
Maison >développement back-end >Tutoriel XML/RSS >Introduction détaillée à l'utilisation de la pensée XML pour organiser les données (image)
Introduction détaillée à l'utilisation de la pensée XML pour organiser les données (image)

- 黄舟original
- 2017-03-27 17:20:051633parcourir
Avant-propos
Les temps ont changé.
Auparavant, les données étaient principalement saisies manuellement et transférées depuis des terminaux dotés de protocoles réseau dédiés vers de grandes boîtes en fer dans des « maisons de verre ». Aujourd'hui, l'information est partout et partout, mais elle n'est peut-être pas toujours résumée dans votre entreprise. , nous partageons souvent des données dans un monde « plat », où il existe davantage de canaux pour les sources d'informations et où les informations elles-mêmes changent plus fréquemment. De plus, avec l'émergence d'une série de concepts tels que le Web 2.0, l'Entreprise 2.0 et l'Internet Service Bus, vous constatez qu'il est beaucoup moins pratique de trouver l'adresse de l'entrepôt fournie par le fournisseur depuis votre propre « maison de verre » que Google. Carte.
Il semble que toutes les chaînes pesant sur les données dans le passé ont été brisées une par une sous Internet, mais en tant que praticiens de l'informatique, notre travail consiste à fournir aux utilisateurs les données dont ils ont besoin et les moyens qu'ils souhaitent obtenir. information, donc application Il doit être capable de résister à divers changements, y compris les changements dans l'interface utilisateur qui nous préoccupaient dans le passé, les changements dans les appels entre applications, les changements dans la logique interne des applications, et le rythme de plus en plus rapide mais le plus fondamental changement - changements dans les données elles-mêmes.
RelationModèle nous dit d'utiliser un tableau bidimensionnel pour décrire le monde de l'information, mais c'est trop "non" naturel. Regardez un livre ou Il. est le plan de décoration de la maison et la répartition des tâches du projet qui va bientôt démarrer. Il semble qu'il ne soit pas approprié de le présenter dans un tableau en deux dimensions, même s'il est réduit dans les moindres détails. « entité-relation », elle sera toujours nécessaire dans un environnement en évolution rapide. Elle implique une série de changements dans « l'interaction données-application-front-end », et affecte souvent l'ensemble du corps.
Il semble que de nombreuses applications de nouvelle génération aient trouvé une solution plus adaptée à la nouvelle tendance - XML, organisant les applications et l'expérience utilisateur d'une manière plus proche de notre propre réflexion. Ainsi, pour les entreprises, le travail relativement basique d’organisation des données peut-il également être effectué en utilisant la pensée XML ? Cela devrait fonctionner.
Faire face aux changements dans les entités de données elles-mêmes
Les entités de données ont toujours été considérées comme la partie la plus stable de l'application, que nous utilisions des modèles de conception ou que nous utilisions divers Les frameworks de développement open source (y compris ces frameworks eux-mêmes) tentent tous de s'adapter aux changements de l'application elle-même. Alors, quelle est la réalité ?
l Les entités de données que nous devons échanger changent souvent en fonction de nos besoins et de ceux de nos partenaires
l Les entités de données qui nous sont fournies par nos partenaires changent souvent ; >l Avec Avec l'introduction des concepts SOA et Enterprise 2.0, les entités de données elles-mêmes sont mélangées à partir de plusieurs sources, et les entités de données elles-mêmes sont également assemblées et combinées à plusieurs reprises
l À mesure que l'entreprise s'affine, nos propres employés Nous espérons toujours obtenir des informations de plus en plus abondantes et détaillées
Ainsi, dans le passé, les entités de données qui étaient considérées comme les plus précoces à être corrigées en fonction des besoins et de la conception deviennent de plus en plus nombreuses ; et plus agile dans le domaine de la technologie et le statu quo commercial nécessite des ajustements constants. Afin de nous adapter à cette exigence, nous pouvons commencer par le haut et ajuster constamment la flexibilité de l'application elle-même. Une autre façon est de traiter ce problème à la « racine » et d'adopter de nouveaux modèles de données capables de s'adapter en permanence à ces changements ; , tels que : le modèle de données XML et les familles technologiques liées à XML.
Par exemple, lors de la définition d'une entité utilisateur, les informations suivantes suffisent dans un premier temps, où IClient est l'
interfaceutilisateur que l'application va utiliser, et CUSTOMER est la représentation en mode base de données relationnelle, est XML :
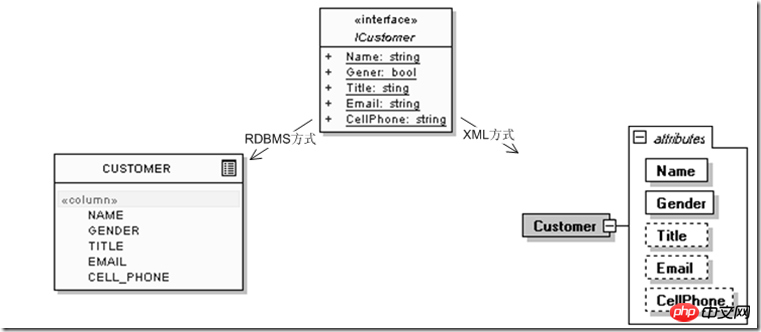 Cependant, nous avons vite découvert qu'il y avait des problèmes avec la conception de cette entité, car nous devons ajouter le numéro de téléphone du bureau et du domicile de l'utilisateur. numéro, et éventuellement 1. 2 emails, son numéro MSN ou Skype etc. Indépendamment des autres problèmes, sur la seule base des exigences de la catégorie 1 du modèle relationnel, le résultat du développement des deux modèles de SGBDR et XML devient :
Cependant, nous avons vite découvert qu'il y avait des problèmes avec la conception de cette entité, car nous devons ajouter le numéro de téléphone du bureau et du domicile de l'utilisateur. numéro, et éventuellement 1. 2 emails, son numéro MSN ou Skype etc. Indépendamment des autres problèmes, sur la seule base des exigences de la catégorie 1 du modèle relationnel, le résultat du développement des deux modèles de SGBDR et XML devient :
Il n'est pas difficile de constater que bien qu'il s'agisse simplement d'un changement dans les "coordonnées" à la fin de l'entité de données "client", il existe une très grande différence d'adaptabilité entre le modèle relationnel et le modèle XML. Le modèle relationnel doit continuellement développer de nouvelles utilisations relationnelles. Pour décrire des entités de données continuellement raffinées, la nature hiérarchique du modèle XML lui-même peut fournir sa propre extension et expansion continue dans des conditions changeantes. Dans les projets réels, des problèmes similaires existent avec des informations telles que le « statut d'éducation » et le « statut d'expérience professionnelle ». Dans le modèle relationnel, même si un client souhaite ajouter la méthode de « détachement » au statut de travail à un certain stade, il trouvera qu'il n'y a pas une telle information dans la conception. Le champ correspondant est réservé, je dois donc le mettre sous forme de chaîne dans le champ "unité de travail", suivi de "(détachement)". au modèle de données rigide lui-même effaçant les données. Les informations incluses dans la sémantique métier ; le modèle hiérarchique peut le décrire comme un nœud enfant ou un attribut , de sorte que non seulement plusieurs relations (clients, statut d'éducation, expérience professionnelle, coordonnées) être incluses dans le modèle relationnel) sont concentrées à l'intérieur d'une entité de données, et les informations étendues de chaque entité elle-même (telles que le « mode de travail » : détachement, échange, concentration à court terme), etc. être décrit à l'intérieur de l'entité de données, et en même temps, l'entité « client » elle-même peut être visualisée à partir d'applications externes. Il s'agit toujours d'une entité, de sorte que l'utilisation d'entités de données plus proches des scénarios commerciaux réels peut s'adapter plus efficacement aux changements externes. .
Ce dont nous avons discuté ci-dessus n'est qu'une seule entité de données. Lorsque nous développons davantage des modèles de domaine commercial spécifiques, nous devons souvent intégrer plusieurs entités de données en même temps pour collaborer pour compléter les fonctions commerciales. Par exemple : la police d'assurance exige que les clients fournissent des informations personnelles sur la santé, les enfants, les parents et les principaux membres de la famille du partenaire en plus des informations ci-dessus. Dans le même temps, les informations de crédit de l'utilisateur seront obtenues auprès d'autres institutions et différentes données. les combinaisons d'entités sont principalement utilisées au sein de l'entreprise. Différents domaines d'application, donc du point de vue de l'utilisation des données, afin de rendre la partie application aussi stable que possible, il est préférable que l'entité de données soit stable, mais uniquement la partie informations de contact. Les informations utilisateur peuvent changer à plusieurs reprises. Si l'application dépend entièrement d'une combinaison de ces facteurs changeants, il est en effet difficile de garantir la stabilité de l'application. La première étape à partir de la source est donc d'essayer de garantir cela. différentes applications s'appuient autant que possible sur une entité spécifique. Cela peut être la première étape vers une amélioration efficace. À ce stade, les avantages des caractéristiques hiérarchiques de XML ressortent, par exemple, nous pouvons librement combiner ces informations en fonction. à différents thèmes d'application :
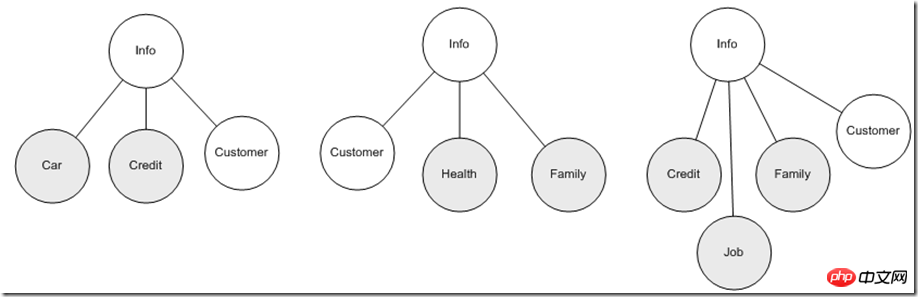
De cette façon, l'application fait face à une entité
Gérer l'intégration des données et du contenu
Les entités de données mentionnées ci-dessus sont davantage abordées dans un contexte centralisé, mais en plus de la conception conceptuelle, il existe également d'autres aspects en cours d'utilisation. Un problème spécifique est de savoir comment les « rassembler », ce qui est généralement réalisé grâce à des ensembles de données.
(Cependant, tout comme le mot « architecture » est galvaudé, « l'intégration de données » est également définie par divers fabricants comme une combinaison de différents concepts basés sur leurs propres caractéristiques de produits, comme BILes fournisseurs s'efforcent de le présenter comme synonyme d'ETLLes fournisseurs qui fournissent des plates-formes d'échange de données le décrivent comme des produits qui implémentent le produit BizTalk FrameworkPour SOA. Pour les entreprises, l'intégration des données consiste davantage à garantir la fourniture de services de données dans le cadre d'une gouvernance efficace. De plus, pour certains fabricants, l'intégration des données comprend également la combinaison sémantique commerciale, etc.)
Mais. en tant qu'utilisateur, l'intégration des données. Sur quels enjeux devons-nous nous concentrer ?
l Cartographie des relations entre les entités de données ;
l Interconnexion des sources de données sous divers protocoles d'échange, normes de données de l'industrie et contraintes de contrôle de sécurité
l Processus d'échange de données
l Vérification et reconstruction des entités de données ;
l Conversion des supports de données et des supports de données
Bien qu'en théorie ce ne soit pas un problème d'effectuer ces tâches avec du codage, Cependant, à mesure que la logique d'intégration d'entreprise devient de plus en plus complexe et change de plus en plus vite, même si vous pouvez modifier le code pour faire face à l'intégration 1:N, s'il s'agit souvent d'une situation M:N, cela sera insuffisant. Existe-t-il un moyen plus simple ? En parlant simplement du niveau logique de la « cartographie » :
l La pensée orientée objet nous dit de nous appuyer sur l'inversion, d'essayer de nous appuyer sur l'abstraction plutôt que sur le concret, comme par exemple de nous appuyer plutôt sur des interfaces que les types d'entités ;
l Le modèle de conception nous indique qu'un adaptateur d'interface incompatible (Adaptateur) est un bon moyen
Existe-t-il donc des technologies similaires dans le domaine des données ? Le schéma XML + XSLT pourrait être une option.
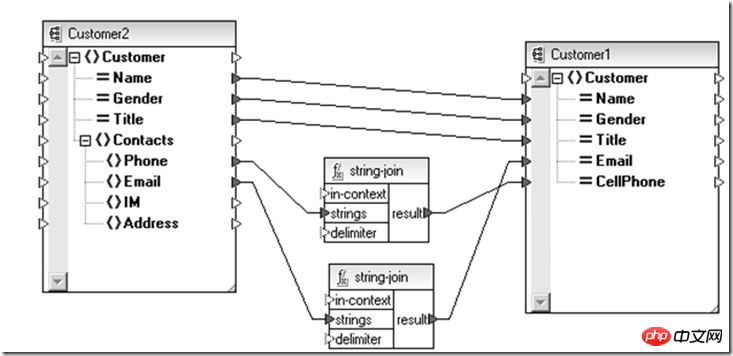
Ce qui précède est une conversion effectuée pour être compatible avec les nouvelles et anciennes entités utilisateur. De même, si vous devez effectuer la partie ci-dessus de l'opération d'agrégation de l'entité de données. pour différents sujets, vous pouvez également l'utiliser. Il est complété au niveau de la définition des données abstraites (Schéma) via XSLT (relation d'adaptation entre schémas).
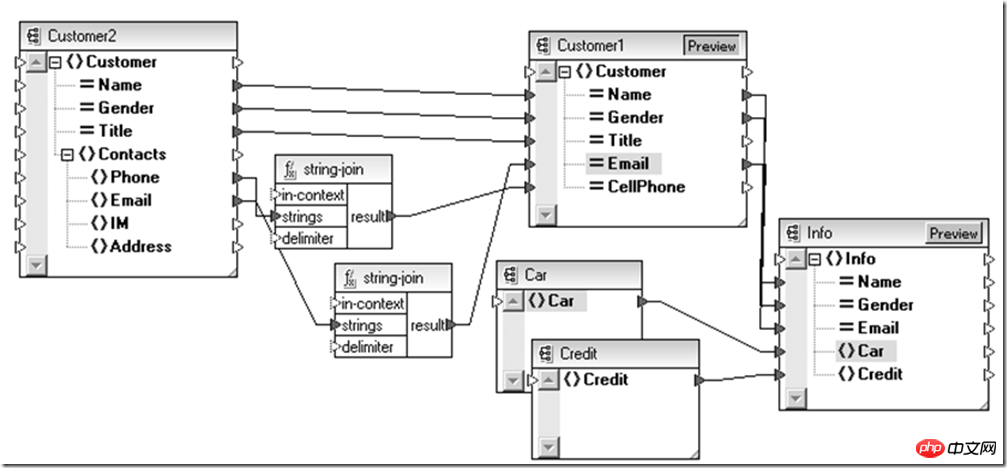
De cette façon, nous pouvons voir comment les données sont agrégées au niveau de l'entité de données, mais il reste encore un problème qui doit être résolu avant : les informations sur le véhicule, le crédit informations et systèmes existants Les informations client sont stockées respectivement dans la base de données relationnelle et dans le service Web du partenaire. Comment connecter ce canal de données ? Désormais, XML reste un bon choix.
Les données sur différents supports de données peuvent être extraites sous leur forme originale, comme le texte brut, la base de données relationnelle, le message EDI ou le message SOAP, et transmises à l'intégration des données via différents points d'agrégation de canaux d'information. , puis convertissez les sources de données hétérogènes via un adaptateur en fonction des besoins de la source de données de destination.
À l'heure actuelle, si un adaptateur point à point est conçu pour chacun des deux types, l'échelle globale se développera selon la tendance du niveau N^2. Pour cette raison, vous pourriez aussi bien les unifier en XML. qui est compatible avec ces informations, puis utilisé. Après que la technologie XSLT introduite ci-dessus ait effectué le mappage entre les entités de données, elle convertit ensuite le XML dans la forme requise par la source de données cible, de sorte que la complexité de l'ensemble du système d'adaptation soit réduite à N niveau.
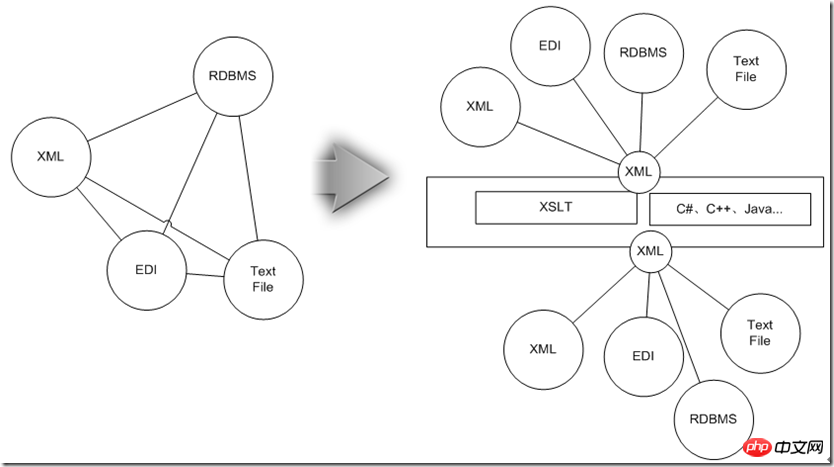
Ensuite, regardons comment la technologie XML répond aux exigences préalables d'intégration de données :
l Cartographie des entités de données, des supports de données et des supports de données Conversion, vérification et reconstruction des entités de données :
Comme ci-dessus, les données sont d'abord uniformément converties en XML, puis traitées en utilisant les avantages hiérarchiques XML et combinées avec la technologie spécifique XML.
l L'interconnexion des sources de données sous divers protocoles d'échange, normes de données industrielles et contraintes de contrôle de sécurité
Les données XML peuvent non seulement traverser les réseaux et les pare-feu, mais peuvent également être facilement utilisées sur le Environnement Internet (mais vous pouvez toujours utiliser la méthode message file d'attente pour les définir comme messages), les données elles-mêmes ne seront pas restreintes par le protocole d'échange en raison d'opérations binaires spéciales. Actuellement, diverses normes industrielles utilisent essentiellement XML pour décrire leur propre DM (Data Modal) industriel. Même si les entités de données de votre système interne lui-même ne sont pas conformes à ces DM en raison de problèmes tels que la conception de la base de données et l'héritage historique, divers protocoles. et les normes de gestion unifiée des données XML peuvent faciliter la conversion. Concernant la sécurité, il semble qu'il n'existe aucune famille de normes de sécurité plus adaptée à l'environnement Internet que les protocoles liés à WS-*. Toutes les normes, sans exception, peuvent utiliser des entités XML pour définir la relation de combinaison entre les données et des mécanismes de sécurité supplémentaires.
l Orchestration du processus d'échange de données ;
Pour les environnements système homogènes ou les plates-formes basées uniquement sur des systèmes middleware compatibles, des mécanismes de workflow existants peuvent être utilisés pour mettre en œuvre l'orchestration. du processus d'échange de données, afin de s'adapter à l'ère orientée services, la norme BPEL plus générale peut être adoptée. À l'heure actuelle, XML n'est pas seulement des données, mais apparaît également comme une forme d'instructions d'exécution par rapport à la technologie Java. , qui a toujours été annoncé comme multiplateforme. En d'autres termes, le processus d'échange défini par XML est encore plus multilingue.
Il semble que l'intégration ait résolu beaucoup de problèmes, mais un problème évident est que nous devrons peut-être effectuer nous-mêmes une partie de la mise en œuvre de tout le travail et indiquer à l'application étape par étape comment le faire. ne considérons plus le Web comme de simples « choses nouvelles », mais si nous le considérons comme un système qui sert notre contenu informationnel et peut interagir, comment pouvons-nous nous présenter ces capacités de services dispersées ? À ce moment-là, les avantages de la définition ouverte des métadonnées XML apparaîtront peut-être réellement.
Faire face à la complexité du réseau sémantique
En plus de divers algorithmes sémantiques, comment agréger divers services dispersés pour nous fournir des services, l'un des facteurs clés de XML est de trouver le colonne vertébrale des indices de données, et clarifier les relations entre les entités sur cette colonne vertébrale et le processus de décomposition et de raffinement progressifs. Les données à ce niveau ne sont pas seulement des objets appelés passivement par l'application, elles fournissent elles-mêmes un support pour d'autres inférences par l'application. Par exemple :
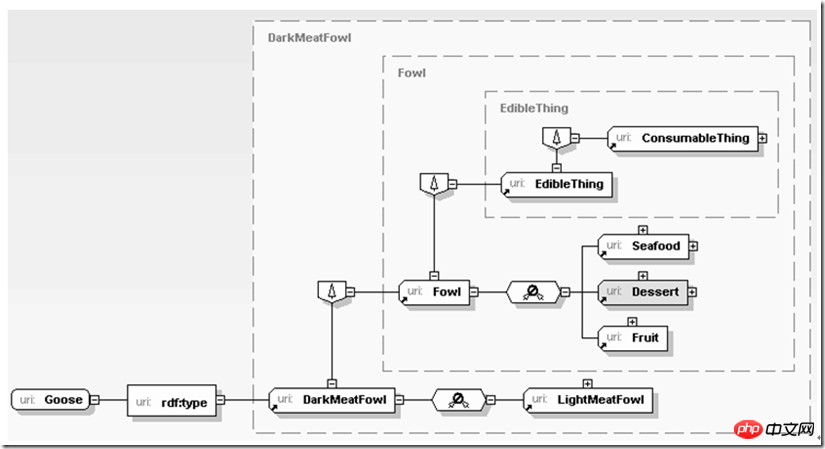
Ici, l'application apprend d'abord que l'objet en cours de traitement est de la viande d'oie. Puisque la viande d'oie est une sorte de viande brune et que la viande brune est une sorte de viande de volaille (volaille), la viande de volaille est comestible, donc l'application peut progressivement en déduire que la viande d'oie est comestible. Le processus d'inférence ci-dessus n'est pas compliqué, mais s'il est implémenté à l'aide d'une base de données relationnelle, il est encore plus difficile à mettre en œuvre s'il est écrit en texte brut. Imaginez si toutes les relations entre la volaille, les légumes, les desserts, et les fruits de mer sont tous exprimés en termes de relations. L'écriture de bases de données ou de textes est vraiment "difficile" à utiliser. XML est différent. Il peut être naturellement proche de nos habitudes de pensée et décrire notre sémantique familière de manière ouverte mais étroitement liée, qu'il s'agisse du processus de préparation du matériel de production dans un environnement ERP d'entreprise ou de la préparation de la cuisine pour une fête d'anniversaire. pour les plans d'achat.
Résumé
Peut-être limités par les contraintes de la grille bidimensionnelle depuis trop longtemps, notre conception et nos idées d'applications sont de plus en plus contraintes par le traitement informatique lui-même, mais à mesure que l'environnement commercial change, le le délai entre l'apparition des besoins métiers et la mise en œuvre et le lancement des applications est de plus en plus court. Il nous faut à l'heure actuelle sortir notre réflexion de l'informatique, il semble préférable d'adopter une technologie de données plus ouverte et plus proche. nos pensées divergentes. Pour les organisations, une fois les données implémentées, nous pouvons continuer à utiliser diverses technologies matures pour les compléter, mais à un niveau commercial plus proche et plus proche de cet environnement plus volatile, XML semble être flexible et puissant.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!