
Maison >développement back-end >Tutoriel XML/RSS >Analyse XML sous Android
Analyse XML sous Android

- PHPzoriginal
- 2017-04-04 10:55:521860parcourir
1. Introduction
La semaine dernière, j'avais besoin de comprendre un peu le contenu général du projet, mais j'étais confus au sujet de la partie d'analyse xml, donc ici Je vais enregistrer certaines des connaissances que j'ai acquises sur l'analyse XML.
2. Analyse
android Il existe trois principaux types d'analyseurs XML dans , l'analyseur DOM, l'analyseur SAX et l'analyseur pull
1.
ObjectModel) est un ObjectModèle pour les documents XML, qui peut être utilisé pour accéder directement aux documents XML à chaque partie. Il charge le contenu dans la mémoire en une seule fois et génère une structure arborescente. Il n'implique pas de rappels ni de gestion complexe des statuts . L'inconvénient est qu'il est inefficace lors du chargement de documents volumineux. documents volumineux. L'analyse de cette structure nécessite généralement de charger l'intégralité du document et de construire une arborescence avant de récupérer et de mettre à jour les informations sur les nœuds. Android prend entièrement en charge l'analyse DOM. lire,
rechercher, modifier, ajouter et supprimer etc. Comment fonctionne DOM : Utiliser DOM Lorsque vous travaillez sur un fichier XML, le fichier doit d'abord être analysé et divisé en éléments indépendants, <.> attributs et commentaires , etc., puis le fichier XML doit être traité en mémoire sous la forme d'une arborescence de nœuds, ce qui signifie que vous pouvez accéder au contenu du document via l'arborescence des nœuds. et modifiez le document selon vos besoins
Interfaces DOM couramment utiliséeset classes : Document : L'interface définit une série de méthodes d'analyse et de création de documents DOM. racine de l'arborescence des documents
et base du fonctionnement du DOMNode : Cette interface permet de traiter et d'obtenir les valeurs des nœuds et des sous-nœuds
hérite de l'interface Node et fournit des méthodes pour obtenir et modifier les noms et attributs des éléments XML.
NodeList<. nodes et le n actuel. cela vous permet d de mani it chaque>
DOMParser : Cette classe est la classe d'analyseur DOM dans Xerces d'Apache, qui peut analyser directement les fichiers XML.SAX (Simple API
pour
XML) Grâce au traitement en streaming, il n'enregistre pas d'informations. sur le contenu qu'il lit. Il s'agit d'une API XML qui utilise les événements comme pilotes
. Elle a une vitesse d'analyse rapide et prend moins de mémoire. Utilisez la
pour y parvenir. L'inconvénient est qu'il ne peut pas être annulé car il est piloté par des événements.
Son cœur est le modetraitement d'événements, qui fonctionne principalement autour des sources d'événements et des processeurs d'événements. Lorsque la source d'événement génère un événement, appelez la méthode de traitement correspondante du processeur d'événement et un événement peut être traité. Lorsque la source d'événement appelle une méthode spécifique dans le gestionnaire d'événements, elle doit également transmettre les informations d'état de l'événement correspondant au gestionnaire d'événements, afin que le gestionnaire d'événements puisse décider de son propre comportement en fonction de l'événement fourni. information. Le principe de fonctionnement de SAX : SAX analysera le document de manière séquentielle et notifiera la méthode de traitement des événements lors de l'analyse du début et de la fin du document (document), du début et de la fin de l'élément (élément), du contenu de l'élément (caractères), etc., méthode de traitement des événements pour effectuer le traitement correspondant, puis poursuivre la numérisation pour guider la numérisation du document jusqu'à la fin. Interfaces et classes SAX couramment utilisées : Attributs : utilisés pour obtenir le nombre, le nom et la valeur des attributs.
ContentHandler : définit les événements associés au document lui-même (par exemple, les balises d'ouverture et de fermeture). La plupart des candidatures s'inscrivent à ces événements.
DTDHandler : Définit les événements associés à la DTD. Il ne définit pas suffisamment d'événements pour signaler complètement la DTD. Si l’analyse de la DTD est requise, utilisez le DeclHandler facultatif.
DeclHandler est une extension de SAX. Tous les analyseurs ne le prennent pas en charge.
EntityResolver : définit les événements associés au chargement des entités. Seules quelques candidatures s'inscrivent à ces événements.
ErrorHandler : définissez les événements d'erreur. De nombreuses applications enregistrent ces événements pour signaler les erreurs à leur manière.
DefaultHandler : Il fournit l'implémentation par défaut de ces interfaces. Dans la plupart des cas, il est plus facile pour une application d'étendre DefaultHandler et de remplacer les méthodes pertinentes que d'implémenter directement une interface.
Ce qui suit est une description partielle :
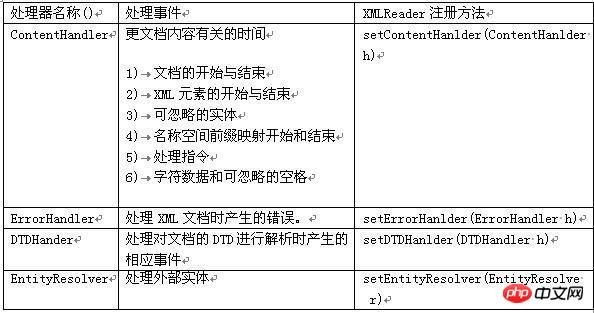
Description du processeur SAX
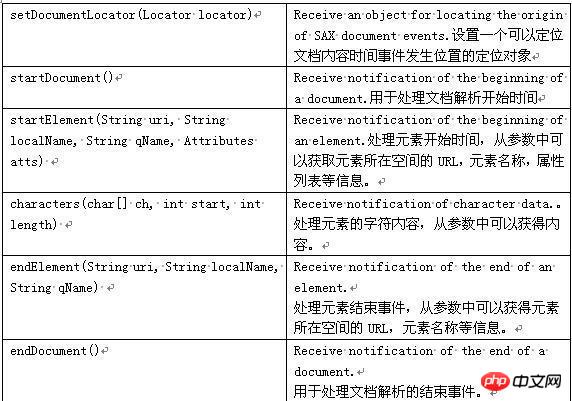
Explication de certaines méthodes courantes
Par conséquent, nous utilisons généralement XmlReader et DefaultHandler pour analyser les documents XML.
Processus d'analyse SAX :
startDocument --> startElement --> caractères --> endElement -->
Pull est intégré au système Android. C'est également la méthode officielle utilisée pour analyser les fichiers de mise en page. Pull est quelque peu similaire à SAX, et les deux fournissent des événements similaires, tels que des éléments de début et des éléments de fin. La différence est que le pilote d'événement de SAX doit rappeler la méthode correspondante. Vous devez fournir la méthode de rappel, puis appeler automatiquement la méthode correspondante dans SAX. L’analyseur Pull n’est pas tenu de fournir une méthode de déclenchement. Car l’événement qu’il a déclenché n’est pas une méthode, mais un nombre. Il est facile à utiliser et efficace. Android recommande officiellement aux développeurs d'utiliser la technologie d'analyse Pull. La technologie d'analyse pull est une technologie open source développée par un tiers et peut également être appliquée au développement JavaSE.
La
constanterenvoyée par pull : lit l'instruction de XML et renvoie START_DOCUMENT
lit la fin de XML et renvoie END_DOCUMENT ; ;
Lire la balise de début de XML et renvoyer START_TAG;
Lire la balise de fin de XML et renvoyer END_TAG;
Lire le texte de XML et renvoyer TEXT;
Comment fonctionne pull : pull fournit un élément de début et un élément de fin. Lorsqu'un élément démarre, nous pouvons appeler parser.
suivantText extrait toutes les données de caractères du document XML. Lorsque l'interprétation d'un document se termine, l'événement EndDocument est automatiquement généré.
Interfaces et classes d'extraction XML couramment utilisées :
XmlPullParser : l'analyseur d'extraction XML est une interface qui fournit des fonctions d'analyse de définition dans XMLPULL VlAP1.
XmlSerializer : C'est une interface qui définit la séquence des ensembles d'informations XML.
XmlPullParserFactory : Cette classe est utilisée pour créer des analyseurs XML Pull dans l'API XMPULL V1.
XmlPullParser
Exception: renvoie une seule erreur liée à l'analyseur pull XML. processus d'analyse pull :
start_document --> end_document --> start_tag -->end_tag
(Je ne l'ai pas utilisée) Dans l'API Android, Android. util. La classe Xml peut également analyser les fichiers XML. La méthode d'utilisation est similaire à celle de SAX. Vous devez également écrire un gestionnaire pour gérer l'analyse XML, mais il est plus simple à utiliser que SAX, comme indiqué ci-dessous :
Avec Android. . util. XML implémente l'analyse XML :
MyHandler myHandler=new MyHandler0;
android. util. Xm1. parse(url.openC0nnection().getlnputStream(),
1. Créez d'abord un document XML de référence (placez-le dans le répertoire asset
s)
Le canal Lingqu est situé dans le comté de Xing'an, dans la région autonome Zhuang du Guangxi. C'est l'un des canaux les plus anciens au monde et a la réputation de « la perle de l'architecture ancienne de conservation de l'eau au monde ». Dans les temps anciens, Lingqu était connu sous le nom de Canal Qin Zhuoqu, Lingqu, Douhe et Xing'an. Il a été construit et ouvert à la navigation en 214 avant JC. Il fonctionne toujours il y a 2217 ans.
db7b8322e08244d3c.jpg
& lt; L'île de Sanshan, traversant Jiaoan, Jiaozhou, Pingdu, Gao Mi, Changyi, Laizhou, etc., longue de 200 kilomètres, avec une superficie de bassin de 5 400 kilomètres carrés, traverse la péninsule du Shandong du nord au sud et relie la Mers Jaune et Bohai. Le canal Jiaolai se divise du nord au sud au niveau du bassin versant à l'est du village de Pingdu Yaojia. Le flux sud s'écoule de Mawankou dans la baie de Jiaozhou et s'appelle la rivière Nanjiolai, longue de 30 kilomètres. Le courant nord coule de Haicangkou dans la baie de Laizhou et constitue la rivière Beijiaolai, longue de plus de 100 kilomètres.
;> & Lt; INTRODUCTION & GT
http://imgsrc.baidu.com/baike/pic/item/389aa8fdb7b8322e08244d3c.jpg
>Nous devons utiliser un objet River pour sauvegarder données pour faciliter l'observation des informations sur les nœuds et extraire la classe River
publicclass
River {
String
nom ; // nomInteger
longueur;// longueur
Introduction à la chaîne;// introduction
String Imageurl ;//
imageurl
public String getName() {
return
name;}public void setName(String name) {this.name = name;
public void setLength(Integer length) {}public String getIntroduction() {
retour de l'introduction ;}public void setIntroduction(String introduction) {
this.introduction = introduction;}public String getImageurl () {
return Imageurl;}public void setImageurl(String imageurl) {Imageurl = imageurl;} @Overridepublic String toString() {return "River [name=" + nom + ", length=" + length + ", introduction="+ introduction + ", Imageurl=" + Imageurl + "]";}}Les étapes de traitement spécifiques lors de l'utilisation de l'analyse DOM sont :
1 Utilisez d'abord DocumentBuilderFactory pour créer une instance de DocumentBuilderFactory
2 Utilisez ensuite DocumentBuilderFactory pour créer DocumentBuilder
3 puis chargez le document XML (Document),
4 puis récupérez le nœud racine (Element) du document,
5 puis récupérez le nœud racine Le liste de tous les nœuds enfants (NodeList),
6, puis utilisez-le pour obtenir le nœud qui doit être lu dans la liste des nœuds enfants.
Ensuite, nous commençons à lire l'objet document XML et à l'ajouter à la liste :
Le code est le suivant : Ici, nous utilisons river.xml dans Assets, vous devez alors lire ce fichier XML et renvoyer le flux d'entrée. La méthode de lecture est : inputStream=this.context.getResources().getAssets().open(fileName); Le paramètre est le chemin du fichier XML, bien sûr le la valeur par défaut est actifs. Le répertoire est le répertoire racine.
Ensuite, vous pouvez utiliser la méthode d'analyse de l'objet DocumentBuilder pour analyser le flux d'entrée et renvoyer l'objet document, puis parcourir les attributs de nœud de l'objet document.
/*** Méthode XML d'analyse DOM
* @param filePath
* @return
*/
liste privéeDOMfromXML(String filePath) {
ArrayListlist = new ArrayList();
DocumentBuilderFactory factory = null;
DocumentBuilder builder = null;
Document document = null ;
InputStream inputStream = null;
//Build parser
factory = DocumentBuilderFactory.newInstance();
essayez {
builder = factory.newDocumentBuilder();
//Trouvez le fichier XML et chargez-le
inputStream = this.getResources().getAssets().open(filePath);//Default after getAssets Le répertoire racine est actifs
document = builder.parse(inputStream);
//Trouver l'élément racine
Element root=document.getDocumentElement();
NodeList nodes=root.getElementsByTagName(RIVER);
//Parcourir tous les nœuds enfants du nœud racine, toutes les rivières sous les rivières
River river = null;
for (int i = 0; i < nodes.getLength(); i++) {
river = new River();
//Obtenir la rivière element node
Element riverElement = (Element) nodes.item(i);
//Définissez les valeurs des attributs de nom et de longueurdans river
river. setName(riverElement.getAttribute("name") );
river.setLength(Integer.parseInt(riverElement.getAttribute("length")));
//Obtenir les sous-balises
Introduction de l'élément = (Element) riverElement.getElementsByTagName(INTRODUCTION).item(0);
Element imageurl = (Element) riverElement.getElementsByTagName(IMAGEURL).item(0);
//Définissez les attributs d'introduction et d'imageurl
river.setIntroduction(introduction.getFirstChild().getNodeValue());
river.setImageurl(imageurl.getFirstChild().getNodeValue( ));
list.add (river);
}
} catch (ParserConfigurationException e) {
// TODO Bloc catch généré automatiquement
e.print StackTrace();
} catch (IOException e) {
// TODO Bloc catch généré automatiquement
e.printStackTrace();
} catch (SAXException e) {
// TODO Bloc catch généré automatiquement
e.printStackTrace();
}
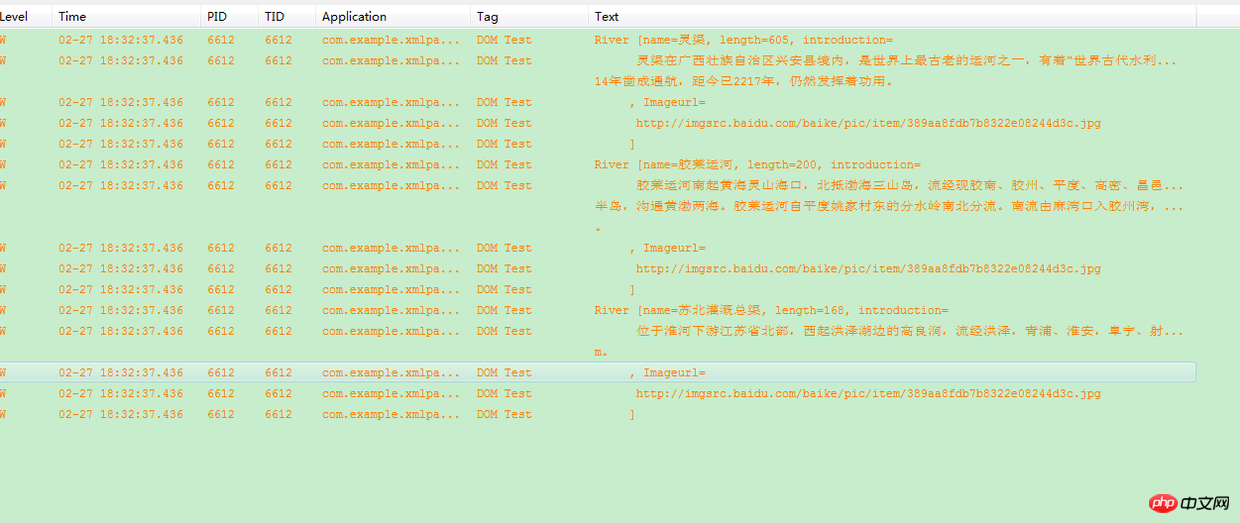
for ( River river : liste) {
Log.w("DOM Test", river.toString());
}
liste de retour ;
}
est ajouté à la liste ici, puis nous utilisons le journal pour les imprimer. Comme le montre la figure :
Résultats de l'analyse XML
Utiliser SAX analyse Les étapes de traitement spécifiques sont :
1 Créer un objet SAXParserFactory
2 Renvoyer un analyseur SAXParser selon la méthode SAXParserFactory.newSAXParser()
3 Selon SAXParser L'analyseur obtient l'objet source d'événement XMLReader
4 Instancie un objet DefaultHandler
5 Connecte l'objet source d'événement XMLReader à la classe de traitement d'événements DefaultHandler
6 Appels la méthode d'analyse de XMLReader à partir des données XML obtenues à partir de la source d'entrée
7 renvoie la combinaison ensemble de données dont nous avons besoin via DefaultHandler.
Le code est le suivant :
/**
* XML analysé par SAX
* @param filePath
* @return
*/
private ListSAXfromXML(String filePath) {
ArrayListlist = new ArrayList();
//Build analyseur
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = null;
XMLReader xReader = null;
essayez {
parser = factory.newSAXParser();
//Obtenez la source de données
xReader = parser.getXMLReader();
//Définir le processeur
RiverHandler handler = new RiverHandler();
xReader.setContentHandler(handler);
//Analyser le fichier XML
xReader.parse(new InputSource(this.getAssets().open(filePath)));
list = handler.getList();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
for (River river : liste) {
Log.w("DOM Test", river.toString() );
}
liste de retour;
}
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!