
Maison >base de données >tutoriel mysql >Introduction détaillée aux connaissances de base de MySQL (photo)
Introduction détaillée aux connaissances de base de MySQL (photo)

- 黄舟original
- 2017-03-17 14:18:101229parcourir
Cet article présente principalement quelques connaissances très basiques sur mysql. A une très bonne valeur de référence. Jetons un coup d'œil avec l'éditeur ci-dessous
Cet article présente principalement quelques connaissances très basiques sur MySQL pour préparer l'optimisation SQL ultérieure.
1 : Connectez-vous à mysql
À propos du téléchargement et de l'installation de mysqlJe n'entrerai pas dans les détails ici La première étape consiste à. connectez notre serveur mysql, ouvrez la commande cmd et basculez vers le répertoire bin où vous avez installé le serveur MySQL, puis entrez mysql -h localhost -u root -p
où -h représente votre adresse d'hôte (cette machine est localhost , rappelez-vous N'incluez pas le numéro de port) -u signifie se connecter à la base de données nom -p signifie le mot de passe de connexion. L'image suivante apparaît, ce qui signifie que la connexion est réussie

2 : Instructions SQL couramment utilisées
2.1 : Créer une base de données Créer une base de données nom de la base de données
2.2 : supprimer le nom de la base de données de suppression de la base de données
2.3 : interroger la base de données dans le système afficher les bases de données
2.4 : utiliser la base de données utiliser le nom de la base de données
2.5 : Requête des tables de base de données pour afficher les tables
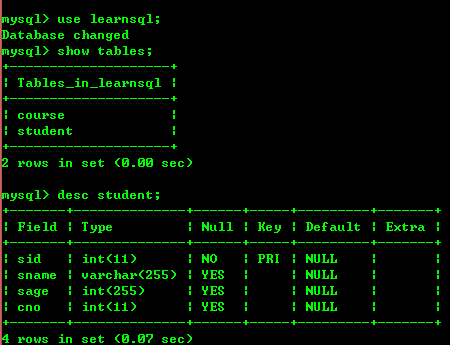
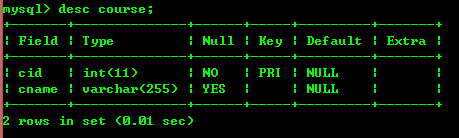
2.6 : Requête de la structure de la table desc nom de la table
2.7 : Interrogation de l'instruction SQL pour créer une table Afficher créer une table Nom de la table
2.8 : Supprimer la table, supprimer le nom de la table
2.9 : Supprimer plusieurs enregistrements de table à la fois : supprimer t1, t2 de t1, t2 [condition où] Si un alias est utilisé après from, alors un alias doit être utilisé après delete
3.0 : Mise à jour unique de plusieurs tables, mise à jour t1, t2 ...tn set t1.field=expr1,tn.exprn=exprn;
3 : Requête
3.1 : sélectionnez Requête normale
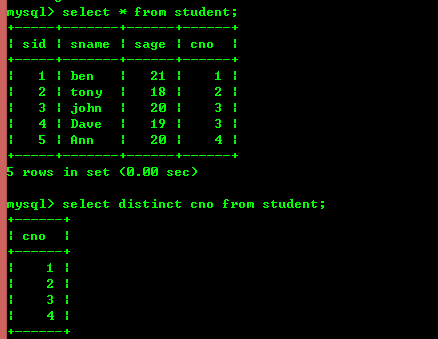
Ici j'ai créé une donnée et mis 2 tableaux, voir l'image ci-dessous
3.2 : Interroger les enregistrements non dupliqués
Utilisez le mot-clé distinct comme indiqué ci-dessous
3.3 : Tri et restrictions
Utilisez le mot-clé order by pour trier desc par ordre décroissant asc croissant, le mot-clé limit limite la sortie
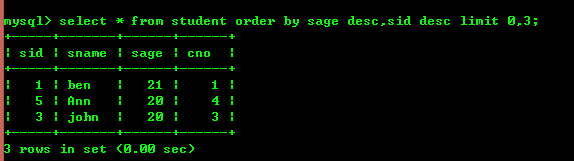
order by suivi de champs (order by doit seulement être écrit une fois pour trier le premier champ en premier, puis le second, et ainsi de suite), le premier nombre après la limite est simplement, le second est le nombre de sorties).
Quatre : AgrégationOpération
Dans de nombreux cas, les utilisateurs doivent établir certaines statistiques, comme compter le nombre de personnes dans l'ensemble de l'entreprise ou le nombre de départements, qui sera utilisé à ce moment-là Opérations d'agrégation. La syntaxe de l'opération d'agrégation entre en jeu
select [field1, field2...fieldn] fun_name from table name
where condition
group by field1, field2...fieldn
avec rollup
ayant une condition
fun_name est appelé une fonction d'agrégation ou une opération d'agrégation. Les plus courantes incluent la somme (somme), le nombre (*) d'enregistrements, max (. valeur maximale) , min (valeur minimale).
grouper par indique les champs à classer et agréger. Par exemple, le nombre d'employés comptés selon la classification du département. Le département doit être écrit après grouper par. syntaxe, indiquant s'il faut agréger les catégories. La combinaison finale est résumée
ayant signifie que les résultats classés sont à nouveau filtrés
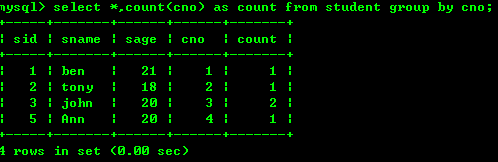
4.1 : Compter le nombre de personnes dans la classe en fonction du numéro de cours.
 4.2 : Comptez le nombre de personnes par niveau et comptez le nombre total de personnes
4.2 : Comptez le nombre de personnes par niveau et comptez le nombre total de personnes
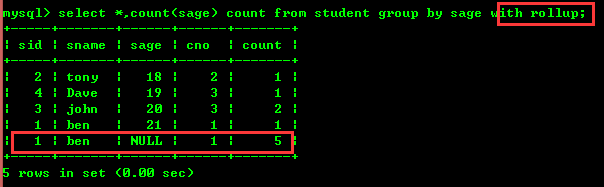 Le rollup consiste à résumer le nombre de personnes, comme le montre la photo.
Le rollup consiste à résumer le nombre de personnes, comme le montre la photo.
4.3 : Comptez le nombre de personnes âgées d'au moins 20 ans. Lors de l'agrégation, les enregistrements sont filtrés. Si la logique le permet, utilisez d'abord où filtrer les enregistrements. Cela réduira l'ensemble des résultats et améliorera considérablement l'efficacité. d'agrégation, puis filtrer en fonction de l'avoir.
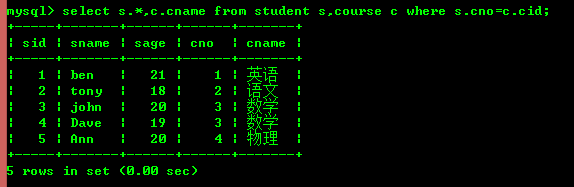
5 : Connexion de table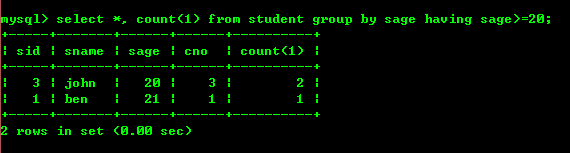
jointures internes
et jointures externes. La principale différence entre elles est que les jointures internes filtrent uniquement les enregistrements correspondants de deux tables, tandis que les jointures externes filtreront les autres enregistrements sans correspondance. on utilise souvent la connexion interne.5.1 : Interroger les cours sélectionnés par les étudiants
Les jointures externes sont divisées en jointures gauches et jointures droites.
Jointure gauche (contient tous les enregistrements de la table de gauche même s'il n'y a aucun enregistrement correspondant dans la table de droite)
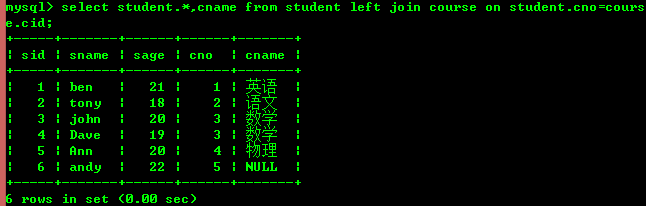
Jointure droite (contient all L'enregistrement dans la table de droite n'a même pas d'enregistrement correspondant dans la table de gauche)
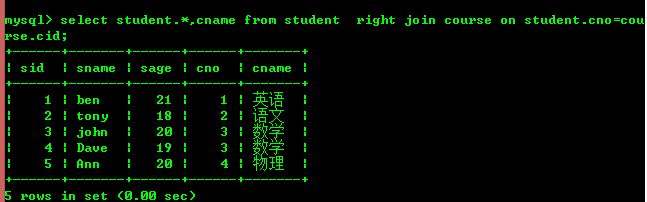
On peut voir que la jointure de gauche est basée sur la table de gauche, et la jointure de droite est basée sur la table de droite. La table est la principale.
Six : Sous-requête
Dans certains cas, lors de l'exécution d'une requête, la condition requise est le résultat d'une autre instruction select. Dans ce cas, la sous-requête est utilisée Query, les mots-clés utilisés pour les sous-requêtes incluent principalement in, not in, =, !=, exist, not exist, etc.
Par exemple, utilisez in pour interroger
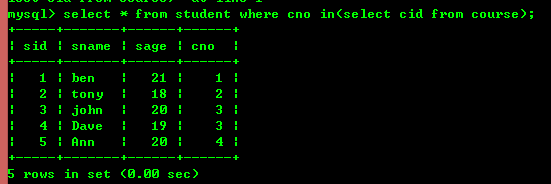
Mais l'utilisation de jointures internes peut également obtenir les effets ci-dessus
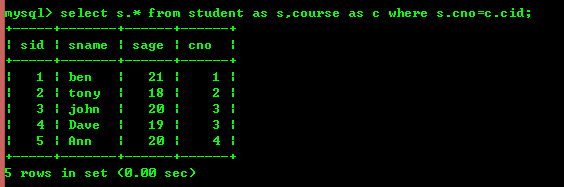
Mais l'efficacité des jointures internes est supérieure à celle des sous-requêtes dans de nombreux cas, donc si cela n'affecte pas le Logique métier En principe, l'inline est prioritaire.
Seven : Union
Interrogez les données de deux tables selon certaines règles, et fusionnez les résultats pour les afficher ensemble. À ce stade, nous pouvons utiliser union ou union all. La syntaxe spécifique est la suivante
select * from t1 unionunion all select * from t2 unionunion all select * from tn;
La différence entre union et union all est que l'union supprime les enregistrements en double du ensemble de résultats filtrés.
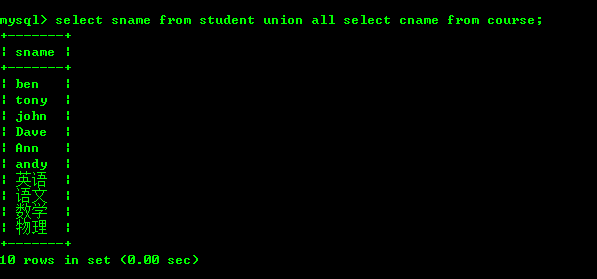
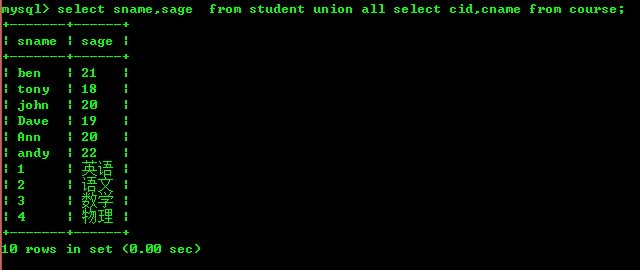
N'oubliez pas que vous ne pouvez pas joindre deux tables si elles ne correspondent pas, comme suit

Si nous interrogeons chaque table 2 champs
8 : Fonctions communes
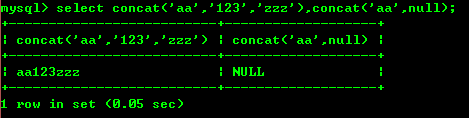
8.1 : concat
fonction cancat : passer in Les paramètres sont concaténé en une chaîne Le résultat de la concaténation d'une chaîne et de null est nul, comme indiqué ci-dessous
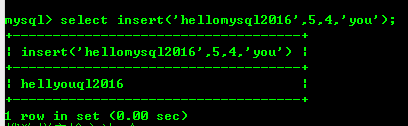
8.2 : L'insertion. La fonction (str,x,y,instr) remplace la chaîne str à partir de Remplacer par vous
8.3 : Lower(Str) et Upper(Str) convertissent les chaînes en minuscules ou en majuscule.
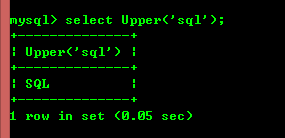
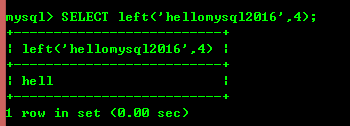
8.4 : left(str,x) et right(str,x) renvoient respectivement les x caractères les plus à gauche et les x caractères les plus à droite de la chaîne, si les deux paramètres sont null et aucun caractère n'est renvoyé
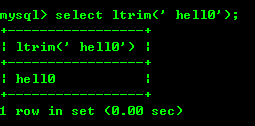
8.5 : ltrim(str) et rtrim(str) suppriment les caractères à gauche ou à droite de la chaîne
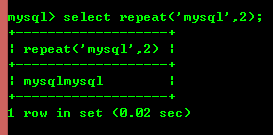
8.6 : répéter(str,x) : renvoie le résultat de str répété x fois
8.7 : replace(str, a, b ) Remplacez toutes les occurrences de la chaîne a dans la chaîne str par la chaîne b.
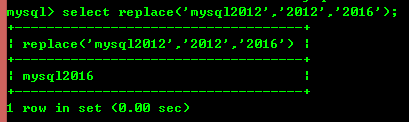
8.8 : trim(str) supprime les espaces de début et de fin
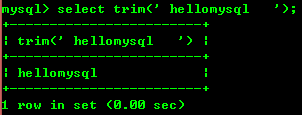
8.9 : substring(str,x, y ) : Renvoie une chaîne de y longueurs de chaîne à partir de la x-ième position dans la chaîne str.
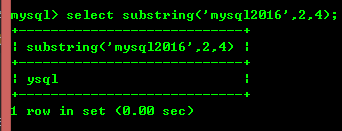
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!