
Maison >interface Web >js tutoriel >Robot d'exploration de nœuds avancé - connexion
Robot d'exploration de nœuds avancé - connexion

- PHPzoriginal
- 2017-04-04 10:19:442363parcourir
ContenuDans le scénario d'entrée de nœud de l'article précédent - robot d'exploration, nous avons présenté l'implémentation la plus simple du robot d'exploration de nœuds. Cet article va plus loin sur la base originale et explique comment contourner la connexion et explorer les données dans la zone de connexion. 🎜>
- Base théorique
- Comment conserver le statut de connexion
- Comment le navigateur fait-il ? >://www.php.cn/php/php-TVOS-denglu.html" target="_blank">ConnexionInterface Obtenir
- Extension
- Résumé
- Comment maintenir le statut de connexion
- http en tant que protocole A sans
état
ne maintiendra pas une longue connexion entre le client et le serveur. Comment le serveur identifie-t-il les interfaces provenant du même client entre. demandes et réponses indépendantes ? Vous pouvez facilement penser au mécanisme suivant :
- Interface de demande de connexion
session
Id.pngLe noyau de ce mécanisme est l'identifiant de session (sessionId) : Lorsque le client demande au serveur, le serveur détermine que le client n'a pas transmis l'identifiant de session. D'accord, ce type est nouveau, générez. pour cela Un sessionId, stocké en mémoire, et renvoyé au client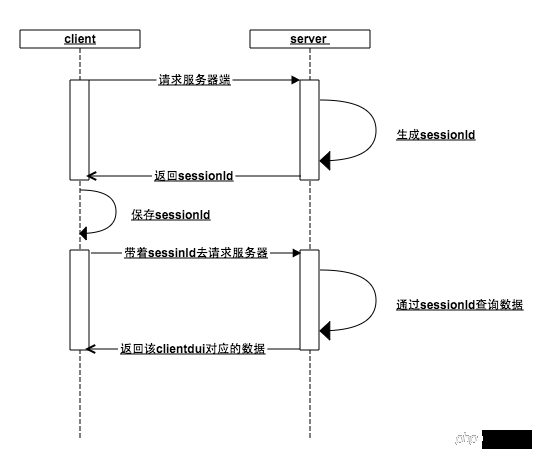
Si dans une étape précédente, l'utilisateur a accédé à l'interface de connexion, alors à ce moment le seesionId est déjà dans la mémoire en tant que key, et le les données utilisateur sont stockées dans la mémoire sous forme de valeur
), le serveur peut renvoyer les données correspondant au client en fonction de l'identifiant unique de sessionId- Que le client ou le serveur perde le sessionId, les étapes précédentes seront répétées. Personne ne connaît plus personne, recommencez
-
D'abord, le client établit une association avec le serveur via sessionId, puis l'utilisateur. établit une association avec le serveur via le client (paire clé-valeur de sessionId et de données utilisateur), conservant ainsi l'état de connexion Comment le navigateur fait-il
En fait, le navigateur suit-il ce qui précède. Qu'en est-il de la conception du mécanisme ? C'est vrai !
bs-sid.pngQue fait le navigateur :1. Le navigateur fait dans une requête http. , le cookie correspondant au nom de domaine de l'adresse de la requête sera ajouté à l'en-tête de la requête http (si le cookie n'est pas désactivé par l'utilisateur). Dans l'image ci-dessus, la première requête au serveur contient également un cookie dans la requête. en-tête, mais il n'y a pas encore de sessionId dans le cookie
2. Le navigateur définit le cookie en fonction du
Set-Cookie dans l'en-tête de réponse du serveur. À cette fin, le serveur mettra le sessionId généré. into Set-cookieLorsque le navigateur reçoit l'instruction Set-Cookie, il définira un cookie local avec le nom de domaine de l'adresse de la demande comme clé. Généralement, lorsque le serveur renvoie le Set-. cookie, le délai d'expiration du sessionId est défini sur le navigateur pour se fermer par défaut. Il expire lorsque le navigateur est ouvert. C'est pourquoi le navigateur est une session de l'ouverture à la fermeture (certains sites Web peuvent également être configurés pour rester connectés et). définir des cookies qui n'expireront pas avant longtemps)
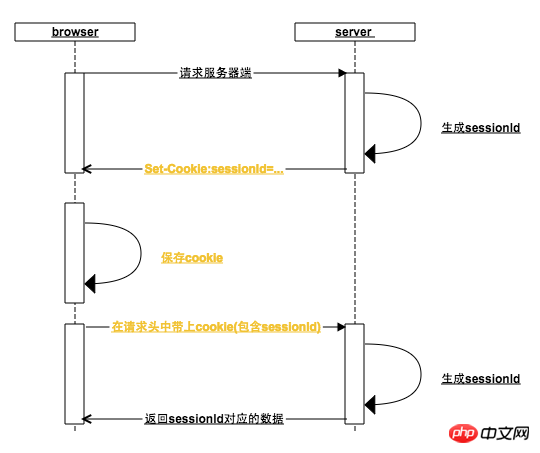
3. Lorsque le navigateur s'ouvre à nouveau Lorsqu'une requête est lancée en arrière-plan, le cookie dans l'en-tête de la requête contient déjà le sessionId Si l'utilisateur. a déjà visité l'interface de connexion, alors les données utilisateur peuvent être
en fonction du sessionId
Il n'y a aucune preuve, voici un exemple :
1). page ouverte par
chrome pour retrouver tous les fichiers sous http://www.jianshu.com dans l'application Cookie, saisissez la rubrique Réseau et cochez conserver le journal (sinon, vous ne pourrez pas voir le journal précédent après la redirection de la page)
Connectez-vous
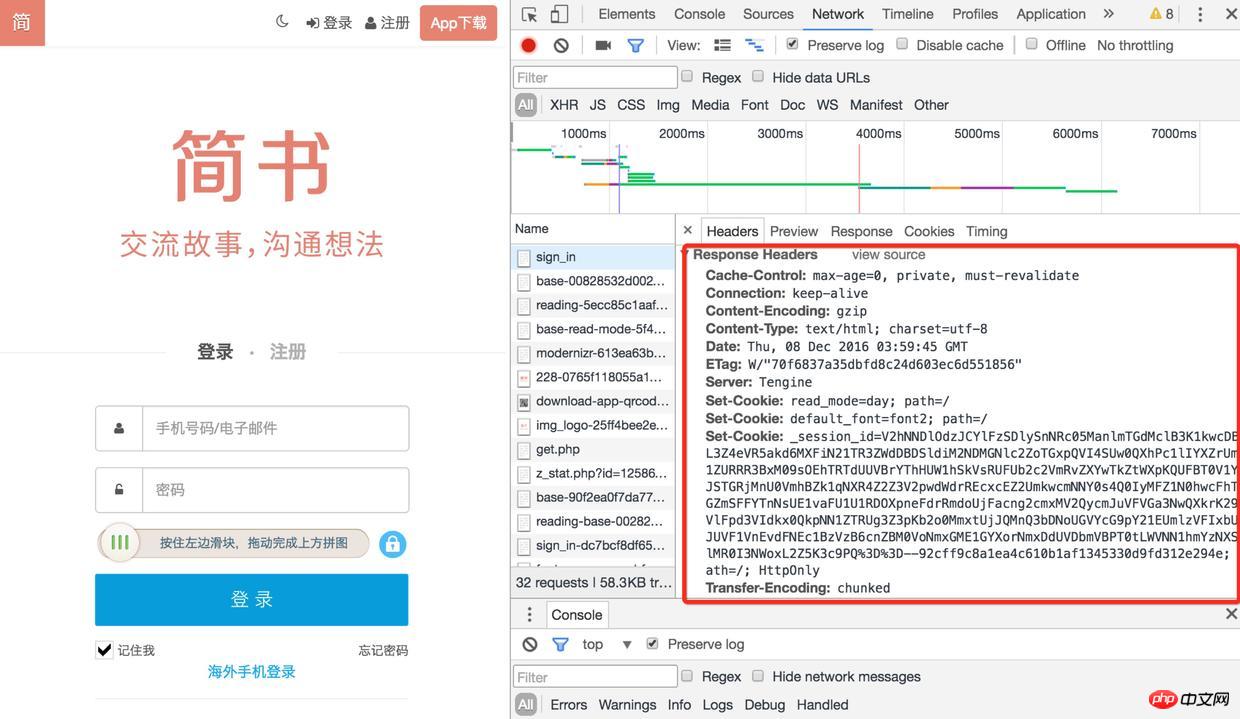
Connexion
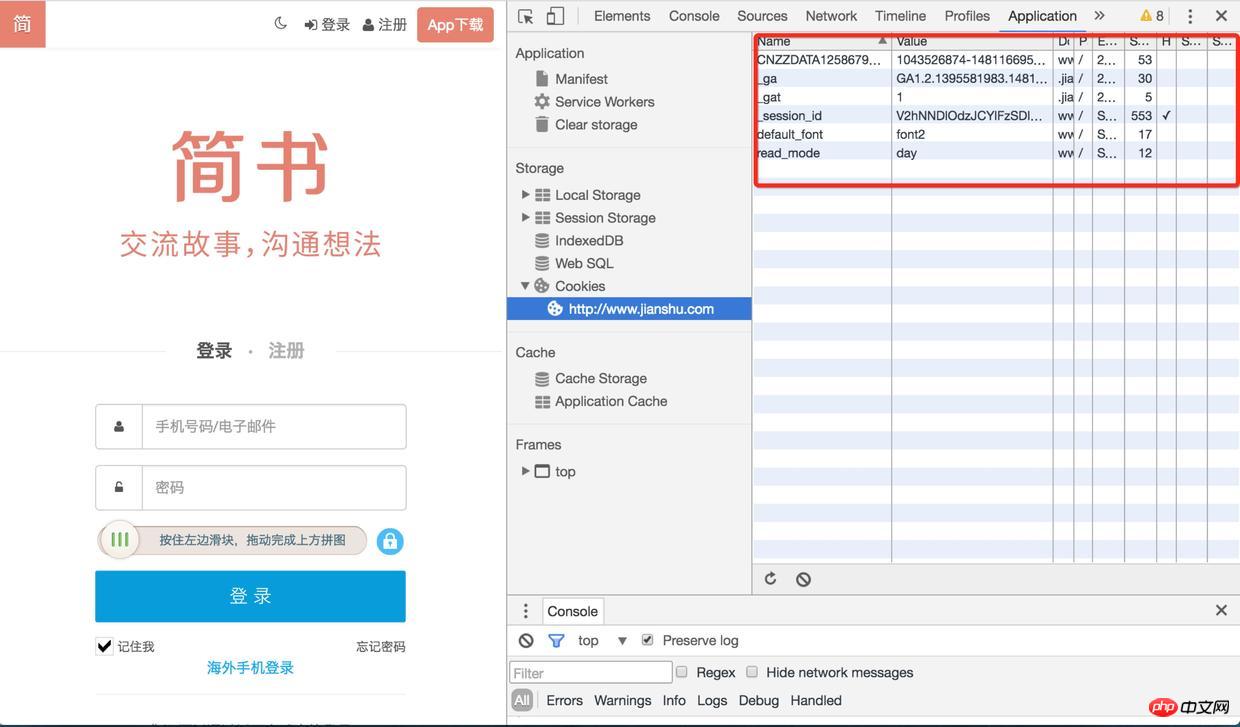
3). Lorsque vous vérifiez à nouveau le cookie, l'identifiant de session a été enregistré et vous pourrez le demander la prochaine foisAutres Lors de l'utilisation de l'interface (comme l'obtention d'un code de vérification, la connexion), cet identifiant de session sera apporté. Après la connexion, les informations de l'utilisateur seront également associées à l'identifiant de session
. 
Connexion
2. Implémentation du nœud
Nous devons simuler le mode de fonctionnement du navigateur et explorer les données dans la connexion. zone du site
J'en ai trouvé un sans vérification Testez le site Web avec le code de vérification S'il y a un code de vérification, l'identification du code de vérification est impliquée (le login n'est pas pris en compte, la complexité du code de vérification est impressionnante). . La section suivante explique
Accéder à l'interface de connexion pour obtenir des cookies
// 浏览器请求报文头部部分信息
var browserMsg={
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36",
'Content-Type':'application/x-www-form-urlencoded'
};
//访问登录接口获取cookie
function getLoginCookie(userid, pwd) {
userid = userid.toUpperCase();
return new Promise(function(resolve, reject) {
superagent.post(url.login_url).set(browserMsg).send({
userid: userid,
pwd: pwd,
timezoneOffset: '0'
}).redirects(0).end(function (err, response) {
//获取cookie
var cookie = response.headers["set-cookie"];
resolve(cookie);
});
});
}
Vous devez capturer une requête sous Chrome pour obtenir des informations d'en-tête de requête. , car le serveur peut vérifier ces informations d'en-tête de demande. Par exemple, sur le site Web que j'ai expérimenté, je n'ai pas transmis l'agent utilisateur au début. Le serveur a découvert que la requête ne provenait pas du serveur et a renvoyé une chaîne de messages d'erreur, donc je l'ai fait plus tard. configurez l'agent utilisateur et mettez J'ai fait semblant d'être un navigateur Chrome ~~
superagent est une bibliothèque de requêtes HTTP côté client Vous pouvez l'utiliser pour envoyer facilement des requêtes et traiter des cookies. (appelez http.request vous-même pour fonctionner. Les données du champ d'en-tête ne sont pas si pratiques. Après avoir obtenu le set-cookie, vous devez l'assembler dans un cookie au format approprié). redirects(0) est principalement configuré pour ne pas rediriger
Demander l'interface dans la zone de connexion
function getData(cookie) {
return new Promise(function(resolve, reject) {
//传入cookie
superagent.get(url.target_url).set("Cookie",cookie).set(browserMsg).end(function(err,res) {
var $ = cheerio.load(res.text);
resolve({
cookie: cookie,
doc: $
});
});
});
}
Après avoir obtenu le set-cookie à l'étape précédente, passez dans la méthode getData, une fois qu'il est défini sur la requête via le superagent (set-cookie sera formaté en cookie), vous pouvez normalement obtenir les données dans la connexion
Dans des scénarios réels, cela peut ne pas être aussi fluide. Parce que différents sites Web ont des mesures de sécurité différentes. Par exemple : certains sites Web peuvent avoir besoin de demander un jeton au préalable, certains sites Web doivent crypter des paramètres et certains ont une sécurité et un anti-rejeu plus élevés. mécanismes. Dans les robots d'exploration directionnels, cela nécessite une analyse détaillée du mécanisme de traitement du site Web. Si vous ne pouvez pas le contourner, arrêtez-le ~~
Mais cela suffit encore pour traiter le contenu général et les sites Web d'informations
Ce qui est demandé via la méthode ci-dessus est juste un morceau de htmlstring Voici l'ancienne méthode. Utilisez la bibliothèque cheerio pour charger la chaîne, et vous pouvez obtenir un jquery dom. >Object, vous pouvez utiliser dom comme jquery C'est vraiment un artefact, fait avec conscience ! 3. Comment casser le code de vérification s'il y en a un ?
À combien de sites Web pouvez-vous vous connecter sans saisir le code de vérification ? Bien entendu, nous n'essaierons pas d'identifier le code de vérification de 12306. Nous ne nous attendons pas à ce qu'un code de vérification aussi consciencieux soit trop jeune et trop simple comme Zhihu puisse encore être contesté
<.>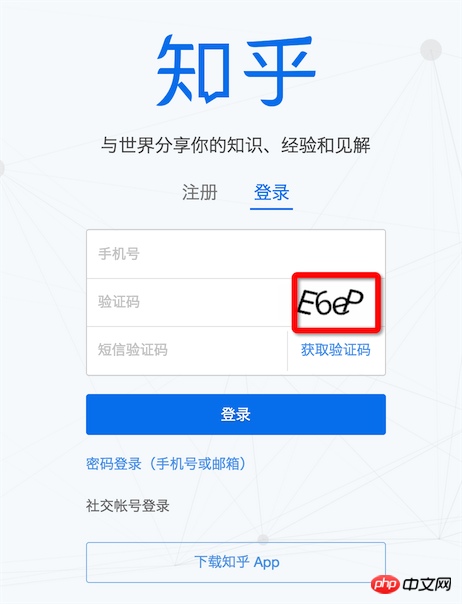 Zhihu Login
Zhihu Login
implémente une reconnaissance simple des codes de vérification
Cependant, même si Graphicsmagick est utilisé pour prétraiter les images, il ne peut pas garantir un taux de reconnaissance élevé. Pour cette raison, il. est toujours possible. Pour entraîner Tesseract, reportez-vous à : Utilisez l'outil jTessBoxEditor pour entraîner les échantillons Tesseract3.02.02 afin d'améliorer le taux de reconnaissance du code de vérification
La question de savoir si vous pouvez atteindre un taux de reconnaissance élevé dépend de votre personnage~~~ 4. Extension
Il existe un moyen plus simple de contourner l'état de connexion, qui consiste à utiliser PhantomJS. Phantomjs est un serveur open source js basé sur webkit
api. être considéré comme un navigateur, mais vous pouvez le contrôler via le script js.
Puisqu'il simule complètement le comportement du navigateur, vous n'avez pas du tout besoin de vous soucier du set-cookie et du cookie. Il vous suffit de simuler l'opération de clic de l'utilisateur (bien sûr, si. il y a un code de vérification, vous devez quand même l'identifier)
Cette méthode n'est pas sans défauts. Elle simule complètement le comportement du navigateur, ce qui signifie qu'elle ne manque aucune requête et doit charger des js, css et images dont vous n'avez peut-être pas besoin. 🎜>Pour les ressources, il faut cliquer sur plusieurs pages pour atteindre la page de destination, ce qui est moins efficace que d'accéder directement à l'url cible
Recherchez si vous êtes intéressé5. Résumé
Bien que je parle de la connexion du robot d'exploration de nœuds, j'ai déjà parlé de nombreux principes. Le but est que si vous souhaitez modifier le. langage pour le mettre en œuvre, vous pouvez le faire facilement. Encore une fois, la même phrase : Il est important de comprendre le principe
Vous êtes invités à laisser un message pour en discuter. Si cela vous est utile, veuillez laisser. un like~~
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript