
Maison >base de données >tutoriel mysql >Explication détaillée des index MySQL
Explication détaillée des index MySQL

- 迷茫original
- 2017-03-26 13:16:281628parcourir
L'index de MySQL se fait via B+tree. B+tree est une variante de l’arbre binaire équilibré, la vitesse de requête est donc très rapide.
Les indices sont principalement divisés en index clusterisés et index auxiliaires :
Index clusterisé : Les données dans MySQL sont stockées via l'index clusterisé de la clé primaire, et qu'est-ce que stocké dans le nœud feuille sont les données de chaque ligne, nous interrogeons donc via la clé primaire
La raison pour laquelle c'est aussi rapide qu'avant est que la clé primaire est un index clusterisé, et en utilisation réelle, un seul Un tel arbre B+ sera construit, cela peut donc expliquer pourquoi la clé primaire est la seule.
Citation de l'image sur Internet :
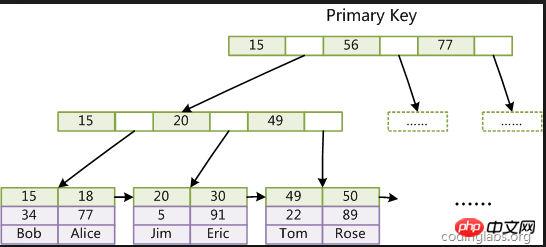
La recherche à chaque couche est une opération IO, et généralement le nombre de couches B+tree est de 2 -4. Donc, dans le pire des cas, seules 4 opérations d'E/S sont nécessaires.
Index auxiliaire : La différence entre l'index auxiliaire et l'index clusterisé est que toutes les données ne sont pas stockées dans des nœuds feuilles, mais l'emplacement des données est stocké. Cela équivaut à utiliser l'index auxiliaire
pour trouver les données, et nous devons ensuite trouver des informations détaillées via l'arborescence d'index clusterisé.
Citation du diagramme sur Internet :
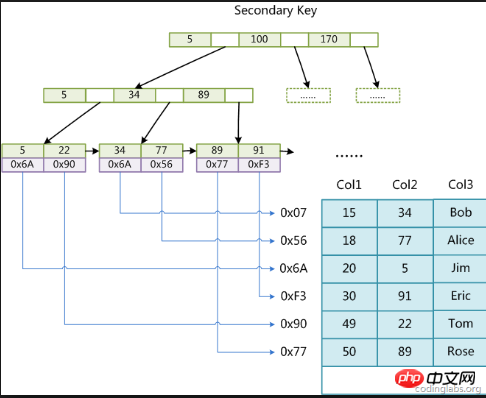
Ce diagramme est un diagramme logique, mais la couche inférieure pointe vers l'index clusterisé à travers les nœuds feuilles, c'est-à-dire que vous devez ensuite passer par la logique
du premier type de diagramme.
Donc, le résultat final est que plusieurs arbres d'index auxiliaires pointent vers un arbre d'index groupé
(Le dessin est vraiment moche)
À propos de quand créer un index
Parce qu'il s'agit d'un arbre, il est récupéré par recherche binaire, il est donc applicable comme condition derrière où, et ceci Le les valeurs sont dans une large plage, adaptées à la création d'index. Il ne convient pas à ceux qui ont une petite plage (énumérations is_delete, sex, etc.).
Pour des situations spécifiques, on peut analyser par show index :
show index from company_related_person
Résultat :

Puis calculer par cardinalité
select 105/(select count(*) from company_related_person) from DUAL
Le résultat obtenu ici est de 0,913 (cette valeur est liée à la capacité de stockage, il est préférable d'avoir une certaine quantité de données). Plus cette valeur est proche de 1, plus l'efficacité de l'index sera élevée. Si la valeur calculée est très petite, il est recommandé de ne pas créer d'index
Nous pouvons également visualiser l'utilisation de l'index via expliquer
EXPLAIN select * from company_related_person where company_id='2'
Sortie

clé représentée Est la colonne d'index actuellement utilisée. Le dernier extra représente la méthode utilisée. Ici, Using index représente l'utilisation d'un index. Si Using filesort représente une lecture directe à partir du disque
Pour les instructions SQL complexes avec des requêtes lentes, vous pouvez utiliser cette méthode pour analyser. .
L'objectif de l'optimisation des performances SQL : atteindre au moins le niveau de plage, l'exigence est le niveau de référence, si cela peut être consts, c'est mieux.
1) Consts Il y a au plus une ligne correspondante (clé primaire ou index unique) dans une seule table, et les données peuvent être lues pendant la phase d'optimisation.
2) ref fait référence à l'utilisation d'un index normal.
3) range effectue la récupération de plage sur l'index
4) index signifie lire directement à partir du disque
D'après la figure ci-dessus, nous pouvons également voir que nous utilisons la réf
À propos de la différence entre index et clé :
Lorsque nous créons un index, nous nous posons souvent cette question, quelle est la différence entre index et clé ? . La clé est une valeur de clé qui fait partie de la théorie des modèles relationnels, telle que la clé primaire (Primary Key), la clé étrangère (Foreign Key), etc., qui sont utilisées pour la vérification de l'intégrité des données et les contraintes d'unicité. L'index est au niveau de l'implémentation. Par exemple, vous pouvez indexer n'importe quelle colonne d'une table. Ensuite, lorsque la colonne indexée est dans la condition Where dans l'instruction SQL, vous pouvez obtenir un emplacement rapide des données et donc une récupération rapide. Quant à l'index unique, il ne s'agit que d'un type d'index. La création d'un index unique signifie que les données de cette colonne ne peuvent pas être répétées
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!