
Maison >base de données >tutoriel mysql >Analyse détaillée de la règle MyCAT (3) du cluster distribué MySQL (image et texte)
Analyse détaillée de la règle MyCAT (3) du cluster distribué MySQL (image et texte)

- 黄舟original
- 2017-03-11 14:22:131607parcourir
a déjà présenté le rôle de SCHEMA. Cet article présentera ensemble la règle et le serveur ~
Tout d'abord, il sera développé dans ce fichier. cette fois, nous extrayons uniquement certaines méthodes avec des taux d'utilisation relativement élevés. Regardons d'abord le contenu du fichier de configuration
La partie supérieure de la capture d'écran décrit la définition de la règle, et la partie inférieure montre. les règles de segmentation réelles correspondant à la règle. Ici, l'ingénieur en chef présente les quatre méthodes de segmentation suivantes~le murmure a été trompé~ - --------------- ----------------------------------- --------------- -------------------------Hash-int------- --------------- ----------------------------------- --------------- -----------
- --------------- ----------------------------------- --------------- -------------------------Hash-int------- --------------- ----------------------------------- --------------- -----------
Regardons d'abord hash-int Sous cette règle de segmentation, il y a un mapfile, ce qui signifie que la règle de segmentation est déterminée en fonction du contenu. de partition-hash-int, puis jetez un oeil à ce fichier texte
Contenu très simple, cela signifie que dans la colonne de base utilisée pour la segmentation, lorsque la valeur est 10000, elle est placée dans le premier DN (dn1), et lorsque la valeur est 10010, il est placé dans le deuxième DN (dn2)
Vous pouvez voir l'effet réel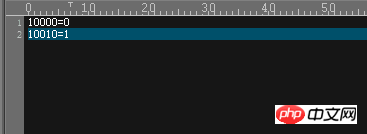
Jetez un œil au journal de débogage de MyCAT, ces deux instructions sont affectées à dn1 et dn2, et les données correspondantes sont également insérées dans la base de données
(La pelle roule dans des conditions difficiles ~), si la valeur de la colonne de référence dans les données insérées n'est pas la valeur indiquée dans ce fichier, quel sera l'effet ?
, qui convient mieux aux situations où la valeur est fixe, comme le sexe (0,1 ), province (valeur fixe, qui ne sera pas disponible à court terme) Reprenons la province japonaise ~), revendeur de canaux
ou identifiants de diverses plateformes
Et, avec une séparation par virgule, plusieurs valeurs peuvent être placées dans une partition, afin que vous puissiez formuler de manière exhaustive la stratégie de segmentation en fonction du volume réel de données/trafic/accès. Pas un guerrier tout-puissant╮(╯_ ; ╰)╭
--------------------- -------- ------------------------------------------ -------- ----------portée-longue--------------------------------- ---- --------------------------------------------------- --- La deuxième méthode de segmentation, range-long, est similaire au hash-int si vous regardez attentivement. La stratégie de segmentation est également déterminée par un fichier spécifique, il est donc préférable de jeter un œil au contenu du fichier Il ressort du contenu du fichier qu'il s'agit d'un moyen de diviser la portée, de formuler la plage de la colonne de référence, puis de placer toutes les données de cette plage sur un DN, ce la méthode est fondamentalement la même que hash-int, donc je ne prendrai pas de captures d'écran (stade tardif de la paresse, pas assez de temps !) Cette stratégie de segmentation, je pense personnellement qu'il y aura moins de scénarios d'utilisation dans les bases de données d'entreprise, car de cette segmentation La méthode doit prédéterminer la quantité globale, ce qui détermine que les données à croissance illimitée ne peuvent pas être utilisées. Après tout, il sera très gênant de changer cette stratégie de segmentation
Si vous voulez vraiment l'utiliser, je pense que. il n'est utilisé que pour augmenter automatiquement les clés primaires, puis le diviser uniformément selon un certain nombre, comme une entreprise qui corrige X éléments de données par jour (collecte de température ? Collecte de données ? et ainsi de suite), puis en créer plusieurs DN (bibliothèques) à l’avance.
Un DN est configuré pour stocker 1 000 W de données 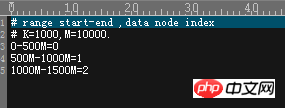
), puis à ce moment-là, il y aura un certain DN (sous-base de données) avec une pression d'E/S très élevée, tandis que plusieurs autres DN (sous-base de données) bases de données) n'ont aucune opération d'E/S. Il y aura
similaire au phénomène courant de bloc chaud/disque chaud dans la base de données, et MySQL utilise souvent des clés primaires à incrémentation automatique, il y aura donc beaucoup plus d'opportunités pour un grand nombre d'insertions "séquentielles" dans les tables MySQL
. ------------------------------------------------------ ------ ---------------------------------------mod- long- -------------------------------------------------- ------------- ---------------------------------- mod-long, du point de vue du mod, cela devrait être C'est une méthode pour prendre le reste. Jetons un coup d'œil aux informations de configuration spécifiques Atteindre les données uniformément réparties sur quatre DN (bien sûr, count & lt; le nombre de dn n'est pas un problème) Regardez l'effet réel
Regardez les journaux de débogage de mycat, voyez que MyCat est la façon de gérer Lorsque vous utilisez cette méthode de prise des nombres restants, ces quatre données sont insérées dans quatre DN (bibliothèques), et on peut voir que lorsque la séquence est insérée, les données sont réparties uniformément dans les données Multiples DN (bibliothèques). ) ci-dessus
Par rapport à la méthode de plage ci-dessus, cette stratégie de fractionnement dispersera mieux la pression de l'écriture de la base de données , mais le problème est également évident Une fois qu'une requête de plage se produit, MyCAT doit être fusionné. Résultat . , lorsque la quantité de données est élevée, le temps consommé par ce type de résultats de fusion de requêtes entre bases de données peut augmenter considérablement, en particulier lorsque l'ordre se produit.
par.
Donc ce type de stratégie de division sera plus adapté à une scène de requête à un seul point , par exemple... Je ne sais pas... Je ne sais vraiment pas, peut-être dans le banque , lors de l'interrogation des informations de compte personnel, certaines tables contenant des informations sur les utilisateurs peuvent être redondantes, puis utiliser cette méthode pour fournir des requêtes plus efficaces (après tout, la banque a un grand nombre d'utilisateurs, hein ~)
--------------------------------------------- - --------------------------------------------partition-par-long- ----- --------------------------------------------- ----- ----------------
   Être à portée -long et mod -Une stratégie de partitionnement légèrement compromise entre -long La situation de partitionnement spécifique est décrite comme suit : Avec 1024 comme unité, chaque DN stocke la quantité de données partitionLength et, partitionCount x partitionLength = 1024.
Cela semble un peu difficile à comprendre. Pour le décrire de manière vivante, prenons
partitionCount(4) x partitionLength(256) comme exemple. Sid 24=0-255 est placé dans DN1,256-511. placé en DN2, et ainsi de suite en utilisant 128 comme valeur de décalage, on a essayé d'insérer huit éléments de données à l'intérieur d'un DN~
Il convient de mentionner que cette stratégie de segmentation prend également en charge une distribution non uniforme~C'est le cas. vraiment insondable, deux photos volées ~
> Cette stratégie de division prend un compromis entre 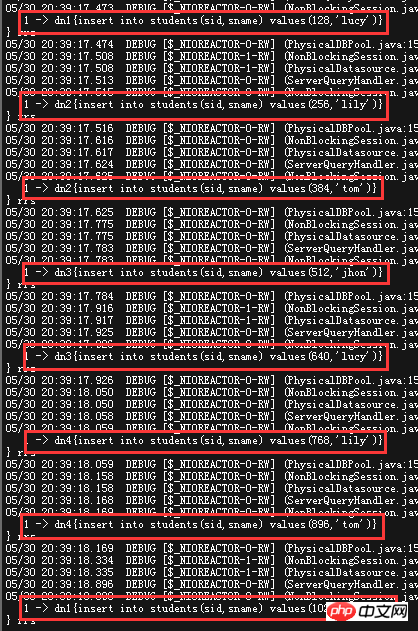
range-long et mod-long En même temps, il est relativement flexible et peut être divisé de manière non uniforme selon. Il peut en fait être appliqué dans différentes situations. Il y aura un peu plus de scénarios, ou en d'autres termes, il peut être utilisé dans de nombreux scénarios, ce qui réduit relativement le nombre de situations cross-DN et divise les données de manière égale et unique. la requête de point ne sera pas trop lente. 
----------------------------- -------------------------------------------------- ----Écrivez-le à la fin-------------------------------------------------------- ------- -----------------------------------------
En fait, MyCAT prend en charge de nombreuses méthodes de segmentation. Par exemple, les stratégies de segmentation basées sur le temps peuvent être segmentées par mois, par jour, etc. toutes les stratégies ici. Je les ai toutes mises, désolé o( ̄ヘ ̄o#)En fait, d'un point de vue personnel, il n'y a aucun problème à diviser le temps selon la stratégie de partitionnement de la base de données elle-même. Les données semestrielles et trimestrielles sont toujours les mêmes. Vous devrez interroger... PS : _(:з ∠)_Je ne suis vraiment pas paresseux...On peut dire que les points clés du sous de MyCAT -La base de données et le tableau sont essentiellement reflétés dans cette règle. Le tableau ne doit pas être divisé. La façon de diviser les données du tableau doit être décidée en fonction de l'entreprise réelle. La stratégie de division la plus appropriée doit être déterminée en fonction des caractéristiques de l'entreprise. l'entreprise~
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!