
9 2000-01-10 1 42 164
用a.groupby('gender').sum()得到的结果为: #注意在python中groupby(''xx)后要加sum(),不然显示
不了数据对象。
gender height weight
0 256 989
1 170 643
此外用a.groupby('gender').size()可以对各个gender下的数目进行计数。
所以可以看到groupby的作用相当于:
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。
七、Categorical按某一列重新编码分类
如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下:
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female
所以可以看出重新编码后的编码会自动增加到dataframe最后作为一列。
八、相关操作
描述性统计:
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
2.统计某一列x中各个值出现的次数:a['x'].value_counts();
3.对数据应用函数
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
4.字符串相关操作
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。
九、时间序列
在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定起始日期。
此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下:
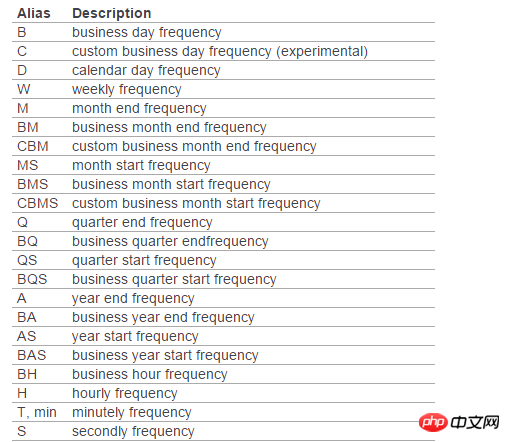
1.png
十、画图(plot)
在pycharm中首先要:import matplotlib.pyplot as plt
a=Series(np.random.randn(1000),index=pd.date_range('20100101',periods=1000))
b=a.cumsum()
b.plot()
plt.show() #最后一定要加这个plt.show(),不然不会显示出图来。
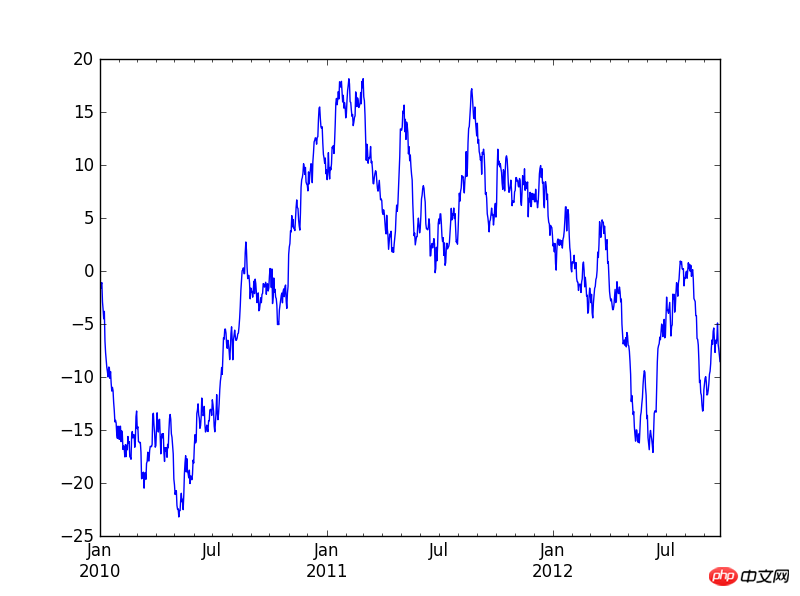
2.PNG
也可以使用下面的代码来生成多条时间序列图:
a=DataFrame(np.random.randn(1000,4),index=pd.date_range('20100101',periods=1000),columns=list('ABCD'))
b=a.cumsum()
b.plot()
plt.show()
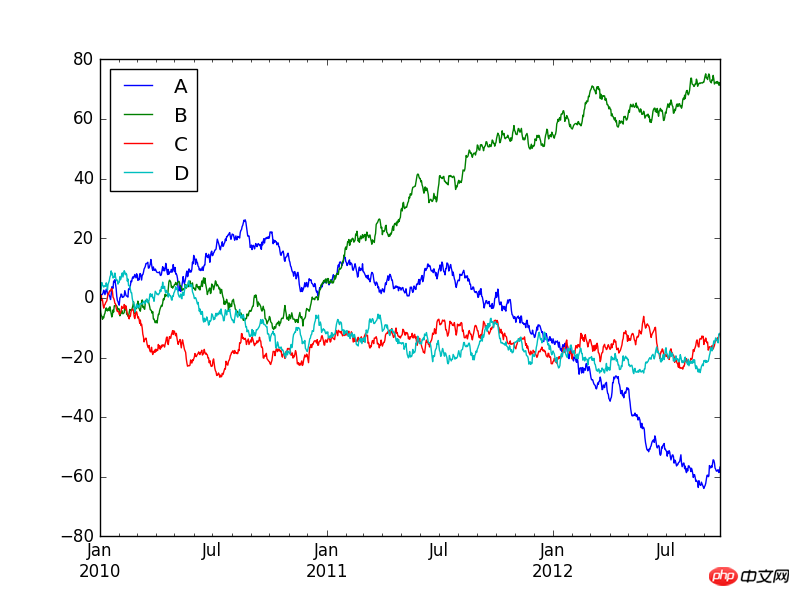
3.png
十一、导入和导出文件
写入和读取excel文件
虽然写入excel表时有两种写入xls和csv,但建议少使用csv,不然在表中调整数据格式时,保存时一直询问你是否保存新格式,很麻烦。而在读取数据时,如果指定了哪一张sheet,则在pycharm又会出现格式不对齐。
还有将数据写入表格中时,excel会自动给你在表格最前面增加一个字段,对数据行进行编号。
a.to_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls',sheet_name='Sheet1') a=pd.read_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls','Sheet1',na_values=['NA']) 注意sheet_name后面的Sheet1中的首字母大写;读取数据时,可以指定读取哪一张表中的数据,而 且对缺失值补上NA。 最后再附上写入和读取csv格式的代码: a.to_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',sheet_name='Sheet1') a=pd.read_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',na_values=['NA'])
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!