
Maison >Java >javaDidacticiel >Exemples de code détaillés d'itérateurs Java
Exemples de code détaillés d'itérateurs Java

- 黄舟original
- 2017-03-14 11:58:463848parcourir
1. Résumé
Le modèle d'itérateur est en symbiose avec les collections. D'une manière générale, tant que nous implémentons un conteneur, nous devons fournir l'itérateur du conteneur. L'avantage de l'utilisation d'itérateurs est qu'ils encapsulent les détails d'implémentation internes du conteneur, fournissent une méthode de parcours unifiée pour différentes collections et simplifient l'accès client et l'acquisition de données dans le conteneur. Sur cette base, nous pouvons utiliser Iterator pour compléter le parcours de la collection. De plus, la syntaxe for loop et foreach peut également être utilisée pour parcourir la collection. classe de collecte. ListIterator est un itérateur bidirectionnel unique à la famille de conteneurs List. Les principaux points de cet article incluent :
Modèle d'itérateur
Itérateur Itérateur et itérable Interface
Parcours de boucle : similitudes et différences entre foreach, Iterator et for
Brève description de ListIterator (explication détaillée de la liste de conteneurs)
2. Modèle d'itérateur
Le modèle d'itérateur est en symbiose avec les collections. De manière générale, tant que nous implémentons un conteneur, nous devons également fournir l'itérateur du conteneur, tout comme Collection (List, Set, etc.) dans ces conteneurs Java. ont leur propre itérateur. Si nous voulons implémenter un nouveau conteneur, nous devons bien sûr également introduire le modèle d'itérateur et implémenter un itérateur pour notre conteneur. Les avantages de l'utilisation d'itérateurs sont : encapsule les détails d'implémentation internes du conteneur. Il peut fournir une méthode de parcours unifiée pour différentes collections, simplifiant l'accès client et l'obtention de données dans le conteneur.
Cependant, comme les conteneurs et les itérateurs sont si étroitement liés, la plupart des langages fournissent également les itérateurs correspondants lors de l'implémentation des conteneurs, et dans la plupart des cas, les conteneurs et itérateurs fournis par ces langages peut répondre à nos besoins. Par conséquent, en réalité, il est relativement rare que nous ayons besoin d'implémenter nous-mêmes le modèle d'itérateur. Nous n'avons souvent besoin que d'utiliser des conteneurs et des itérateurs existants dans le langage.
1. Définition et structure
-
Définition
Mode Itérateur (Itérateur), également appelé curseur (Curseur ). La définition donnée par GOF est la suivante : fournit une méthode pour accéder à chaque élément d'un conteneur (conteneur) objet sans exposer les détails internes de l'objet conteneur.
D'après la définition, le modèle d'itérateur est né pour les conteneurs. Nous savons que l'accès aux objets conteneurs doit impliquer des algorithmes de traversée. Vous pouvez simplement brancher les méthodes de traversée dans l'objet conteneur, ou vous ne pouvez fournir aucun algorithme de traversée et laisser les personnes qui utilisent le conteneur l'implémenter elles-mêmes. Les deux cas semblent résoudre le problème. Cependant, dans le premier cas, le conteneur porte trop de fonctions. Il est non seulement responsable de la maintenance des éléments au sein de son propre « conteneur » (ajout, suppression, modification, vérification, etc.), mais fournit également une interface de parcours. lui-même ; et enfin L'important est que en raison du problème de sauvegarde du statut de traversée , plusieurs traversées ne peuvent pas être effectuées sur le même objet conteneur en même temps, et le reset doit être ajoutée . La deuxième méthode évite les problèmes, mais expose les détails internes du conteneur.
-
Composition des personnages en mode itérateur
Rôle d'itérateur (Itérateur) : Le rôle d'itérateur est chargé de définir l'interface d'accès et de parcours des éléments
Rôle d'itérateur concret (Concrete Iterator) : Rôle d'itérateur concret Pour implémenter l'interface d'itérateur , et pour enregistrer le parcours Le courant position de ;Interface;
Conteneur en béton : Rôle de conteneur en béton Implémente l'interface pour créer un rôle d'itérateur concret - ceci Le rôle spécifique d'itérateur est lié à la structure de ce conteneur.
-
Schéma de la structure
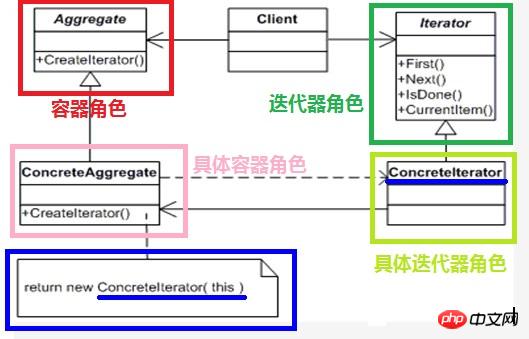
Comme on peut le voir sur la structure, 🎜>Le modèle itérateur ajoute le rôle d'itérateur entre le client et le conteneur. L'ajout du rôle d'itérateur permet d'éviter efficacement l'exposition des détails internes du conteneur et rend également la conception conforme au principe de responsabilité unique.
Il est important de noter que dans le modèle d'itérateur, le rôle d'itérateur spécifique et le rôle de conteneur spécifique sont couplés — — L'algorithme de traversée est étroitement lié aux détails internes du conteneur. Afin de libérer le programme client du dilemme du couplage avec le rôle d'itérateur spécifique et d'éviter les modifications apportées au programme client par le remplacement du rôle d'itérateur spécifique, le modèle d'itérateur fait abstraction du rôle d'itérateur spécifique, rendant le programme client plus général. et Réutilisabilité, c'est ce qu'on appelle itération polymorphe .
-
Applicabilité
1. Accéder au contenu d'un objet conteneur sans exposer sa représentation interne
2. Prend en charge plusieurs traversées d'objets conteneurs
3. Fournit une interface unifiée pour parcourir différentes structures de conteneurs (c'est-à-dire, prend en charge l'itération polymorphe).
2. Exemples
- Étant donné que les réglementations du modèle d'itérateur lui-même sont relativement souples, les implémentations spécifiques sont variées. ici Juste pour donner un exemple. Avant de donner un exemple, énumérons d'abord comment implémenter le modèle d'itérateur.
Le rôle d'itérateur définit l'interface de traversée, mais ne précise pas qui contrôle l'itération. Dans le framework Java Collection , le programme client contrôle le processus de traversée, qui est appelé itérateur externe ; pour contrôler l'itération par l'itérateur lui-même, qui est appelé itérateur interne
. Les itérateurs externes sont plus flexibles et puissants que les itérateurs internes, et la convivialité des itérateurs internes dans l'environnement du langage Java est très faible -
n'est pas disponible dans l'itérateur ; pattern Spécifier qui doit implémenter l'algorithme de traversée semble être une évidence dans le rôle d'itérateur. Parce qu'il est pratique d'utiliser différents algorithmes de traversée sur un conteneur, et il est également pratique d'appliquer un algorithme de traversée à différents conteneurs. Mais cela détruit l'encapsulation du conteneur - le rôle de conteneur doit exposer ses propres
attributs, ce qui en Java signifie exposer ses propres attributs privés à d'autres classes Alors mettons ; dans le rôle de conteneur pour l'implémenter. De cette manière, le rôle d'itérateur est élevé pour stocker uniquement une fonction permettant de parcourir la position actuelle. Mais l'algorithme de traversée est étroitement lié à un conteneur spécifique. Dans le framework Java Collection, le rôle d'itérateur spécifique fourni est la classe interne
définie dans le rôle de conteneur, protégeant ainsi l'encapsulation du conteneur. Mais en même temps, le conteneur fournit également une interface d'algorithme de traversée et vous pouvez étendre votre propre itérateur. Jetons un coup d'œil à l'implémentation des itérateurs dans Java Collection :
//迭代器角色,仅仅定义了遍历接口public interface Iterator<E> {
boolean hasNext();
E next(); void remove();
}//容器角色,这里以 List 为例,间接实现了 Iterable 接口public interface Collection<E> extends Iterable<E> {
...
Iterator<E> iterator();
...
}
public interface List<E> extends Collection<E> {}
//具体容器角色,便是实现了 List 接口的 ArrayList 等类。为了突出重点这里指罗列和迭代器相关的内容
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {……
//这个便是负责创建具体迭代器角色的工厂方法public Iterator<E> iterator() {
return new Itr();
}
//具体迭代器角色,它是以内部类的形式出来的。 AbstractList 是为了将各个具体容器角色的公共部分提取出来而存在的。
//作为内部类的具体迭代器角色
private class Itr implements Iterator<E> {
int cursor = 0;
int lastRet = -1;
//集合迭代中的一种“快速失败”机制,这种机制提供迭代过程中集合的安全性. ArrayList 中存在 modCount 属性,增删操作都会使 modCount++,
//通过两者的对比,迭代器可以快速的知道迭代过程中是否存在 list.add() 类似的操作,存在的话快速失败! int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public Object next() {
checkForComodification();
//快速失败机制 try {
Object next = get(cursor);
lastRet = cursor++;
return next;
} catch(IndexOutOfBoundsException e) {
checkForComodification();
//快速失败机制
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
checkForComodification(); //快速失败机制 try {
AbstractList.this.remove(lastRet);
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount;
//快速失败机制
}
catch(IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
} //快速失败机制 final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
//抛出异常,迭代终止
}
}-
Itération L'utilisation du modèle d'itérateur
Le programme client doit d'abord obtenir le rôle de conteneur spécifique, puis obtenir le rôle d'itérateur spécifique via le rôle de conteneur spécifique. De cette façon, des rôles d'itérateur spécifiques peuvent être utilisés pour parcourir le conteneur...
3 Situations applicables
Nous pouvons voir l'application de l'itérateur. pattern aux conteneurs Apporte les avantages suivants : 1)
Prend en charge le parcours d'un rôle de conteneur de différentes manières. L'effet sera différent selon l'implémentation (par exemple, iterator et listIterator dans List).2)
Simplification de l'interface du conteneur. Cependant, afin d'améliorer l'évolutivité de Java Collection, le conteneur fournit toujours une interface de traversée.3) 简化了遍历方式。对于对象集合的遍历,还是比较麻烦的,对于数组或者有序列表,我们尚可以通过游标来取得,但用户需要在对集合了解很清楚的前提下,自行遍历对象,但是对于 哈希表 来说,用户遍历起来就比较麻烦了。而引入了迭代器方法后,用户用起来就简单的多了。
4) 可以提供多种遍历方式。比如,对于有序列表,我们可以根据需要提供正序遍历,倒序遍历两种迭代器,用户用起来只需要得到我们实现好的迭代器,就可以方便的对集合进行遍历了。
5) 对同一个容器对象,可以同时进行多个遍历。因为遍历状态是保存在每一个迭代器对象中的。
6) 封装性良好,用户只需要得到迭代器就可以遍历,而对于遍历算法则不用去关心。
7) 在 Java Collection 中,迭代器提供一种快速失败机制 ( ArrayList是线程不安全的,在ArrayList类创建迭代器之后,除非通过迭代器自身remove或add对列表结构进行修改,否则在其他线程中以任何形式对列表进行修改,迭代器马上会抛出异常,快速失败),防止多线程下迭代的不安全操作。
由此,也可以得出迭代器模式的适用范围:
1) 访问一个容器对象的内容而无需暴露它的内部表示;
2) 支持对容器对象的多种遍历;
3) 为遍历不同的容器结构提供一个统一的接口(多态迭代)。
三、Iterator 迭代器与 Iterable 接口
1、Iterator 迭代器接口 : java.util 包
Java 提供一个专门的迭代器接口 Iterator,我们可以对某个容器实现该 Interface,来提供标准的 Java 迭代器。
-
用 Iterator 模式实现遍历集合
Iterator 模式是用于遍历集合类的标准访问方法。它可以把访问逻辑从不同类型的集合类中抽象出来,从而避免向客户端暴露集合的内部结构。
例如,如果没有使用 Iterator,遍历一个数组 的方法是使用索引:
for(int i=0; i<array.size(); i++) { ... get(i) ... }而 遍历一个HashSet 又 必须使用 while 循环或 foreach,但不能使用for循环:
while((e=e.next())!=null) { ... e.data() ... }对以上两种方法,客户端都必须事先知道集合的类型(内部结构),访问代码和集合本身是紧耦合的,无法将访问逻辑从集合类和客户端代码中分离出来,从而导致每一种集合对应一种遍历方法,客户端代码无法复用。更恐怖的是,如果以后需要把 ArrayList 更换为 LinkedList,则原来的客户端代码必须全部重写。
为解决以上问题,Iterator模式总是用同一种逻辑来遍历集合:
<p style="margin-bottom: 7px;">for(Iterator it = c.iterater(); it.hasNext(); ) { ... } <br/></p>奥秘在于 客户端自身不维护遍历集合的”指针”,所有的内部状态(如当前元素位置,是否有下一个元素)都由 Iterator 来维护,而这个 Iterator 由集合类通过工厂方法生成,因此,它知道如何遍历整个集合。而且,客户端从不直接和集合类打交道,它总是控制Iterator,向它发送”向前”,”向后”,”取当前元素”的指令,就可以间接遍历整个集合。
首先看看 java.util.Iterator 接口的定义:
public interface Iterator {
boolean hasNext();
Object next();
void remove(); // 可选操作 }依赖前两个方法就能完成遍历,典型的代码如下:
for(Iterator it = c.iterator(); it.hasNext(); ) { Object o = it.next(); // 对o的操作... }多态迭代 : 每一种集合类返回的 Iterator 具体类型可能不同,Array 可能返回 ArrayIterator,Set 可能返回 SetIterator,Tree 可能返回 TreeIterator,但是它们都实现了 Iterator 接口,因此,客户端不关心到底是哪种 Iterator,它只需要获得这个 Iterator 接口即可,这就是面向对象的威力。
2、Iterable 接口 : java.lang 包
Java 中还提供了一个 Iterable 接口,Iterable接口实现后的功能是“返回”一个迭代器 。我们常用的实现了该接口的子接口有: Collection
-
实现 Iterable 接口来实现适用于 foreach 遍历的自定义类
Iterable 接口包含一个能够产生 Iterator 的 iterator() 方法,并且 Iterable 接口被 foreach 用来在序列中实现移动。因此,实现这个接口允许对象成为 foreach 语句的目标,也就可以通过 foreach语法遍历你的底层序列。
在 JDK1.5 以前,用 Iterator 遍历序列的语法:
for(Iterator it = c.iterator(); it.hasNext(); ) { Object o = it.next(); // 对o的操作... }在 JDK1.5 以及以后的版本中,引进了 foreach,对上面的代码在语法上作了简化 ( 但是限于只读,如果需要remove,还是直接使用 Iterator ):
for(Type t : collection) { ... }3、思辨
-
为什么一定要去实现 Iterable 这个接口呢? 为什么不直接实现 Iterator接口 呢?
看一下 JDK 中的集合类,比如 List一族或者Set一族,都是实现了 Iterable 接口,但并不直接实现 Iterator 接口。仔细想一下这么做是有道理的:因为 Iterator接口的核心方法 next() 或者 hasNext() 是依赖于迭代器的当前迭代位置的。若 Collection 直接实现 Iterator 接口,势必导致集合对象中包含当前迭代位置的数据(指针)。当集合在不同方法间被传递时,由于当前迭代位置不可预置,那么 next() 方法的结果会变成不可预知。除非再为 Iterator接口 添加一个 reset() 方法,用来重置当前迭代位置。但即使这样,Collection 也只能同时存在一个当前迭代位置(不能同时多次迭代同一个序列:必须要等到当前次迭代完成并reset后,才能再一次从头迭代)。 而选择实现 Iterable 接口则不然,每次调用都会返回一个从头开始计数的迭代器(Iterator),因此,多个迭代器间是互不干扰的。
四、foreach,Iterator,for
-
foreach 和 Iterator 的关系
foreach 是 jdk5.0 新增加的一个循环结构,可以用来处理集合中的每个元素而不用考虑集合的下标。
格式如下 :
for(variable:collection){ statement; }定义一个变量用于暂存集合中的每一个元素,并执行相应的语句(块)。Collection 必须是一个数组或者是一个实现了 lterable 接口的类对象。
可以看出,使用 foreach 循环语句的优势在于更加简洁,更不容易出错,不必关心下标的起始值和终止值。forEach 不是关键字,关键字还是 for ,语句是由 iterator 实现的,它们最大的不同之处就在于 remove() 方法上。
特别地,一般调用删除和添加方法都是具体集合的方法,例如:
List list = new ArrayList(); list.add(...); list.remove(...); ...
但是,如果在循环的过程中调用集合的 remove() 方法,就会导致循环出错,因为循环过程中 list.size() 的大小变化了,就导致了错误(Iterator的快速失败机制)。 所以,如果想在循环语句中删除集合中的某个元素,就要用迭代器 iterator 的 remove() 方法,因为它的 remove() 方法不仅会删除元素,还会维护一个标志,用来记录目前是不是可删除状态,例如,你不能连续两次调用它的remove()方法,调用之前至少有一次 next() 方法的调用。因此,foreach 就是为了让用 iterator 循环访问的形式简单,写起来更方便。当然功能不太全,所以若是需要使用删除操作,那么还是要用它原来的形式。
-
使用for循环与使用迭代器iterator的对比
从效率角度分析:
采用 ArrayList 对随机访问比较快,而for循环中的get()方法,采用的即是随机访问的方法,因此在ArrayList里,for循环较快;
采用 LinkedList 则是顺序访问比较快,iterator 中的next()方法,采用的即是顺序访问的方法,因此在LinkedList里,使用iterator较快。
从数据结构角度分析:
使用 for循环 适合访问有序结构,可以根据下标快速获取指定元素;而 Iterator 适合访问无序结构,因为迭代器是通过 next() 和 Pre() 来定位的,可以访问没有顺序的集合.
使用 Iterator 的好处在于可以使用相同方式去遍历集合中元素,而不用考虑集合类的内部实现(只要它实现了 java.lang.Iterable 接口),如果使用 Iterator 来遍历集合中元素,一旦不再使用 List 转而使用 Set 来组织数据,那遍历元素的代码不用做任何修改,如果使用 for 来遍历,那所有遍历此集合的算法都得做相应调整,因为List有序,Set无序,结构不同,他们的访问算法也不一样.
五、ListIterator 简述
1、简述
ListIterator 系列表迭代器,实现了Iterator

注意,remove() 和 set(Object) 方法不是根据光标位置定义的;它们是根据对调用 next() 或 previous() 所返回的最后一个元素的操作定义的。
2、与 Iterator 区别
Iterator 和 ListIterator 主要区别有:
ListIterator 有 add()方法,可以向 List 中添加对象,而 Iterator 不能 ;
ListIterator 和 Iterator 都有 hasNext()和next()方法,可以实现顺序向后遍历。但是 ListIterator 有 hasPrevious() 和 previous() 方法,可以实现逆向(顺序向前)遍历,而 Iterator 就不可以 ;
ListIterator 可以利用 nextIndex() 和 previousIndex() 定位当前的索引位置,而 Iterator 没有此功能 ;
ListIterator 可以通过 listIterator() 方法和 listIterator(int index) 方法获得,而 Iterator 只能由 iterator() 方法获得 ;
二者都可以实现删除对象,但是ListIterator可以使用set()方法实现对象的修改。Iterator 仅能遍历,不能修改。因为ListIterator的这些功能,可以实现对LinkedList, ArrayList等List数据结构的操作。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!