
Maison >Java >javaDidacticiel >Explication détaillée de l'analyse du code source du cadre de collection Java LinkedHashSet et LinkedHashMap (image)
Explication détaillée de l'analyse du code source du cadre de collection Java LinkedHashSet et LinkedHashMap (image)

- 黄舟original
- 2017-03-28 10:57:302972parcourir
Introduction générale
Si vous avez lu les articles précédents sur HashSet et HashMap, ainsi que TreeSet et TreeMap Pour l'explication, vous devez pouvoir penser que LinkedHashSet et LinkedHashMap qui seront expliqués dans cet article sont en fait la même chose. LinkedHashSet et LinkedHashMap ont également la même implémentation en Java. Le premier enveloppe simplement le second, c'est-à-dire qu'à l'intérieur de LinkedHashSet il y a un . LinkedHashMap (Modèle d'adaptateur) . Par conséquent, cet article se concentrera sur l’analyse de LinkedHashMap.
LinkedHashMap implémente l'interface Map, qui permet aux éléments avec key d'être null d'être insérés et aux éléments avec value d'être null à insérer. Comme son nom l'indique, le conteneur est un mélange de liste liée et de HashMap, ce qui signifie qu'il satisfait à la fois HashMap et liste chaînée. Pensez à LinkedHashMap comme à un HashMap amélioré avec une liste chaînée.
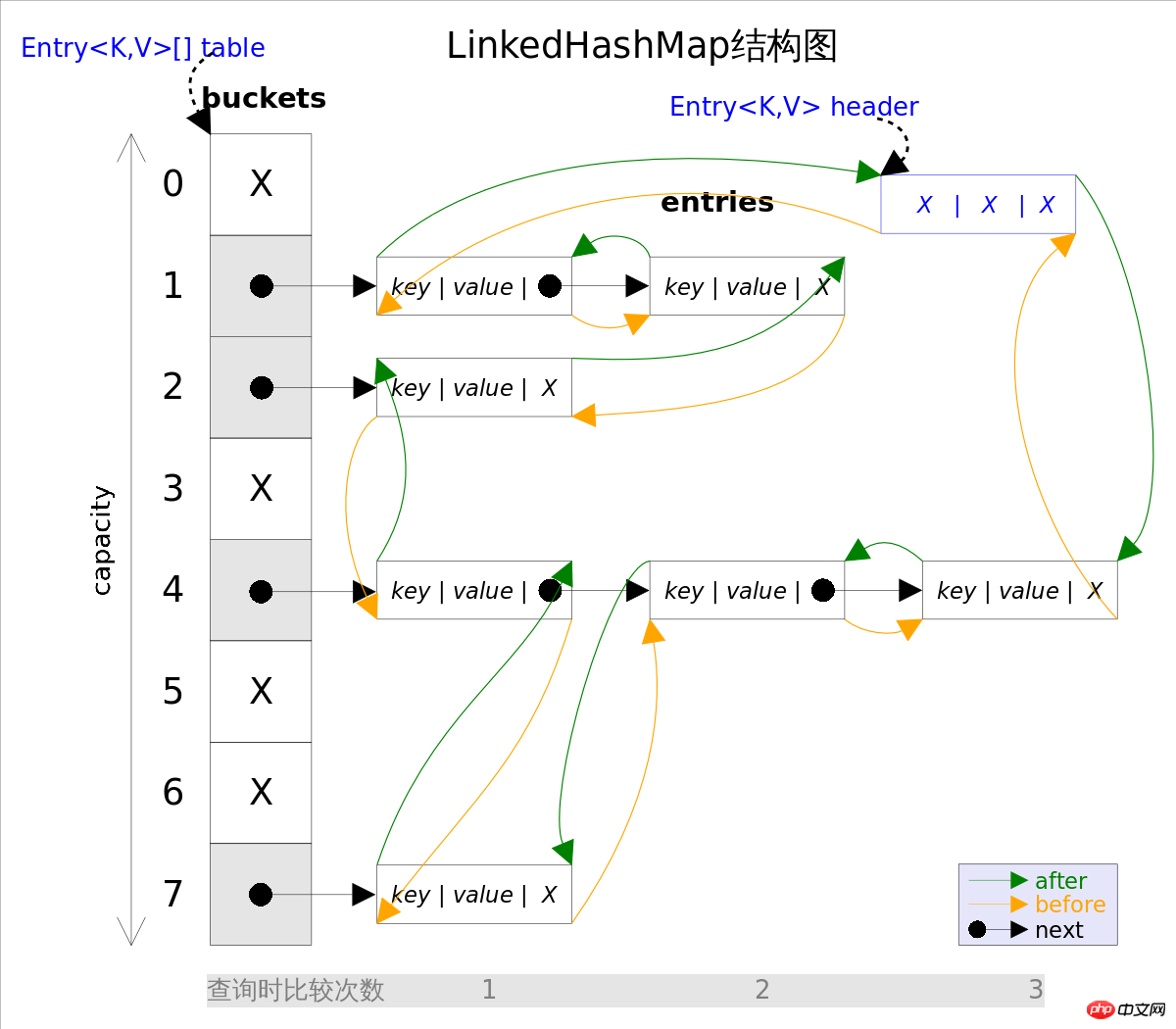
LinkedHashMap est une sous-classe directe de HashMap, la seule différence entre les deux isLinkedHashMap est basé sur HashMap et utilise une liste à double lien pour connecter tous les afin de garantir que l'ordre d'itération des éléments est le même que l'ordre d'insertion. entry. La figure ci-dessus montre le diagramme de structure de LinkedHashMap La partie principale est exactement la même que celle de HashMap, avec l'ajout de pointant vers la tête de la liste doublement chaînée (qui est un élément factice), et header L'ordre d'itération de la liste doublement chaînée est l'ordre d'insertion de entry.
Itère LinkedHashMap sans parcourir l'intégralité du comme le fait HashMap. il vous suffit de parcourir directement la liste doublement chaînée pointée par table header, ce qui signifie que le temps d'itération de LinkedHashMap n'est lié qu'au nombre de et n'a rien à voir avec la taille de entry . table
LinkedHashMap : la capacité initiale et le facteur de charge. La capacité initiale spécifie la taille initiale de et le facteur de charge est utilisé pour spécifier la valeur critique pour l'expansion automatique. Lorsque le nombre de table dépasse entry, le conteneur sera automatiquement agrandi et rehaché. Pour les scénarios dans lesquels un grand nombre d’éléments sont insérés, la définition d’une capacité initiale plus grande peut réduire le nombre de répétitions. Lorsque capacity*load_factor
dans LinkedHashMap ou LinkedHashSet, deux méthodes nécessitent une attention particulière : et hashCode() . La méthode equals() détermine dans quel hashCode() l'objet sera placé. Lorsque les valeurs de hachage de plusieurs objets sont en conflit, la méthode bucket détermine si ces objets sont "le même objet" equals(). Par conséquent, si vous souhaitez mettre un objet personnalisé dans ou LinkedHashMap, vous avez besoin des méthodes *@Override*LinkedHashSet et hashCode(). equals()
LinkedHashMap qui est le même que la source Map ordre d'itération comme suit :
void foo(Map m) {
Map copy = new LinkedHashMap(m);
} out of Pour des raisons de performances, LinkedHashMap est asynchrone (non synchronisé). S'il doit être utilisé dans un environnement multithread, les programmeurs doivent se synchroniser manuellement ou utiliser ce qui suit : méthode pour synchroniser LinkedHashMap Enveloppé dans synchrone :
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
get La méthode (<p>Object key)</p> renvoie le get(<a href="http://www.php.cn/wiki/60.html" target="_blank">Object</a> key) correspondant en fonction de la valeur key spécifiée. Le processus de cette méthode est presque exactement le même que celui de la méthode value Les lecteurs peuvent se référer eux-mêmes à l'article précédent et ne seront pas répétés ici. La méthode HashMap.get()put()
ajoute la paire put(K key, V value) spécifiée à key, value. Cette méthode recherchera d'abord map pour voir s'il contient le tuple, s'il est inclus, il retournera directement. Le processus de recherche est similaire à la méthode map s'il n'est pas trouvé, un nouveau get() sera. inséré via la méthode addEntry(int hash, K key, V value, int bucketIndex) 🎜>. entry
ici a deux significations :
- Du point de vue de
, le nouveau
tableIt doit être inséré dans leentrycorrespondant. Lorsqu'il y a un conflit de hachage, la méthode d'insertion de tête est utilisée pour insérer le nouveaubucketdans l'en-tête de la liste chaînée du conflit.entry从
header的角度看,新的entry需要插入到双向链表的尾部。
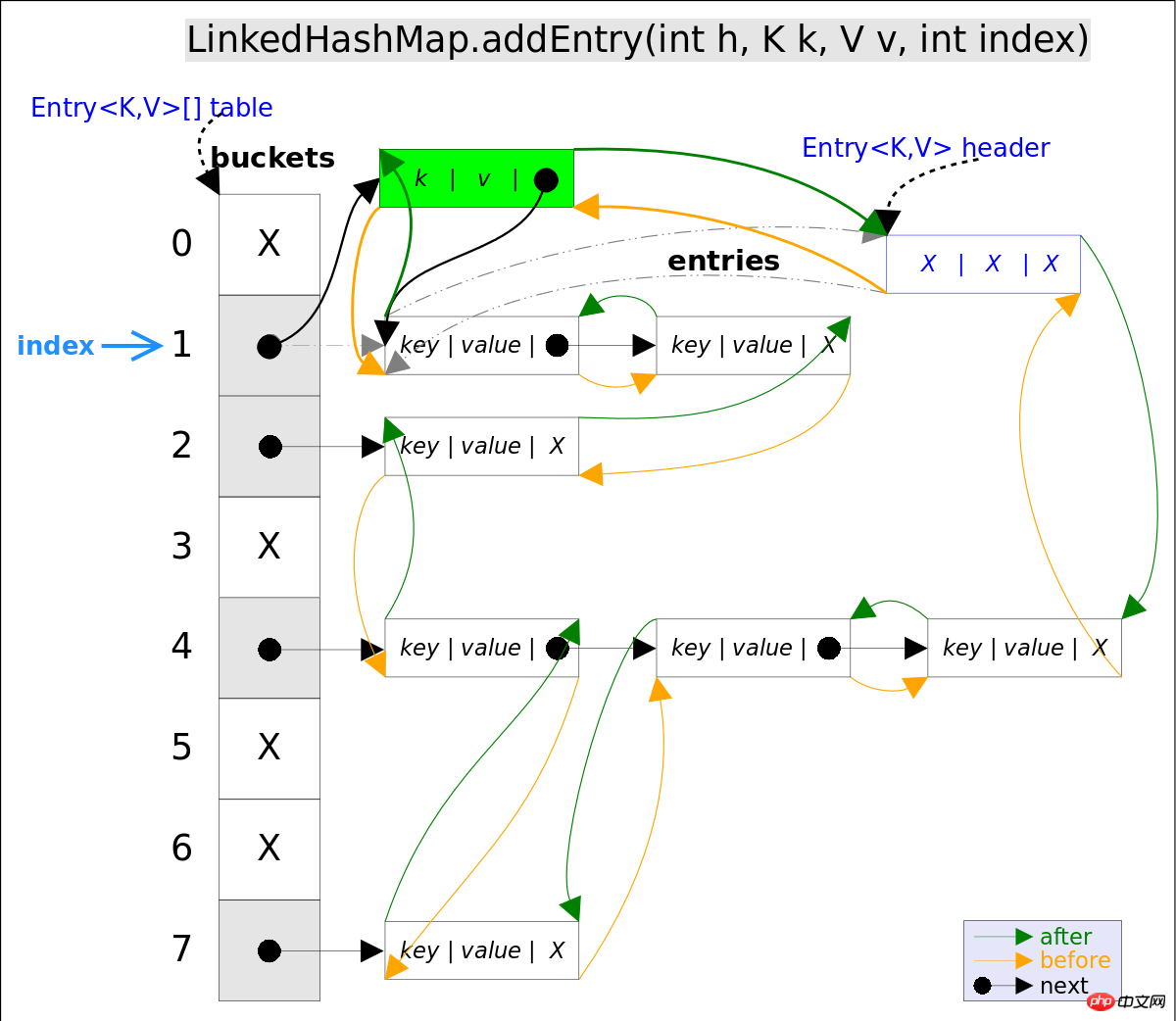
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从
table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。从
header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。

removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}LinkedHashSet
前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!