
Maison >base de données >tutoriel mysql >Explication détaillée MySQL haute performance de la création d'index hautes performances (image et texte)
Explication détaillée MySQL haute performance de la création d'index hautes performances (image et texte)

- 黄舟original
- 2017-03-15 17:20:241849parcourir
Cet article concerne la création d'un index :
(1) Type d'indice
(2) Avantages de l'index
(3) Stratégies d'optimisation des index
Voici une carte mentale de l'indexation : 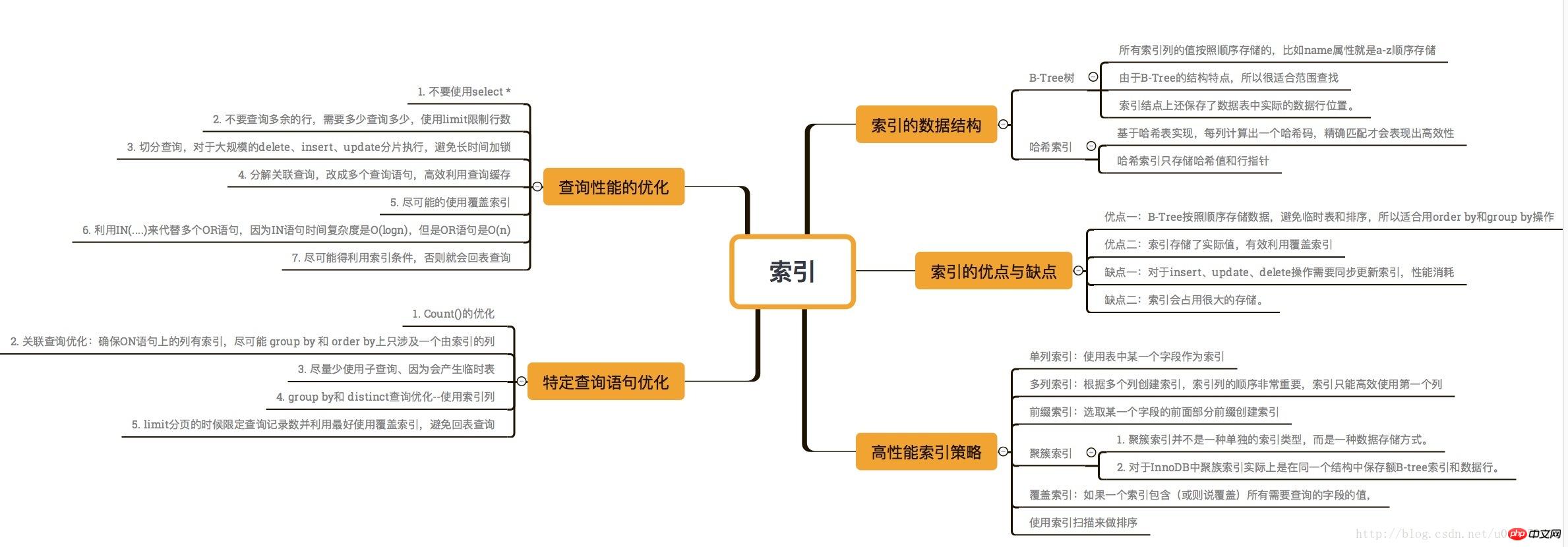
L'index est une méthode utilisée par les moteurs de stockage pour trouver rapidement la structure des données des enregistrements . Les index constituent le moyen le plus efficace d'optimiser les performances des requêtes. Les index peuvent facilement améliorer les performances des requêtes de plusieurs ordres de grandeur. Indexation Nous ajoutons généralement un index à une certaine colonne.
Le moteur de stockage trouve d'abord la valeur correspondante dans l'index, puis trouve la ligne de données correspondante en fonction du rowid sur l'enregistrement d'index correspondant. Par exemple, exécutez l'instruction de requête suivante :
SELECT first_name from actor where actor_id=5;
S'il existe un index sur la colonne Actor_id, MySQL utilisera l'index pour trouver la ligne correspondant à Actor_id 5. C'est-à-dire pour dire, MySQL recherche d'abord par valeur sur un index et renvoie toutes les lignes contenant cette valeur.
L'index peut contenir les valeurs d'une ou plusieurs colonnes. Si l'index contient plusieurs colonnes, l'ordre des colonnes est également très important, car MySQL ne peut utiliser efficacement que la colonne de préfixe la plus à gauche. de l'indice. Il existe une grande différence entre créer un index contenant deux colonnes et créer deux index contenant une colonne.
1. Types de structures de données d'index :
Les index les plus courants sont les index B-Tree et les index de hachage.
(1) Index d'arbre B-Tree
Généralement, les index font référence aux index B-Tree, qui utilisent la structure de données B-Tree pour stocker des données. En fait, il est implémenté sur la base de B Tree. Chaque nœud feuille contient un pointeur vers le nœud feuille suivant.
B-Tree signifie que toutes les valeurs sont stockées dans l'ordre. Par exemple, pour l'attribut name , elles sont stockées dans l'ordre de a à z. Après avoir utilisé l'index B-Tree, le moteur de stockage n'a plus besoin d'effectuer une analyse complète de la table pour obtenir les données requises. Au lieu de cela, il recherche à partir du nœud racine de l'index. Le résultat final est que soit la valeur correspondante est trouvée, soit. le dossier n'existe pas. Cela permet un accès plus rapide aux données.
B-Tree organise et stocke les colonnes d'index de manière séquentielle, il est donc très approprié pour rechercher des données de plage. (Par exemple, la recherche de noms commençant par I-k sera très efficace)
Index B-Tree type de requête approprié
(1) Correspondance de valeur complète : et dans le index Toutes les colonnes correspondent.
(2) Faire correspondre le préfixe le plus à gauche : Pour un index contenant plusieurs colonnes, seule la première colonne de l'index est utilisée.
(3) Faire correspondre le préfixe de la colonne : faire correspondre le début de la valeur d'une certaine colonne. (Par exemple, lors de la mise en correspondance du champ de nom, seuls les noms commençant par J sont mis en correspondance.) Seule la première colonne de l'index est utilisée ici.
(4) Valeur de plage correspondante : correspond aux enregistrements dont les champs se situent dans une certaine plage. Seule la première colonne de l'index est utilisée ici.
(5) Faire correspondre exactement une certaine colonne et une certaine plage correspondre à une autre colonne : dans le cas où un index contient plusieurs champs, par exemple, faire correspondre exactement la première colonne et faire correspondre la plage de la deuxième colonne.
(6) Requête qui accède uniquement à l'index : elle accède aux lignes de l'index sans accéder aux lignes de données des autres champs de l'enregistrement.
La correspondance de plage ci-dessus est principalement due au fait que l'index stocke les colonnes d'index dans l'ordre, ce qui conduit à une grande efficacité de correspondance de plage.
Il existe également certaines restrictions sur les index B-Tree :
(1) L'index ne peut effectuer une recherche qu'à partir de la colonne la plus à gauche
(2) S'il existe une recherche par plage d'un certain colonne dans la requête, toutes les colonnes à sa droite ne peuvent pas utiliser l'optimisation d'index.
Au vu des deux restrictions ci-dessus, vous devriez pouvoir comprendre que lorsque l'index contient plusieurs colonnes, l'ordre des colonnes de l'index est très important.
(2) Index de hachage
L'index de hachage est implémenté sur la base de la table de hachage Seules les requêtes qui correspondent exactement à toutes les colonnes de l'index sont valides. Pour chaque ligne de données, le moteur de stockage de données calcule un code de hachage pour toutes les colonnes d'index. Le code de hachage est une valeur plus petite et les codes de hachage calculés pour les lignes avec des valeurs de clé différentes sont différents.
1) L'index de hachage stocke uniquement les valeurs de hachage et les pointeurs de ligne, et ne stocke pas les valeurs de champ spécifiques, il doit donc y avoir un processus de lecture des lignes.
2) L'index de hachage n'est pas stocké dans l'ordre de la valeur de l'index, il ne peut donc pas être utilisé pour le tri.
3) L'index de hachage ne prend en charge que les requêtes de comparaison d'égalité et ne prend pas en charge les requêtes de comparaison de plages. Ceci est lié aux caractéristiques de la table de hachage.
4) Les index de hachage ont le problème des conflits de hachage. Pour les données de conflit de hachage, tous les pointeurs de ligne de la liste chaînée doivent être parcourus.
En raison des limitations ci-dessus, les index de hachage ne conviennent qu'à des occasions spécifiques, mais une fois qu'ils seront adaptés aux index de hachage, les performances seront particulièrement élevées.
Lorsque vous utilisez un index de hachage, vous devez généralement ajouter la valeur avant le hachage dans les conditions de requête, telles que :
mysql>select * from words where crc=crc32(‘gnu’) and word=’gnu’;
这里crc字段就是word字段哈希之后的值,因为hash之后可能存在冲突,带上原本的值做上二次比较,就可以精确定位。
2.索引的优点:
索引可以让服务器快速定位到表的指定位置。但是这不是唯一的作用,比如:
(1)对于B-Tree索引,由于B-Tree是按照顺序存储数据的,所以用来做order by 操作或则是 group by操作的效率很高。
(2)因为索引中存储了实际的列值,所以某些查询只需要索引就可以完成全部查询。
总结来说就是3点:
(1)索引大大减少服务器需要扫描的数据量;
(2)索引可以帮助服务器避免排序和临时表;
(3)索引可以将随机IO变为排序IO。
3.高性能的索引策略
先概括一下索引的策略:
1)单列索引
2)多列索引
3)前缀索引
4)聚簇索引
5)覆盖索引
单列索引
所谓单列索引是指:使用数据表字段中的某一列作为索引。但是索引列不能是表达式的一部分,也不能是函数的参数。
比如对于下面的一个例子:
select actor_id from actor where actor_id+1=5;
对于这样的一个SQL,where语句后面 是一个表达式,其实很明显是actor_id=4的条件,但是MySQL却无法解析,索引无法正却使用索引。
还有一种是函数参数:也是无法正常的使用索引的
select ... where TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col)<=10;
多列索引以及选择合适的索引顺序
注意这里要区分:为每个列创建独立的索引和为多个列创建一个索引的区别。
比如下面这种情况:
CREATE TABLE t{
c1 int,
c2 int,
c3 int,key(c1),key(c2),key(c3)
}这一种就是为表中的3个列都创建了索引。
但是多个列创建索引就是:创建了一个索引,包含customer_id,和staff_id
alter table payment add KEY(customer_id, staff_id);
上面这个索引其实是包含了两个索引,一个是customer_id这个索引,还有一个是(customer_id,staff_id)。注意staff_id并不能作为单独的索引使用。
对于多列索引,最重要的就是怎么选择索引列的顺序,其实这一点与实际的查询需求有关。主要是为了满足排序和分组。
先从数据结构层次来分析,我们知道索引是以B-Tree的形式存储的,在一个多列索引列中,索引的顺序意味着索引首先按照最左列进行排序,其次是第二列。所以对于一个多列索引,如果以第二列或则第三列直接作为索引,基本是没有用到索引。由于索引的有序性很好的满足了order by、group by和distinct等子句的查询需求。
从上面的分析我们就能认识到多列索引中列的顺序是多么重要。关于多列索引中有一点经验法则:
(1)在不需要考虑排序和分组时,通常情况下将选择性最高的列放在索引最前列。(这时候索引只需要优化where查询条件,能够很快过滤出需要的行)
索引列的选择性定义:不重复的索引值和数据表的记录总数的比值。索引的选择性越高也就是查询效率越高。比如对于人员信息表,phone这一字段的选择性是很高的,几乎为1,但是对于sex性别这一字段的选择性是非常低的,因为只有两个选择男或则是女,几乎为0。
(2)实际情况下也与数据的分布有很大关系。
以下面的查询为例:
SELECT * FROM item WHERE staff_id=2 AND customer_id=584;
这时候应该创建(staff_id, customer_id)的索引还是应该创建(customer_id,staff_id)的索引呢?这时候就应该确认一下那个字段的选择性更高,先查询一下staff_id和customer_id的总数,哪个小就将哪个放在前面。
前缀索引
前缀索引:有时候需要索引的列可能会很长,这时候会导致索引大而且很慢,我们可以只索引列开始的部分(也就是只索引某一列的前面几个字符),这样可以大大节省索引空间也能加快索引的速度,但是也会降低索引的选择性(也就是索引查出来的结果会变多)。
使用的技巧在于:选择足够长的前缀保证较高的选择性,同时又不能太长,避免占用太多的存储空间。
Index clusterisé
L'index clusterisé n'est pas un type d'index distinct, mais une méthode de stockage de données. Ici, nous utilisons principalement InnoDB comme exemple pour illustrer l'index clusterisé.
L'index clusterisé dans InnoDB stocke en fait l'index B-tree et les lignes de données dans la même structure. Lorsqu'il existe un index clusterisé dans une table, ses lignes de données sont en fait stockées dans les pages feuilles de l'index. La signification du clustering est en fait que les lignes de données et les valeurs clés du B-Tree adjacent sont stockées ensemble de manière compacte. Les lignes de données ne peuvent être stockées qu'à un seul endroit, il ne peut donc y avoir qu'un seul index clusterisé.
Ce qui suit est un exemple de diagramme pour illustrer : la colonne d'index est une valeur entière, la page feuille contient toutes les données de la ligne, mais la page nœud ne contient que la colonne d'index (la valeur entière dans la figure ci-dessous).
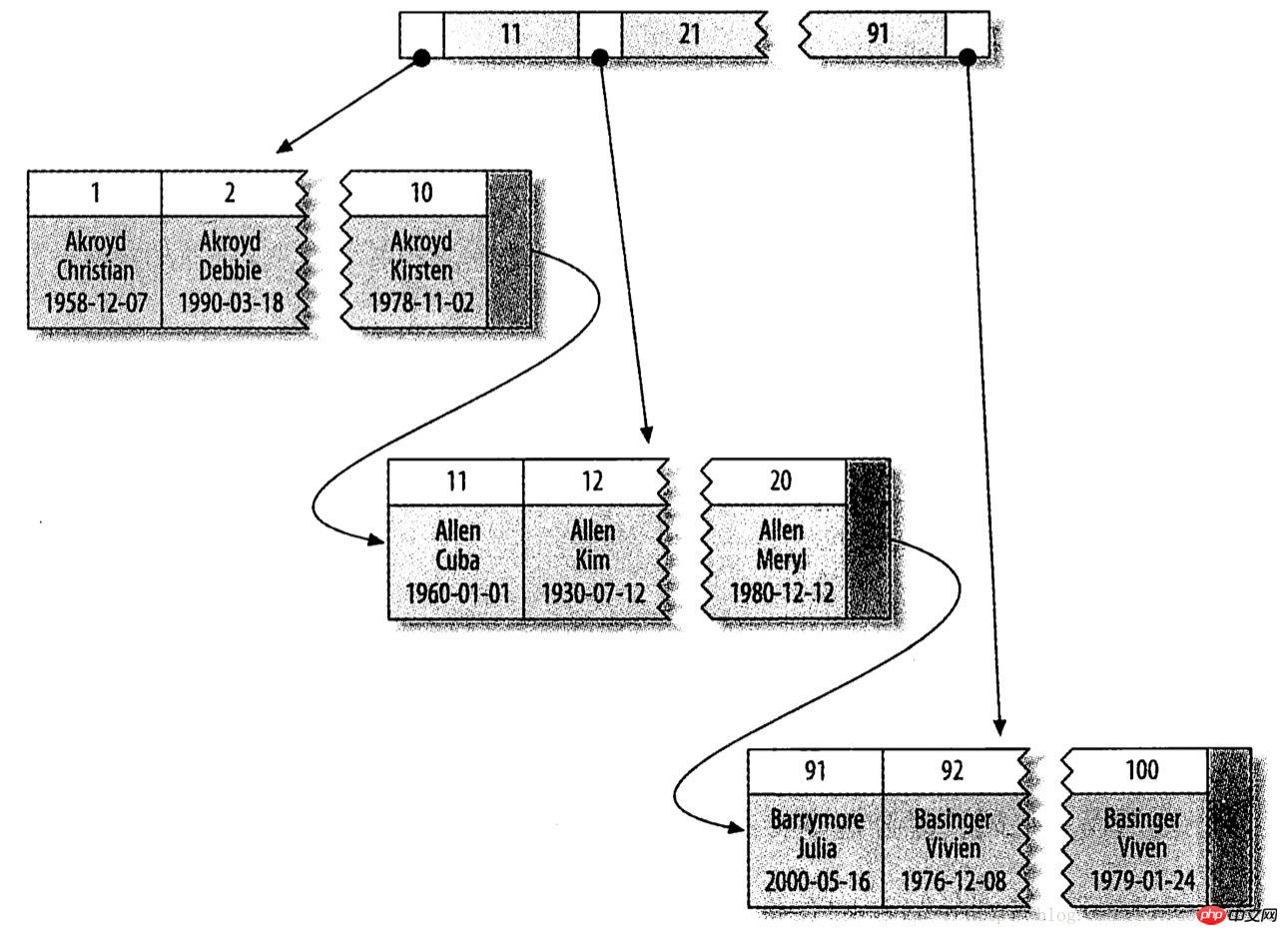
Dans la version actuelle de MySQL, l'index clusterisé d'InnoDB ne prend en charge que l'utilisation de clés primaires pour regrouper les données. Si aucune clé primaire n'est définie, InnoDB choisira à la place un index unique non vide.
Avantages des données groupées :
(1) Les données associées peuvent être enregistrées ensemble. Par exemple, lors de l'interrogation d'adresses e-mail, l'ID utilisateur est utilisé comme clé primaire et les données sont regroupées par ID utilisateur. De cette manière, tous les e-mails d'un utilisateur peuvent être obtenus en lisant uniquement un petit nombre de pages de données. disque.
(2) L'accès aux données est plus rapide. Un index clusterisé stocke l'index et les données dans un B-Tree, donc la récupération des données d'un index clusterisé est généralement plus rapide que la recherche du même index. (Bien sûr, il existe des cas où la colonne de recherche est la colonne d'index)
(3) Les requêtes utilisant des analyses d'index de couverture peuvent utiliser directement la clé primaire dans le nœud de la page.
Les avantages ci-dessus peuvent améliorer considérablement les performances lors de l'interrogation et de la conception de tables, mais il existe également quelques inconvénients :
(1) Les données clusterisées améliorent considérablement les performances des applications gourmandes en E/S, mais toutes les données si elles sont placées dans mémoire, l’ordre d’accès n’a pas d’importance et l’index clusterisé perd son avantage.
(2) La vitesse d'insertion dépend fortement de l'ordre d'insertion.
(3) La mise à jour des colonnes d'index clusterisés est très coûteuse et forcera chaque ligne mise à jour d'InnoDB à être déplacée vers un nouvel emplacement.
Indice de couverture
Si un index contient (ou couvre) les valeurs de tous les champs qui doivent être interrogés, nous l'appelons un index de couverture indice.
La couverture de l'index est un outil très utile pour les index, il vous suffit de scanner l'index pour obtenir toutes les données dans les nœuds feuilles de l'index, sans avoir besoin de renvoyer une requête à la table, ce qui est très efficace. Améliore considérablement les performances. Les avantages sont également nombreux :
(1) Les entrées d'index sont généralement beaucoup plus petites que la taille de la ligne de données. Si vous n'avez besoin que de lire l'index, MySQL réduira considérablement la quantité d'accès aux données, ce qui réduira considérablement la quantité d'accès aux données. imposer une lourde charge sur le cache. Très important.
(2) Étant donné que l'index est stocké dans l'ordre des valeurs des colonnes, les recherches de plage gourmandes en E/S nécessiteront beaucoup moins d'E/S que la lecture aléatoire de chaque ligne de données à partir du disque,
Utiliser analyse d'index pour le tri
MySQL a deux façons de générer des résultats ordonnés :
(1) Par opération de tri
( 2) Analyse dans l'ordre d'indexation ; >Si la valeur de type expliquée est index, cela signifie que MySQL utilise l'analyse d'index pour le tri.
4. Inconvénients de l'index
(1) Pour les opérations d'insertion, de mise à jour et de suppression, l'index doit être mis à jour de manière synchrone, ce qui entraîne une vitesse lente. (2) Les index prendront beaucoup de stockage.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!