
Maison >développement back-end >Tutoriel Python >Installation et introduction de la bibliothèque Python BeautifulSoup
Installation et introduction de la bibliothèque Python BeautifulSoup

- 高洛峰original
- 2017-03-11 09:49:023120parcourir
1. Introduction
Dans les articles précédents, j'ai présenté comment analyser le code source Python pour blogs d'exploration, InfoBox Wikipédia et images, le lien de l'article est le suivant :
[Apprentissage Python] Exploration simple de la boîte de message du langage de programmation Wikipédia
[Apprentissage Python] Analyse simple des articles de blog par un robot d'exploration Web et introduction d'idées
[Apprentissage Python] Exploration simple des images dans la galerie d'images du site Web
Le code de base est le suivant :
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个url Le résultat de sortie est le suivant :
>>> CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台 登录 >>>
Le code de base pour le téléchargement d'images est le suivant :
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename) Mais la méthode ci-dessus d'analyse HTML pour explorer le contenu d'un site Web présente de nombreux inconvénients, tels que :
1. Les expressions régulières sont contraint par le code source HTML, et non Dépend de la structure plus abstraite ; de petits changements dans la structure de la page Web peuvent entraîner un arrêt du programme.
2. Le programme doit analyser le contenu en fonction du code source HTML réel. Il peut rencontrer des fonctionnalités HTML telles que des entités de caractères telles que &, et doit spécifier un traitement tel que 45a2772a6b6107b401db3c9b82c049c254bdf357c58b8a65c66d7c19c8e4d114 , hyperliens d’icônes, indices, etc. Contenu différent.
3. Les expressions régulières ne sont pas entièrement lisibles et les codes HTML et expressions de requête plus complexes deviendront compliqués.
Comme "Python Basics Tutorial (2nd Edition)" adopte deux solutions : la première consiste à utiliser le programme Tidy (bibliothèque Python) et l'analyse XHTML ; la seconde est pour utiliser la bibliothèque BeautifulSoup.
2. Installation et introduction Bibliothèque Beautiful Soup
Beautiful Soup est un analyseur HTML/XML écrit en Python , qui peut gérez bien les balises irrégulières et générez des arbres d’analyse. Il fournit des opérations simples et couramment utilisées pour naviguer, rechercher et modifier les arbres d'analyse. Cela peut considérablement économiser votre temps de programmation.
Comme le dit le livre : "Vous n'avez pas écrit ces mauvaises pages Web, vous avez simplement essayé d'en obtenir des données. Maintenant, vous vous en fichez". à quoi ressemble le code HTML, l'analyseur vous aide à y parvenir."
Adresse de téléchargement :
http://www .php.cn/
setup.py installer
 Il est recommandé de se référer au chinois pour les méthodes d'utilisation spécifiques : http://www.php.cn/
Il est recommandé de se référer au chinois pour les méthodes d'utilisation spécifiques : http://www.php.cn/
Parmi elles, l'utilisation de BeautifulSoup est brièvement expliqué, en utilisant l'exemple officiel de "Alice au pays des merveilles":
Contenu de sortie
#!/usr/bin/python # -*- coding: utf-8 -*- from bs4 import BeautifulSoup html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ #获取BeautifulSoup对象并按标准缩进格式输出 soup = BeautifulSoup(html_doc) print(soup.prettify())Sortie selon la structure de format indenté standard
Comme suit : Ce qui suit est une introduction simple et rapide à la bibliothèque BeautifulSoup : (Référence : Documentation officielle)
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
Si vous souhaitez obtenir tout le contenu textuel dans l'article, le code est le suivant :
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# http://www.php.cn/
# http://www.php.cn/
# http://www.php.cn/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>'''从文档中获取所有文字内容''' print soup.get_text() # The Dormouse's story # # The Dormouse's story # # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # # ...
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。

其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
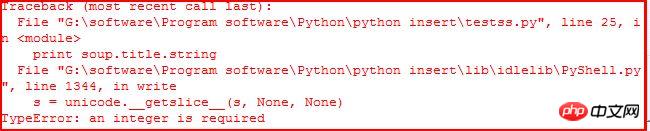
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'} 使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p> 这是获取“6924be786dcb0892a956090fd509f9a5a4b561c25d9afb9ac8dc4d70affff419The Dormouse's story0d36329ec37a2cc24d42c7229b69747a94b3e26ee717c64999d7867364b1b4a3”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>" soup = BeautifulSoup(markup) comment = soup.b.string print type(comment) # <class 'bs4.element.Comment'> print unicode(comment) # Hey, buddy. Want to buy a used parser?
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取6c04bd5ca3fcae76e30b72ad730ca86d标签中第一个a4b561c25d9afb9ac8dc4d70affff419标签。
如果想得到所有的3499910bf9dac5ae3c52d5ede7383485标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
通过tag的 .children 生成器,可以对tag的子节点进行循环:
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,93f0f5c25f18dab9d176bd4f6de5d30e标签是b2386ffb911b14667cb8f0f91ea547a7标签的父节点,换句话就是增加一层标签。
注意:文档的顶层节点比如100db36a723c770d327fc0aef2ce13b1的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。
兄弟节点:因为a4b561c25d9afb9ac8dc4d70affff419标签和f8331b8a817c28418a431fbe6e724755标签是同一层:他们是同一个元素的子节点,所以a4b561c25d9afb9ac8dc4d70affff419和f8331b8a817c28418a431fbe6e724755可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。
在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。a4b561c25d9afb9ac8dc4d70affff419标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为a4b561c25d9afb9ac8dc4d70affff419标签在同级节点中是第一个。同理f8331b8a817c28418a431fbe6e724755标签有.previous_sibling 属性,却没有.next_sibling 属性:
介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。
(By:Eastmount 2015-3-25 下午6点
http://www.php.cn/)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!