
Maison >Java >javaDidacticiel >Java Collection Framework - Description spécifique à la liste
Java Collection Framework - Description spécifique à la liste

- 黄舟original
- 2017-03-14 11:45:321908parcourir
Résumé :
List est un membre important du Java Collection Framework, en particulier y compris List Interface et toutes ses classes d'implémentation. Puisque l'interface List hérite de l'interface Collection, List a toutes les opérations de Collection. Dans le même temps, comme List est un type de liste, List lui-même fournit également des méthodes qui lui conviennent. ArrayList est un tableau dynamique, qui réalise l'expansion dynamique du tableau et a une efficacité d'accès aléatoire élevée LinkedList est une liste doublement chaînée, aléatoire ; l'insertion et la Suppression sont efficaces et peuvent être utilisées comme implémentation de la file d'attente.
1. Points clés
Liste des fonctionnalités de base et framework
ArrayList : Tableau dynamique
LinkedList : BidirectionnelBoucleListe chaînée
2. >
1. Lister les opérations spéciales
La liste comprend l'List interface et toutes les classes d'implémentation de List interface (ArrayList , LinkedList, Vector, Stack) , où Vector et Stack sont obsolètes. Étant donné que l'interface List implémente l'interface Collection (comme indiqué dans le code 1), l'interface List possède toutes les méthodes courantes fournies par l'interface Collection. En même temps, étant donné que List est un type de liste, l'interface List fournit également certaines méthodes courantes. approprié pour lui-même, comme le montre le tableau 1.
// 代码 1public interface List<E> extends Collection<E> { ... }Tableau 1. Méthodes spécifiques à une liste (en prenant AbstractList comme exemple)
| Function | Introduction | Note |
|---|---|---|
| boolean addAll(int index, Collection extends E> c) | 将指定 collection 中的所有元素都插入到列表中的指定位置 | 可选操作 |
| E get(int index)| 返回列表中指定位置的元素 | 在 AbstractList 中以抽象方法 abstract public E get(int index); 存在 | AbstractList 中唯一的抽象方法 |
| E set(int index, E element) | 用指定元素替换列表中指定位置的元素 | 可选操作,set 操作是 List 的特有操作 |
| void add(int index, E element) | 在列表的指定位置插入指定元素 | 可选操作 |
| E remove(int index) | 移除列表中指定位置的元素 | 可选操作 |
| int indexOf(Object o) | 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1 | 在 AbstractList 中默认实现;在 ArrayList,LinkedList中分别重写; |
| int lastIndexOf(Object o) | 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1 | 在 AbstractList 中默认实现;在 ArrayList,LinkedList中分别重写; |
| ListIterator |
返回此列表元素的列表迭代器(按适当顺序) | 在 AbstractList 中默认实现,ArrayList,Vector和Stack使用该默认实现,LinkedList重写该实现; |
| ListIterator |
返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始 | 在 AbstractList 中默认实现,ArrayList,Vector和Stack使用该默认实现,LinkedList重写该实现; |
| List |
返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的视图 | 在 AbstractList 中默认实现(ArrayList,LinkedList使用该默认实现);之所以说是视图,是因为实际上返回的 list 是靠原来的 list 支持的; |
Spécialement, pour List :
AbstractList donne une implémentation générale de la méthode iterator() , La couche inférieure des méthodes next() et Remove() sont respectivement implémentées par les méthodes get(int index) et Remove(int index)
- Pour la méthode
subList, liste originale et sous-liste faites non- structure Les modifications sexuelles (modifications qui n'impliquent pas de changements dans la taille de la liste) s'affecteront les unes les autres Pour les modifications structurelles : Si modifications structurelles ; occurrence est la sous-liste renvoyée, alors la taille de la liste d'origine changera également (modCount et ExpectedModCount changent en même temps, le mécanisme Fast-Fail ne sera pas déclenché); Si un problème structurel se produit La liste d'origine est modifiée (à l'exclusion des modifications causées par la sous-liste renvoyée), alors le jugement l.modCount != ExpectModCount retournera TRUE, déclenchera le mécanisme Fast-Fail et lancera Conactuel ModificationException. Par conséquent, Si vous modifiez la taille de la liste d'origine après avoir appelé la sous-liste et renvoyé la sous-liste, la sous-liste générée précédemment sera invalide
- Supprimer une section d'une liste :
2. Structure de la liste
Les classes impliquées dans sont présentées :
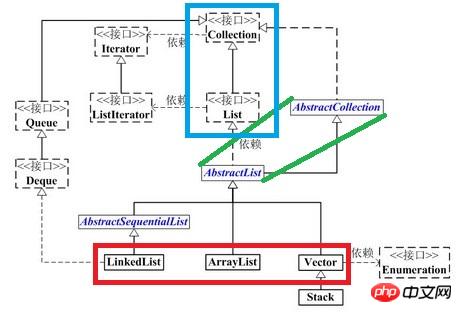
AbstractList est une
classe abstraite- , qui implémente l'interface List et hérite de AbstractCollection.
Pour l'exigence de "parcourir et accéder aux éléments dans l'ordre", vous pouvez utiliser l'itérateur de List. La classe abstraite AbstractList fournit cette implémentation lors de l'accès aux éléments à des positions spécifiques (c'est-à-dire en accédant par index) ; , L'ajout et la suppression d'éléments impliquent la relation de connexion de chaque élément de la liste, et aucune implémentation n'est fournie dans AbstractList (les types de liste sont différents et leurs méthodes d'implémentation sont également différentes, donc l'implémentation spécifique est placée dans des sous-classes) AbstractSequentialList est une classe abstraite qui hérite de AbstractList
. - AbstractSequentialList implémente "toutes les
fonctions de la liste chaînée qui exploitent la liste chaînée en fonction de la valeur de l'index" via ListIterator. De plus, ArrayList implémente « toutes les fonctions de la table de séquence pour faire fonctionner la table de séquence en fonction de la valeur de l'index » via System.arraycopy (pour terminer le mouvement des éléments ) ; ArrayList, LinkedList, Vector et Stack sont les quatre classes d'implémentation de List
-
ArrayList est une
dynamique ; tableau -
. Il est implémenté par un tableau, avec une efficacité d'accès aléatoire élevée, mais une faible efficacité d'insertion et de suppression aléatoires LinkedList est un liste doublement chaînée (Table de séquence)
. -
LinkedList a une faible efficacité d'accès aléatoire, mais une efficacité élevée d'insertion et de suppression aléatoire. Peut être utilisé comme une pile, une file d'attente ou une file d'attente à double extrémité Vector est une file d'attente vectorielle Comme ArrayList, c'est aussi un tableau dynamique. . Implémenté par le tableau
. Mais ArrayList n'est pas thread-safe -
, tandis que Vector est thread-safe Stack est une pile, qui hérite de Vector.
Ses caractéristiques sont : FILO, First In Last Out. 3. 🎜>
La liste en Java est une extension efficace du tableau. C'est une structure qui peut accueillir des éléments de tout type si des génériques ne sont pas utilisés, alors elle ne peut contenir que des éléments du. type spécifié par le générique. Par rapport aux tableaux (Les tableaux ne prennent pas en charge les génériques), la capacité de List peut être étendue dynamiquement
; Les éléments d'une liste sont "ordonnés". Le "ordonné" ici ne signifie pas trier, mais signifie que l'on peut spécifier la position d'un élément dans la collection , inclut des paires Contrôle précis de l'insertion position de chaque élément dans la liste, accéder aux éléments en fonction de leur index entier (position dans la liste) et rechercher des éléments dans la liste
- ;
Les éléments de List peuvent être répétés car il s'agit d'une structure de données ordonnée
Les collections couramment utilisées dans ListLes objets incluent : ArrayList, Vector et LinkedList, les deux premiers sont stockés sur la base de tableaux et les seconds sont stockés sur la base de listes chaînées. Parmi eux, Vector est thread-safe, et les deux autres ne le sont pas
La liste peut inclure null, même si ; les génériques sont utilisés ;
L'interface List fournit un itérateur spécial, appelé ListIterator, qui en plus de permettre les opérations normales fournies par l'interface Iterator, L'itérateur permet également l'insertion et le remplacement d'éléments, ainsi que l'accès bidirectionnel.
3. ArrayList
1. 🎜>ArrayList implémente toutes les opérations facultatives dans List et autorise tous les éléments, y compris NULL.
En plus d'implémenter l'interface List, cette classe fournit également des méthodes pour manipuler la taille de son tableau de support. ArrayList est implémenté sur la base de tableaux. Il s'agit d'un tableau dynamique dont la capacité peut augmenter automatiquement. L'attribut sizeest utilisé pour identifier le nombre d'éléments dans le conteneur, pas la taille du tableau emballé. Chaque instance d'ArrayList a une capacité, qui est la taille du tableau utilisé pour stocker les éléments de la liste, et elle est toujours au moins égale à la taille de la liste. Au fur et à mesure que des éléments sont ajoutés à l'ArrayList, sa capacité augmente automatiquement. La croissance automatique entraînera la recopie des données vers la nouvelle baie. Par conséquent, si la quantité de données peut être prédite, vous pouvez spécifier sa capacité lors de la construction de l'ArrayList. Les applications peuvent également utiliser l'opération EnsureCapacity pour augmenter la capacité d'une instance ArrayList avant d'ajouter un grand nombre d'éléments, ce qui peut réduire la quantité de réallocation incrémentielle. Notez que cette implémentation n'est pas synchrone . Si plusieurs threads accèdent à une instance ArrayList en même temps et qu'au moins un des threads la modifie structurellement (la modification structurelle fait référence à toute opération qui ajoute ou supprime un ou plusieurs éléments, ou ajuste explicitement la taille du tableau sous-jacent ; Le simple fait de définir la valeur d'un élément n'est pas une modification structurelle.) Si la liste est modifiée, elle doit être conservée synchronisée en externe.
ArrayList implémente l'interface Serialisable
, elle prend donc en charge la sérialisation et peut être transmise via la sérialisation. En lisant le code source, vous pouvez constater que le tableau intégré d'ArrayList est modifié avec le mot-clé transient pour indiquer qu'il ne sera pas sérialisé. Bien entendu, les éléments de l'ArrayList seront éventuellement sérialisés. Lors de la sérialisation/désérialisation, la méthode writeObject()/readObject() de l'ArrayList sera appelée, et les éléments de l'ArrayList (c'est-à-dire 0 . ..L'élément correspondant à l'indice size-1) et capacity size est écrit/lu à partir du flux. L'avantage est que seuls les éléments ayant une importance pratique sont enregistrés/transmis, ce qui permet d'économiser au maximum les frais de stockage, de transmission et de traitement.
ArrayList 实现了 RandomAccess 接口, 支持快速随机访问,实际上就是通过下标序号进行快速访问(于是否支持get(index)访问不同)。RandomAccess 接口是 List 实现所使用的标记接口,用来表明其支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。特别地,在对List的遍历算法中,要尽量来判断是属于 RandomAccess(如ArrayList) 还是 SequenceAccess(如LinkedList),因为适合RandomAccess List的遍历算法,用在SequenceAccess List上就差别很大,即对于实现了RandomAccess接口的类实例而言,此循环
for (int i=0, i<list.size(); i++) list.get(i);的运行速度要快于以下循环:
for (Iterator i=list.iterator(); i.hasNext(); ) i.next();所以,我们在遍历List之前,可以用 if( list instanceof RamdomAccess ) 来判断一下,选择用哪种遍历方式。
ArrayList 实现了Cloneable接口,能被克隆。Cloneable 接口里面没有任何方法,只是起一个标记作用,表明当一个类实现了该接口时,该类可以通过调用clone()方法来克隆该类的实例。
ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用 Collections.synchronizedList(List l) 函数返回一个线程安全的ArrayList类,也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
2、ArrayList在JDK中的定义
我们可以从 ArrayList 的源码看到,其包括 两个域 和 三个构造函数 , 源码如下:
private transient Object[] elementData : 支撑数组
private int size : 元素个数
public ArrayList(int initialCapacity){ … } : 给定初始容量的构造函数;
public ArrayList() { … } : Java Collection Framework 规范-默认无参的构造函数 (初始容量指定为10);
public ArrayList(Collectionc extends E>) { … } : Java Collection Framework 规范-参数为指定容器的构造函数
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{ private static final long serialVersionUID = 8683452581122892189L; /** * The array buffer into which the elements of the ArrayList are stored.(ArrayList 支撑数组) * The capacity of the ArrayList is the length of this array buffer.(ArrayList 容量的定义) */ private transient Object[] elementData; // 瞬时域 /** * The size of the ArrayList (the number of elements it contains).(ArrayList 大小的定义) */ private int size; /** * Constructs an empty list with the specified initial capacity */ public ArrayList(int initialCapacity) { // 给定初始容量的构造函数 super(); if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; // 泛型与数组不兼容 } /** * Constructs an empty list with an initial capacity of ten. */ public ArrayList() { // Java Collection Framework 规范:默认无参的构造函数 this(10); } /** * Constructs a list containing the elements of the specified * collection, in the order they are returned by the collection's * iterator. */ public ArrayList(Collection<? extends E> c) { // Java Collection Framework 规范:参数为指定容器的构造函数 elementData = c.toArray(); size = elementData.length; // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class); }
3、ArrayList 基本操作的保证
边界检查(即检查 ArrayList 的 Size):涉及到 index 的操作
// 边界检查private void RangeCheck(int index) { if (index >= size) throw new IndexOutOfBoundsException( "Index: "+index+", Size: "+size); }
调整数组容量(增加容量):向 ArrayList 中增加元素
// 调整数组容量 public void ensureCapacity(int minCapacity) { modCount++; int oldCapacity = elementData.length; if (minCapacity > oldCapacity) { Object oldData[] = elementData; int newCapacity = (oldCapacity * 3)/2 + 1; if (newCapacity < minCapacity) newCapacity = minCapacity; // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); } }向 ArrayList 中增加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度。如果超出,ArrayList 将会进行扩容,以满足添加数据的需求。数组扩容通过一个 public 方法 ensureCapacity(int minCapacity) 来实现 : 在实际添加大量元素前,我也可以使用 ensureCapacity 来手动增加 ArrayList 实例的容量,以减少递增式再分配的数量。
ArrayList 进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长为其原容量的 1.5 倍 + 1。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用 ensureCapacity 方法来手动增加ArrayList实例的容量。
在 ensureCapacity 的源代码中有这样一段代码:
Object oldData[] = elementData; //为什么要用到oldData[]
乍一看,后面并没有用到oldData,这句话显得多此一举!但是这牵涉到了一个内存管理的问题. 而且,为什么这一句还在 if 的内部? 这是跟 elementData = Arrays.copyOf(elementData, newCapacity); 这句是有关系的,在下面这句 Arrays.copyOf
的实现时,新创建了 newCapacity 大小的内存,然后把老的 elementData 放入。这样,由于旧的内存的引用是elementData, 而 elementData 指向了新的内存块,如果有一个局部变量 oldData 变量引用旧的内存块的话,在copy的过程中就会比较安全,因为这样证明这块老的内存依然有引用,分配内存的时候就不会被侵占掉。然后,在copy完成后,这个局部变量的生命周期也过去了,此时释放才是安全的。否则的话,在 copy 的时候万一新的内存或其他线程的分配内存侵占了这块老的内存,而 copy 还没有结束,这将是个严重的事情。
-
调整数组容量(减少容量):将底层数组的容量调整为当前列表保存的实际元素的大小
在使用 ArrayList 过程中,由于 elementData 的长度会被拓展,所以经常会出现 size 很小但 elementData.length 很大的情况,造成空间的浪费。 ArrayList 通过 trimToSize 方法返回一个新的数组给 elementData ,其中:元素内容保持不变,length 和size 相同。
public void trimToSize() { modCount++; int oldCapacity = elementData.length; if (size < oldCapacity) { elementData = Arrays.copyOf(elementData, size); } }
-
Fail-Fast机制
动机: 在 Java Collection 中,为了防止在某个线程在对 Collection 进行迭代时,其他线程对该 Collection 进行结构上的修改。换句话说,迭代器的快速失败行为仅用于检测代码的 bug。
本质: Fail-Fast 是 Java 集合的一种错误检测机制。
作用场景: 在使用迭代器时,Collection 的结构发生变化,抛出 ConcurrentModificationException 。当然,这并不能说明 Collection对象 已经被不同线程并发修改,因为如果单线程违反了规则,同样也有会抛出该异常。
当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会触发fail-fast机制,抛出 ConcurrentModificationException 异常。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
我们知道 fail-fast 产生的原因就在于:程序在对 collection 进行迭代时,某个线程对该 collection 在结构上对其做了修改。要想进一步了解 fail-fast 机制,我们首先要对 ConcurrentModificationException 异常有所了解。当方法检测到对象的并发修改,但不允许这种修改时就抛出该异常。同时需要注意的是,该异常不会始终指出对象已经由不同线程并发修改,如果单线程违反了规则,同样也有可能会抛出改异常。诚然,迭代器的快速失败行为无法得到保证,它不能保证一定会出现该错误,但是快速失败操作会尽最大努力抛出 ConcurrentModificationException 异常,所以,为提高此类操作的正确性而编写一个依赖于此异常的程序是错误的做法,正确做法是:ConcurrentModificationException 应该仅用于检测 bug。
下面我们以 ArrayList 为例进一步分析 fail-fast 产生的原因:
private class Itr implements Iterator<E> { int cursor; int lastRet = -1; int expectedModCount = ArrayList.this.modCount; public boolean hasNext() { return (this.cursor != ArrayList.this.size); } public E next() { checkForComodification(); /** 省略此处代码 */ } public void remove() { if (this.lastRet < 0) throw new IllegalStateException(); checkForComodification(); /** 省略此处代码 */ } final void checkForComodification() { if (ArrayList.this.modCount == this.expectedModCount) return; throw new ConcurrentModificationException(); } }从上面的源代码我们可以看出,迭代器在调用 next() 、 remove() 方法时都是调用 checkForComodification() 方法,该方法用于判断 “modCount == expectedModCount”:若不等,触发 fail-fast 机制,抛出 ConcurrentModificationException 异常。所以,要弄清楚为什么会产生 fail-fast 机制,我们就必须要弄明白 “modCount != expectedModCount” 什么时候发生,换句话说,他们的值在什么时候发生改变的。
expectedModCount 是在 Itr 中定义的:“int expectedModCount = ArrayList.this.modCount;”,所以它的值是不可能会修改的,所以会变的就是 modCount。modCount 是在 AbstractList 中定义的,为全局变量:protected transient int modCount = 0;
从 ArrayList 源码中我们可以看出,我们直接或间接的通过 RemoveRange 、 trimToSize 和 ensureCapcity(add,remove,clear) 三个方法完成对 ArrayList 结构上的修改,所以 ArrayList 实例每当调用一次上面的方法,modCount 的值就递增一次。所以,我们这里可以判断:由于expectedModCount 的值与 modCount 的改变不同步,导致两者之间不等,从而触发fail-fast机制。我们可以考虑如下场景:
有两个线程(线程A,线程B),其中线程A负责遍历list、线程B修改list。线程A在遍历list过程的某个时候(此时expectedModCount = modCount=N),线程启动,同时线程B增加一个元素,这是modCount的值发生改变(modCount + 1 = N + 1)。线程A继续遍历执行next方法时,通告checkForComodification方法发现expectedModCount = N ,而modCount = N + 1,两者不等,这时触发 fail-fast机制。
3、元素的增、改、删、查
-
元素的增和改
ArrayList 提供了 set(int index, E element) 用于修改元素,提供 add(E e)、add(int index, E element)、addAll(Collection extends E> c)、addAll(int index, Collection extends E> c) 这些方法用于添加元素。
// 用指定的元素替代此列表中指定位置上的元素,并返回以前位于该位置上的元素 public E set(int index, E element) { RangeCheck(index); E oldValue = (E) elementData[index]; elementData[index] = element; return oldValue; } // 将指定的元素添加到此列表的尾部public boolean add(E e) { ensureCapacity(size + 1); elementData[size++] = e; return true; } // 将指定的元素插入此列表中的指定位置。 // 如果当前位置有元素,则向右移动当前位于该位置的元素以及所有后续元素(将其索引加1)。 public void add(int index, E element) { if (index > size || index < 0) throw new IndexOutOfBoundsException("Index: "+index+", Size: "+size); // 如果数组长度不足,将进行扩容。 ensureCapacity(size+1); // Increments modCount!! // 将 elementData中从Index位置开始、长度为size-index的元素, // 拷贝到从下标为index+1位置开始的新的elementData数组中。 // 即将当前位于该位置的元素以及所有后续元素右移一个位置。 System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; } // 按照指定collection的迭代器所返回的元素顺序,将该collection中的所有元素添加到此列表的尾部。 public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); int numNew = a.length; ensureCapacity(size + numNew); // Increments modCount System.arraycopy(a, 0, elementData, size, numNew); size += numNew; return numNew != 0; } // 从指定的位置开始,将指定collection中的所有元素插入到此列表中。 public boolean addAll(int index, Collection<? extends E> c) { if (index > size || index < 0) throw new IndexOutOfBoundsException( "Index: " + index + ", Size: " + size); Object[] a = c.toArray(); int numNew = a.length; ensureCapacity(size + numNew); // Increments modCount int numMoved = size - index; if (numMoved > 0) System.arraycopy(elementData, index, elementData, index + numNew, numMoved); System.arraycopy(a, 0, elementData, index, numNew); size += numNew; return numNew != 0; }
元素的读取
// 返回此列表中指定位置上的元素。 public E get(int index) { RangeCheck(index); return (E) elementData[index]; }
-
元素的删除
ArrayList 共有 根据下标或者指定对象两种方式的删除功能。
romove(int index): 首先是检查范围,修改modCount,保留将要被移除的元素,将移除位置之后的元素向前挪动一个位置,将list末尾元素置空(null),返回被移除的元素。
// 移除此列表中指定位置上的元素 public E remove(int index) { RangeCheck(index); modCount++; E oldValue = (E) elementData[index]; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // Let gc do its work return oldValue; }
remove(Object o):// 移除此列表中 “首次” 出现的指定元素(如果存在)。这是因为 ArrayList 中允许存放重复的元素。 public boolean remove(Object o) { // 由于ArrayList中允许存放null,因此下面通过两种情况来分别处理。 if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { // 类似remove(int index),移除列表中指定位置上的元素。 fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; } }首先通过代码可以看到,当移除成功后返回true,否则返回false。remove(Object o)中通过遍历element寻找是否存在传入对象,一旦找到就调用 fastRemove 移除对象。
为什么找到了元素就知道了index,不通过remove(index)来移除元素呢?因为fastRemove跳过了判断边界的处理,因为找到元素就相当于确定了index不会超过边界,而且fastRemove并不返回被移除的元素。下面是fastRemove的代码,基本和remove(index)一致。下面是 fastRemove(私有的) 的源码:private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // Let gc do its work }
4、小结
关于ArrayList的源码,总结如下:
三个不同的构造方法。无参构造方法构造的ArrayList的容量默认为10; 带有Collection参数的构造方法的实现是将Collection转化为数组赋给ArrayList的实现数组elementData。
扩充容量的方法ensureCapacity。ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就设置新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量)。之后,用 Arrays.copyof() 方法将元素拷贝到新的数组。从中可以看出,当容量不够时,每次增加元素,都要将原来的元素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。
ArrayList 的实现中大量地调用了Arrays.copyof() 和 System.arraycopy()方法 。我们有必要对这两个方法的实现做下深入的了解。首先来看Arrays.copyof()方法。它有很多个重载的方法,但实现思路都是一样的,我们来看泛型版本的源码:
public static <T> T[] copyOf(T[] original, int newLength) { return (T[]) copyOf(original, newLength, original.getClass()); }很明显调用了另一个 copyof 方法,该方法有三个参数,最后一个参数指明要转换的数据的类型,其源码如下:
/** * @param original 源数组 * @param newLength 目标数组的长度 * @param newType 目标数组的类型 */public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { T[] copy = ((Object)newType == (Object)Object[].class) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; }这里可以很明显地看出,该方法实际上是在其内部又创建了一个长度为newlength的数组,调用System.arraycopy()方法,将原来数组中的元素复制到了新的数组中。
下面来看 System.arraycopy() 方法。该方法被标记了native,调用了系统的C/C++代码,在JDK中是看不到的,但在openJDK中可以看到其源码。该函数实际上最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时用该方法,以取得更高的效率;
ArrayList 基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此 查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低;
在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。
四. LinkedList
1、LinkedList 简介LinkedList 是 List接口的双向循环链表实现。LinkedList 实现了 List 中所有可选操作,并且允许所有元素(包括 null)。除了实现 List 接口外,LinkedList 为在列表的开头及结尾进行获取(get)、删除(remove)和插入(insert)元素提供了统一的访问操作,而这些操作允许LinkedList 作为Stack(栈)、Queue(队列)或Deque(双端队列:double-ended queue)进行使用。
注意,LinkedList 不是同步的。如果多个线程同时访问一个顺序表,而其中至少一个线程从结构上(结构修改指添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)修改了该列表,则它必须保持外部同步。这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedList 方法来“包装”该列表。最好在创建时完成这一操作,以防止对列表进行意外的不同步访问,如下所示:List list = Collections.synchronizedList(new LinkedList(...));
LinkedList 的 iterator 和 listIterator 方法返回的迭代器是快速失败的:在迭代器创建之后,如果从结构上对列表进行修改,除非通过迭代器自身的 remove 或 add 方法,其他任何时间任何方式的修改,都将导致ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒将来不确定的时间任意发生不确定行为的风险。
LinkedList 在Java中的定义如下:public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList 是一个继承于AbstractSequentialList的双向循环链表。它也可以被当作堆栈、队列或双端队列进行操作;
LinkedList 实现 List 接口,具有 List 的所有功能;
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用;
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆;
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输;
与 ArrayList 不同,LinkedList 没有实现 RandomAccess 接口,不支持快速随机访问。
2、LinkedList 数据结构原理
LinkedList底层的数据结构是基于双向循环链表的,且头结点中不存放数据, 如下:
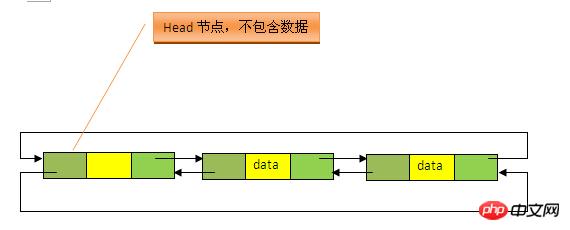
既然是双向链表,那么必定存在一种数据结构——我们可以称之为节点,节点实例保存业务数据,前一个节点的位置信息和后一个节点位置信息,如下图所示:
3、LinkedList 在JDK中的定义
A.成员变量
private transient Entry header = new Entry(null, null, null);
-
private transient int size = 0;
其中,header是双向链表的头节点,它是Entry的实例。Entry 包含三个成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。 size 是双向链表中节点实例的个数。首先,我们来了解节点类Entry:
private static class Entry<E> { E element; Entry<E> next; Entry<E> previous; Entry(E element, Entry<E> next, Entry<E> previous) { this.element = element; this.next = next; this.previous = previous; } }节点类 Entry 很简单,element存放业务数据,previous与next分别是指向前后节点的指针。
B.构造函数
- public LinkedList() { … } : Java Collection Framework 规范:空链表
- public LinkedList(Collection extends E> c) { … } : Java Collection Framework 规范:参数为指定容器的构造函数LinkedList提供了两个构造方法。第一个构造方法不接受参数,将header实例的previous和next全部指向header实例(注意,这个是一个双向循环链表,如果不是循环链表,空链表的情况应该是header节点的前一节点和后一节点均为null),这样整个链表其实就只有header一个节点,用于表示一个空的链表。执行完构造函数后,header实例自身形成一个闭环,如下图所示:
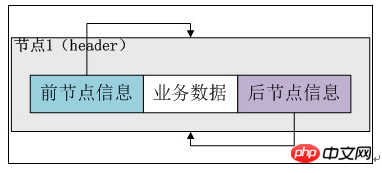
第二个构造方法接收一个Collection参数c,调用第一个构造方法构造一个空的链表,之后通过addAll将c中的元素全部添加到链表中,代码如下:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable{ private transient Entryheader = new Entry (null, null, null); private transient int size = 0; /** * Constructs an empty list. */ public LinkedList() { header.next = header.previous = header; } /** * Constructs a list containing the elements of the specified * collection, in the order they are returned by the collection's * iterator. * * @param c the collection whose elements are to be placed into this list * @throws NullPointerException if the specified collection is null */ public LinkedList(Collection c) { this(); addAll(c); }
C.成员方法
添加数据:add()
// 将元素(E)添加到LinkedList中 public boolean add(E e) { // 将节点(节点数据是e)添加到表头(header)之前。 // 即,将节点添加到双向链表的末端。 addBefore(e, header); return true; } public void add(int index, E element) { addBefore(element, (index==size ? header : entry(index))); } private Entry<E> addBefore(E e, Entry<E> entry) { Entry<E> newEntry = new Entry<E>(e, entry, entry.previous); newEntry.previous.next = newEntry; newEntry.next.previous = newEntry; size++; modCount++; return newEntry; }addBefore(E e,Entry entry)方法是个私有方法,其先通过Entry的构造方法创建e的节点newEntry(包含了将其下一个节点设置为entry,上一个节点设置为entry.previous的操作,相当于修改newEntry的“指针”),之后修改插入位置后newEntry的前一节点的next引用和后一节点的previous引用,使链表节点间的引用关系保持正确。之后修改和size大小和记录modCount,然后返回新插入的节点。
删除数据remove()
几个remove方法最终都是调用了一个私有方法:remove(Entry e),只是其他简单逻辑上的区别。下面分析remove(Entry e)方法。
private E remove(Entry<E> e) { if (e == header) throw new NoSuchElementException(); // 保留将被移除的节点e的内容 E result = e.element; // 将前一节点的next引用赋值为e的下一节点 e.previous.next = e.next; // 将e的下一节点的previous赋值为e的上一节点 e.next.previous = e.previous; // 上面两条语句的执行已经导致了无法在链表中访问到e节点,而下面解除了e节点对前后节点的引用 e.next = e.previous = null; // 将被移除的节点的内容设为null e.element = null; // 修改size大小 size--; modCount++; // 返回移除节点e的内容 return result; }整个删除操作分为三步:
-
调整相应节点的前后指针信息
e.previous.next = e.next;//预删除节点的前一节点的后指针指向预删除节点的后一个节点。
e.next.previous = e.previous;//预删除节点的后一节点的前指针指向预删除节点的前一个节点。
-
清空预删除节点
e.next = e.previous = null;
e.element = null;
-
gc完成资源回收,删除操作结束。
由以上 add 和 remove 源码可知,与 ArrayList 比较而言,LinkedList的添加、删除动作不需要移动很多数据,从而效率更高。
数据获取get()
public E get(int index) { try { return listIterator(index).next(); } catch (NoSuchElementException exc) { throw new IndexOutOfBoundsException("Index: "+index); } }该方法涉及到 listIterator 的构造,我们再看listIterator 的源码。
listIterator 源码
private class ListItr implements ListIterator<E> { // 最近一次返回的节点,也是当前持有的节点 private Entry<E> lastReturned = header; // 对下一个元素的引用 private Entry<E> next; // 下一个节点的index private int nextIndex; private int expectedModCount = modCount; // 构造方法,接收一个index参数,返回一个ListItr对象 ListItr(int index) { // 如果index小于0或大于size,抛出IndexOutOfBoundsException异常 if (index < 0 || index > size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); // 判断遍历方向 if (index < (size >> 1)) { // 相当于除法,但比除法效率高 // next赋值为第一个节点 next = header.next; // 获取指定位置的节点 for (nextIndex=0; nextIndex<index; nextIndex++) next = next.next; } else {// else中的处理和if块中的处理一致,只是遍历方向不同 next = header; for (nextIndex=size; nextIndex>index; nextIndex--) next = next.previous; } } // 根据nextIndex是否等于size判断时候还有下一个节点(也可以理解为是否遍历完了LinkedList) public boolean hasNext() { return nextIndex != size; } // 获取下一个元素 public E next() { checkForComodification(); // 如果nextIndex==size,则已经遍历完链表,即没有下一个节点了(实际上是有的,因为是循环链表,任何一个节点都会有上一个和下一个节点, 这里的没有下一个节点只是说所有节点都已经遍历完了) if (nextIndex == size) throw new NoSuchElementException(); // 设置最近一次返回的节点为next节点 lastReturned = next; // 将next“向后移动一位” next = next.next; // index计数加1 nextIndex++; // 返回lastReturned的元素 return lastReturned.element; } public boolean hasPrevious() { return nextIndex != 0; } // 返回上一个节点,和next()方法相似 public E previous() { if (nextIndex == 0) throw new NoSuchElementException(); lastReturned = next = next.previous; nextIndex--; checkForComodification(); return lastReturned.element; } public int nextIndex() { return nextIndex; } public int previousIndex() { return nextIndex-1; } // 移除当前Iterator持有的节点 public void remove() { checkForComodification(); Entry<E> lastNext = lastReturned.next; try { LinkedList.this.remove(lastReturned); } catch (NoSuchElementException e) { throw new IllegalStateException(); } if (next==lastReturned) next = lastNext; else nextIndex--; lastReturned = header; expectedModCount++; } // 修改当前节点的内容 public void set(E e) { if (lastReturned == header) throw new IllegalStateException(); checkForComodification(); lastReturned.element = e; } // 在当前持有节点后面插入新节点 public void add(E e) { checkForComodification(); // 将最近一次返回节点修改为header lastReturned = header; addBefore(e, next); nextIndex++; expectedModCount++; } // 判断expectedModCount和modCount是否一致,以确保通过ListItr的修改操作正确的反映在LinkedList中 final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }由以上 get 和 listIterator 源码可知,与 ArrayList 比较而言,LinkedList的随机访问需要从头遍历到指定位置元素,而不像ArrayList直接通过索引取值,效率更低一些。
4、小结
关于LinkedList的源码,给出几点比较重要的总结:
LinkedList 本质是一个双向循环链表,可用作List,Queue,Stack和Deque;
LinkedList 并未实现 RandomAccess 接口;
相对于ArrayList,LinkedList有更好的增删效率,更差的随机访问效率;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!